Clear Sky Science · ru
Многоагентная платформа на базе больших языковых моделей для автоматической оценки работы клинического инструмента триажа ИИ
Почему это важно для ухода за пациентами
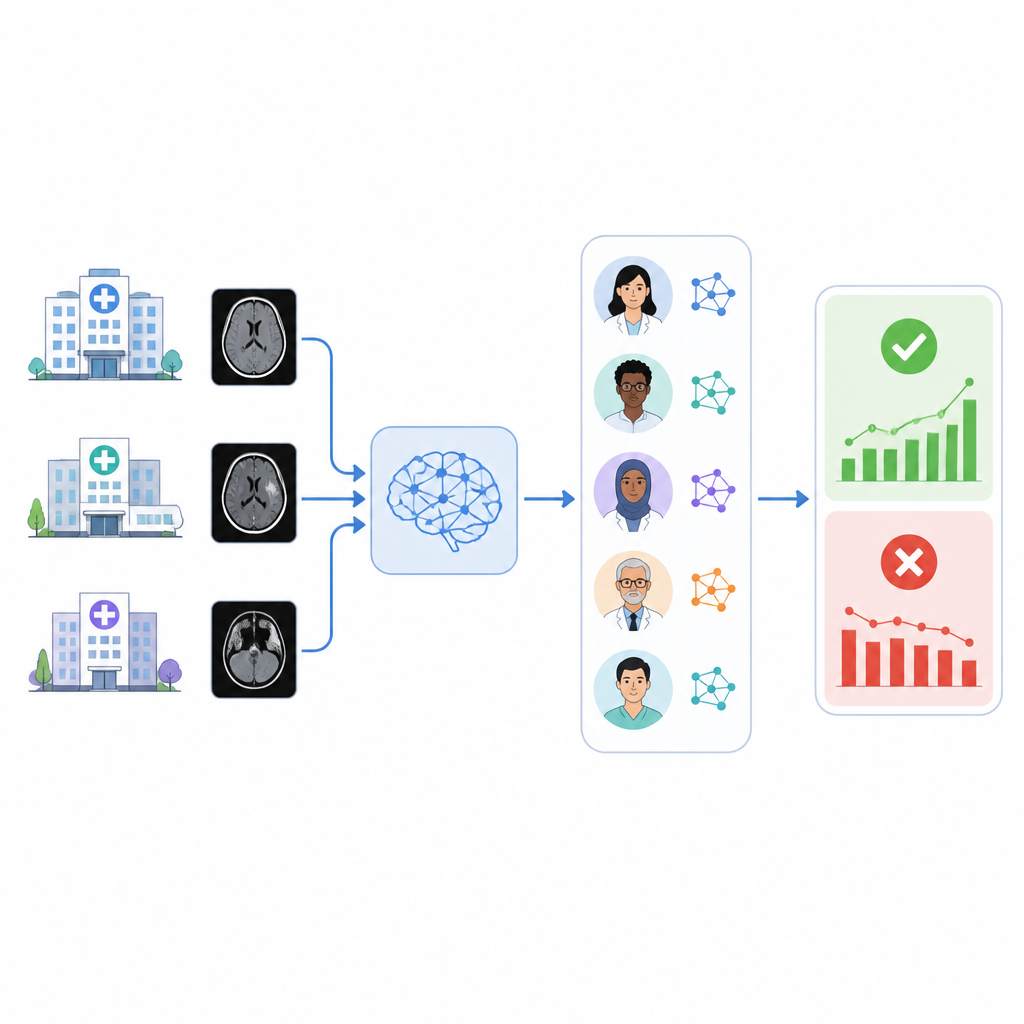
Больницы всё чаще используют инструменты искусственного интеллекта для пометки неотложных состояний на медицинских изображениях, например кровоизлияний в мозг. Но эти инструменты могут постепенно терять точность, и во многих системах здравоохранения нет простого способа проверить, по‑прежнему ли они корректно работают на собственных пациентах. В этом исследовании изучают, может ли команда языковых ИИ автоматически читать радиологические отчёты и в фоновом режиме следить за коммерческим инструментом триажа при кровоизлиянии в мозг.
