Clear Sky Science · de
Ein Multi-Agenten-Framework großer Sprachmodelle zur automatischen Bewertung der Leistung eines klinischen KI-Triage-Tools
Warum das für die Patientenversorgung wichtig ist
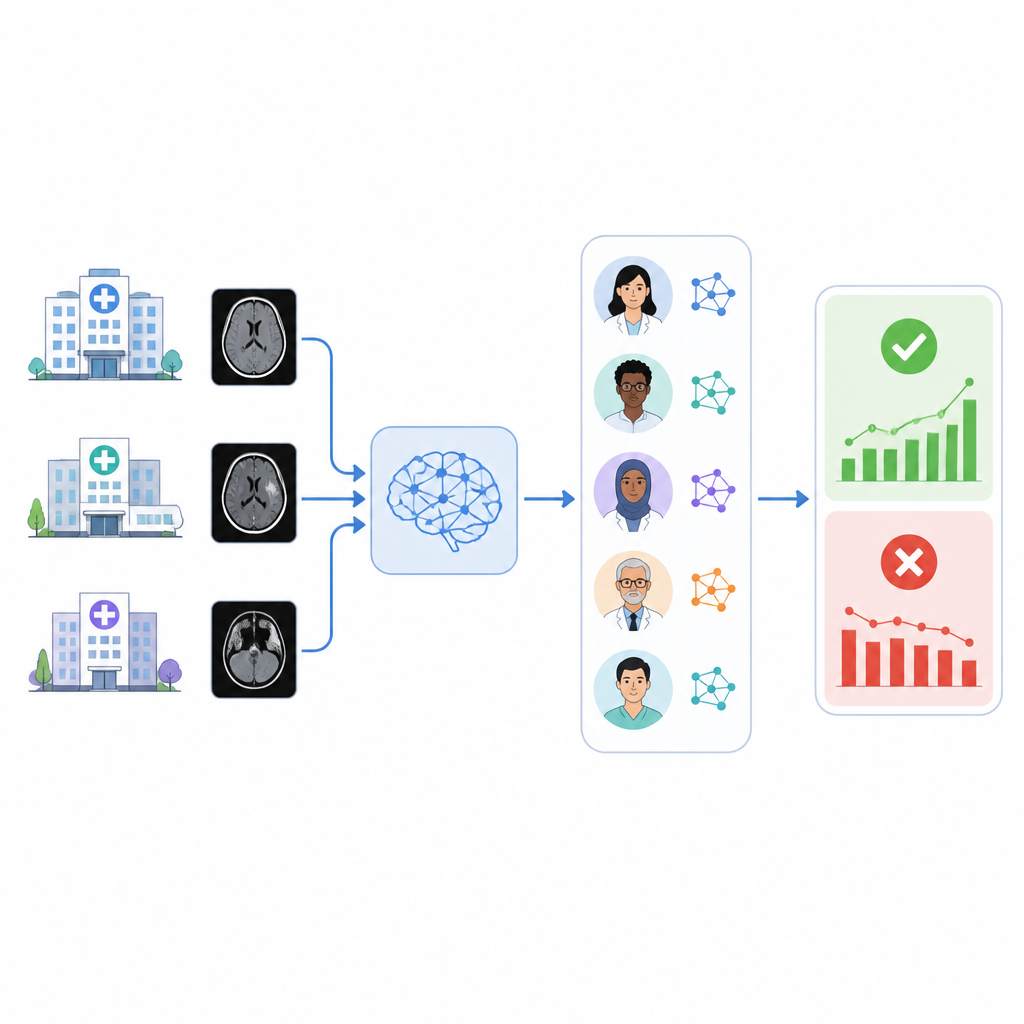
Kliniken setzen zunehmend auf KI‑Werkzeuge, um dringliche Befunde auf medizinischen Bildgebungen zu markieren, etwa Blutungen im Gehirn. Diese Werkzeuge können jedoch schleichend an Genauigkeit verlieren, und viele Gesundheitssysteme haben keine einfache Möglichkeit zu prüfen, ob sie bei den eigenen Patienten weiterhin zuverlässig arbeiten. In dieser Studie wird untersucht, ob ein Team sprachbasierter KI‑Systeme automatische Radiologiebefunde lesen und im Hintergrund ein kommerzielles Triage‑Tool für Hirnblutungen überwachen kann.
Die Herausforderung der Kontrolle medizinischer KI
Sobald ein KI‑Tool in einem Krankenhaus eingesetzt ist, trifft es auf eine sich verändernde Umgebung: neue Scanner, aktualisierte Protokolle und schwankende Patientengruppen können die Leistung beeinträchtigen. Anbieter bieten oft nur begrenzte Überwachung, sodass Krankenhäuser selbst für das Erkennen von Verzerrungen und Leistungsverlust verantwortlich sind. Tausende von Hirnscans oder Patientenakten manuell zu prüfen, um zu verifizieren, wie oft ein KI‑Tool richtig liegt, ist für Radiologen zeitlich kaum leistbar. Als praktischen Kompromiss betrachten viele Gruppen den abschließenden Radiologiebericht als die bestmögliche Zusammenfassung dessen, was auf den Bildern tatsächlich gefunden wurde — doch auch diese Berichte müssen letztlich von jemandem oder etwas gelesen werden.
