Clear Sky Science · zh
多代理大型语言模型框架用于自动评估临床 AI 分诊工具的性能
这对病人护理为何重要
医院越来越多地采用人工智能工具来标记医学影像中的紧急情况,例如脑内出血。但这些工具可能会在不知不觉中逐渐失去准确性,许多医疗系统也缺乏简便的方法来检查它们在本院病人上的表现是否仍然可靠。本研究探讨了一组基于语言的 AI 系统是否能够自动读取放射学报告,并在后台持续监控商业化脑出血分诊工具。
检查医疗 AI 的挑战
一旦 AI 工具在医院部署,它就面临一个不断变化的环境:新的扫描仪、更新的影像协议以及患者群体的变化都可能侵蚀其性能。厂商通常只提供有限的监测,医院则需负责发现不公平偏差和性能漂移。人工审查成千上万张脑部扫描或病历以验证 AI 工具的正确率,对放射科医师来说耗时过高。作为实用的捷径,许多团队把最终的放射学报告视为图像上真实发现的最佳可用摘要,但即便如此,仍然需要有人或某种系统来读取这些报告。
利用语言型 AI 读取放射学报告
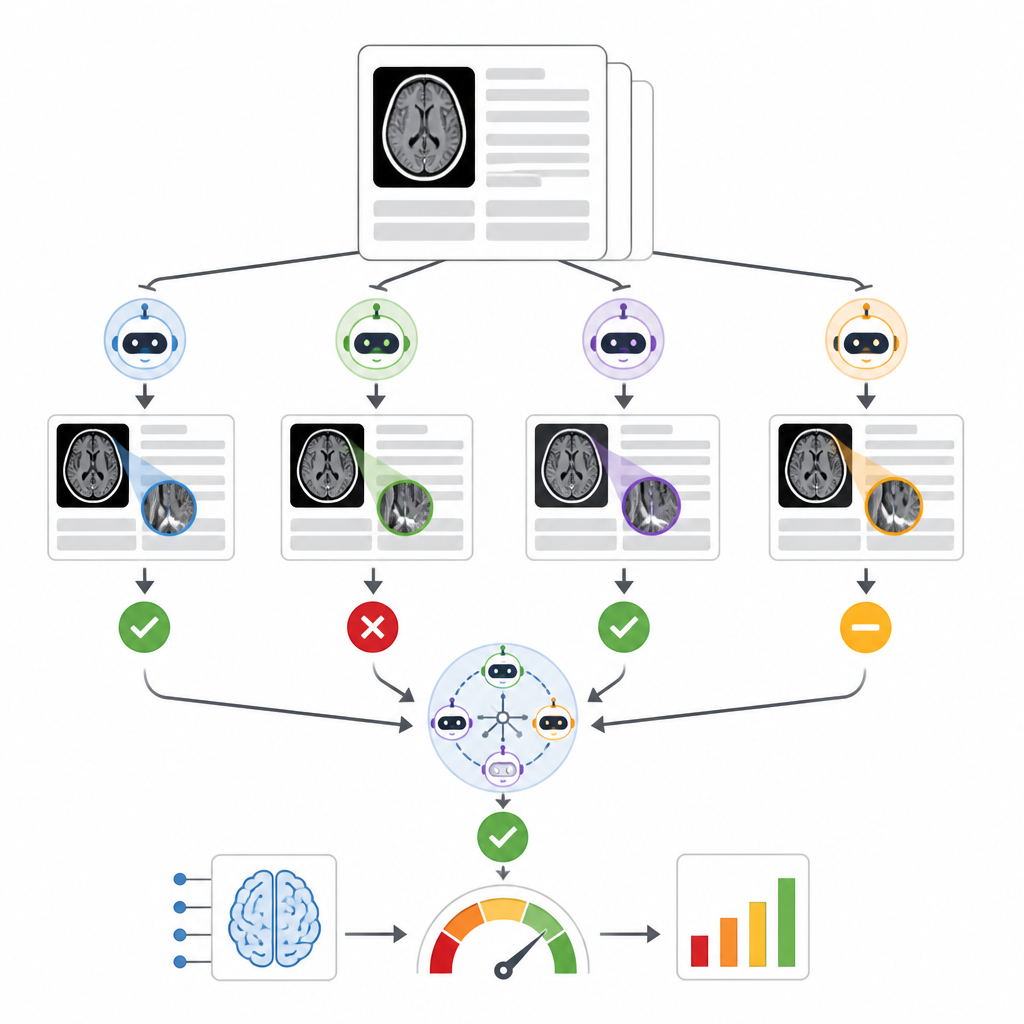
作者构建了一个名为 RADAR 的系统,用于监听一款商业颅内出血分诊工具在 14 家医院近 3 万例无对比头部 CT 扫描上的结果。对于每次检查,RADAR 随后获取最终放射学报告并只提取结论部分,即放射科医师给出的要点。将这段简短文本连同同样精心编写的指令,发送给八个在本地运行的开源语言模型以及一份医院内托管的安全版 GPT-4o。每个模型仅决定该报告是否清楚地描述了急性脑出血,研究者还基于模型多数一致性计算一个共识答案。
AI 阅读器与专家的一致性如何
为评估准确性,两名有经验的放射科医师手工审查了 1,726 条报告结论,特别关注原始分诊 AI 与语言模型共识出现分歧的病例。把含糊或不完整的报告搁置后,剩下 1,490 例明确的阳性或阴性脑出血样本。在九个语言模型中,表现差异很大。一个小模型表现挣扎,几乎与随机无异,而一个非常大的模型 Llama3.3:70b 和 GPT-4o 展现出最强与人工评审相匹配的能力,在检测真实出血和避免误报方面均有稳健分数。当作者比较不同的模型组合方式时,他们发现由表现最佳的模型、全部九个模型构成的集成,或由八个本地模型达成共识的方案,均产生了相似且稳健的对该商业分诊工具的评估,并且都比单靠 GPT-4o 更一致。
处理临床文本中的现实混乱
该研究凸显了临床报告的混乱现实。约 14% 的审查报告使用了过于模糊或自相矛盾的语言,使人或语言模型都无法有把握地确定是否存在新近脑出血。有些错误来源于提示词未明确区分颅内出血与轻微头皮肿胀,表明即便是简单的问题,如果措辞不当并缺乏持续检查,也会让自动阅读系统出错。大型模型总体上表现较好,但一些中等规模的开源模型表现几近可比,这表明模型设计和提示工程与模型规模同样重要。
这对未来医院 AI 有何意义
作者总结认为,一小组协作的语言模型可以像专家评审小组一样工作,为医院提供一种切实可行、低成本且与厂商无关的方法来监控输出简单是/否决策的影像 AI 工具。通过持续读取常规放射学报告,此类模型集成可以帮助检测分诊工具性能何时发生漂移,支持对跨站点或不同扫描仪可能存在的偏差进行调查,并减少繁重人工审计的需求。对医疗系统而言,这种方法为将现有报告文本转变为对临床 AI 的持续安全网提供了一条可行途径。
引用: Flanders, A.E., Peng, Y., Prevedello, L. et al. A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool. npj Health Syst. 3, 35 (2026). https://doi.org/10.1038/s44401-026-00100-4
关键词: 临床 AI 监测, 放射学报告, 大型语言模型, 颅内出血, AI 性能漂移