Проблема проверки медицинского ИИ
После внедрения в больнице ИИ сталкивается с меняющимся миром: новые томографы, обновлённые протоколы визуализации и изменение состава пациентов могут со временем снижать его производительность. Поставщики часто предлагают лишь ограниченные средства мониторинга, и на больницах лежит ответственность за обнаружение несправедливых смещений и дрейфа производительности. Ручная проверка тысяч сканов или медицинских записей, чтобы установить, как часто инструмент ИИ оказывается прав, занимает слишком много времени для радиологов. В качестве практического упрощения многие группы считают финальный радиологический отчёт лучшим доступным резюме того, что действительно было найдено на изображениях, но даже в этом случае кто‑то или что‑то должно прочитать эти отчёты.
Использование языковых ИИ для чтения радиологических отчётов
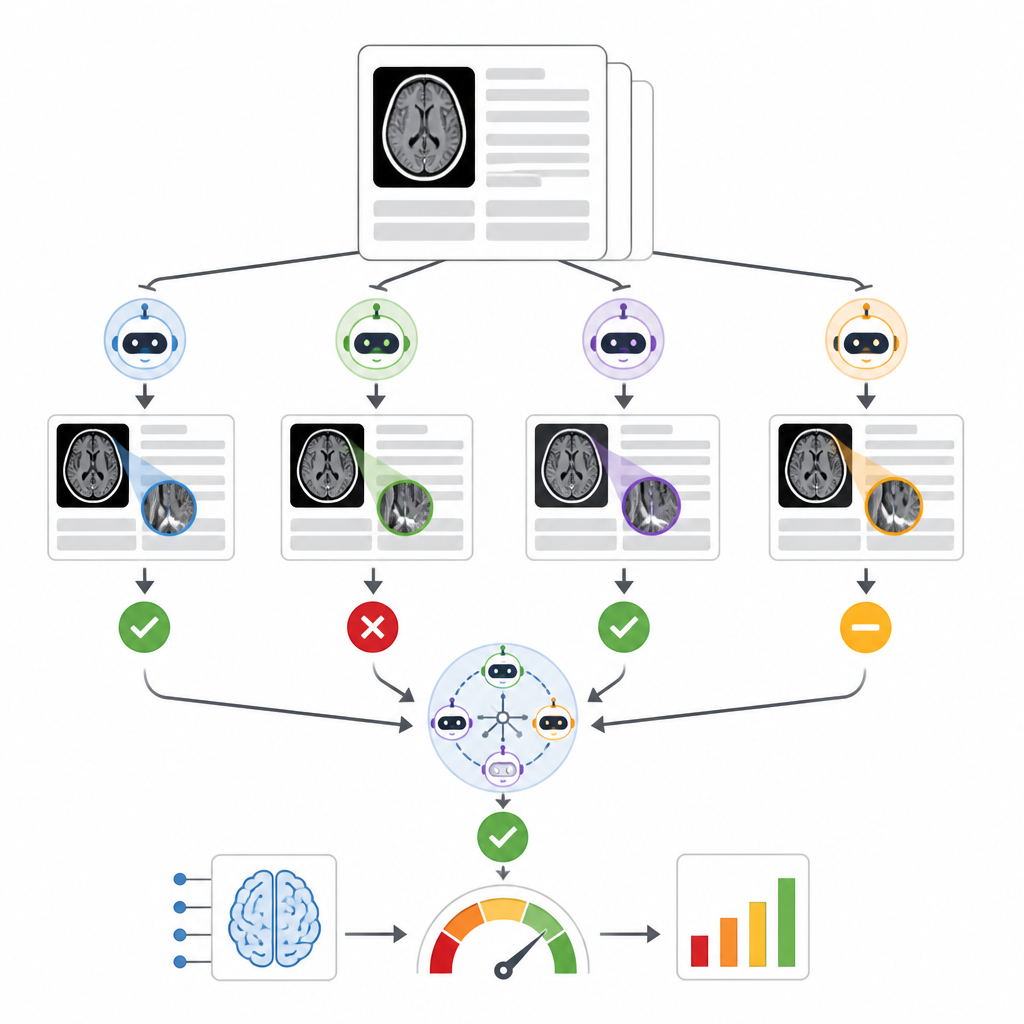
Авторы разработали систему под названием RADAR, которая отслеживает результаты коммерческого инструмента триажа внутричерепного кровоизлияния, применённого почти к 30 000 нативных КТ‑исследований головы из 14 больниц. Для каждого исследования RADAR позже извлекает финальный радиологический отчёт и берёт только секцию «Впечатление» (impression), где радиолог формулирует итог. Этот короткий текст отправляется с одинаковыми тщательно подобранными инструкциями восьми открытым языковым моделям, работающим локально, а также защищённой версии GPT‑4o, размещённой в инфраструктуре больницы. Каждая модель просто решает, явно ли в отчёте описано острое кровоизлияние в мозг или нет, а исследователи также получают консенсусный ответ на основе большинства голосов моделей.
Насколько согласовывались ИИ‑читатели с экспертами
Чтобы оценить точность, двое опытных радиологов вручную проверили 1 726 секций «Впечатление», особенно обращая внимание на случаи, где исходный триаж‑ИИ и консенсус языковых моделей расходились. Неоднозначные или неполные отчёты отложили в сторону, оставив 1 490 явных положительных или отрицательных случаев кровоизлияния. Среди девяти языковых моделей производительность сильно варьировала. Небольшая модель справлялась плохо и была не лучше случайного угадывания, тогда как очень крупная модель Llama3.3:70b и GPT‑4o показали наилучшую способность совпадать с человеческой проверкой, с уверенными показателями как по обнаружению реальных кровоизлияний, так и по избеганию ложных срабатываний. При сравнении разных способов объединения моделей авторы обнаружили, что ансамбли, составленные из лучших моделей, из всех девяти моделей или из восьми локальных моделей по принципу консенсуса, давали схожие и надёжные оценки коммерческого инструмента триажа, и все они были более последовательны, чем опора только на GPT‑4o.
Как учитывать реальную неаккуратность клинических текстов
Исследование подчёркивает запутанную реальность клинической отчётности. Около 14 процентов проанализированных отчётов содержали формулировки, которые были слишком расплывчатыми или противоречивыми, чтобы люди или языковые модели могли с уверенностью сказать, присутствует ли свежее кровоизлияние. Некоторые ошибки возникали, когда запрос (prompt) чётко не разделял кровотечение внутри черепа и незначительный отёк кожи головы, что показывает: даже простые вопросы могут сбивать автоматических читателей без аккуратной формулировки и постоянной валидации. Крупные модели в целом показывали лучшие результаты, но некоторые средние открытые модели работали почти так же хорошо, что говорит о том, что архитектура и настройка промптов важны не меньше, чем сама масштабность.
Что это значит для будущих ИИ в больницах
Авторы делают вывод, что небольшая команда сотрудничающих языковых моделей может выступать как панель экспертных рецензентов, предлагая больницам практичный, недорогой и независимый от вендора способ отслеживать инструменты визуализации ИИ, которые выдают простые решения «да» или «нет». Постоянно читая рутинные радиологические отчёты, такие ансамбли могут помочь выявлять дрейф производительности триаж‑инструмента, поддерживать расследования возможной предвзятости между площадками или томографами и сокращать необходимость утомительных ручных аудитов. Для систем здравоохранения этот подход даёт возможность превратить уже существующие тексты отчётов в постоянно действующую страховку для клинического ИИ.
Цитирование: Flanders, A.E., Peng, Y., Prevedello, L. et al. A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool. npj Health Syst. 3, 35 (2026). https://doi.org/10.1038/s44401-026-00100-4
Ключевые слова: мониторинг клинического ИИ, радиологические отчёты, большие языковые модели, внутричерепное кровоизлияние, дрейф производительности ИИ