Sprach‑KIs zum Lesen von Radiologiebefunden einsetzen
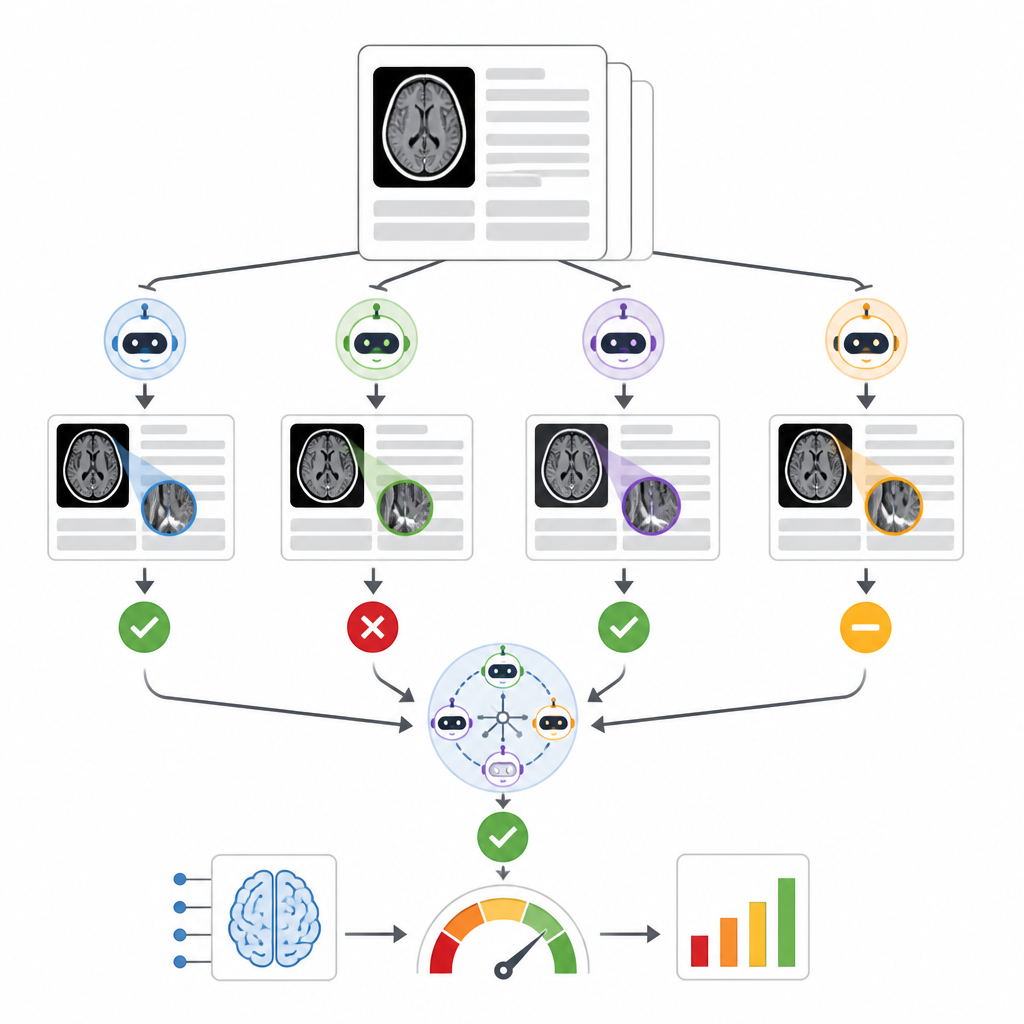
Die Autorinnen und Autoren entwickelten ein System namens RADAR, das die Ergebnisse eines kommerziellen Triage‑Tools für intrakranielle Blutungen überwacht, das auf fast 30.000 nicht‑kontrastierten Kopf‑CT‑Untersuchungen aus 14 Krankenhäusern angewendet wurde. Für jede Untersuchung zieht RADAR nachträglich den finalen Radiologiebericht und extrahiert nur den Abschnitt „Impression“, in dem der Radiologe das Fazit zieht. Dieser kurze Text wird mit denselben sorgfältig formulierten Anweisungen an acht lokal laufende Open‑Source‑Sprachmodelle sowie an eine sicher im Krankenhaus gehostete Version von GPT‑4o gesendet. Jedes Modell entscheidet dabei einfach, ob der Bericht eine akute Hirnblutung eindeutig beschreibt oder nicht; zusätzlich berechnen die Forschenden eine Konsensus‑Antwort basierend auf der Mehrheitsmeinung der Modelle.
Wie gut die KI‑Leser mit Expertinnen und Experten übereinstimmten
Zur Beurteilung der Genauigkeit prüften zwei erfahrene Radiologen manuell 1.726 Befund‑Impressionen, mit besonderem Fokus auf Fälle, in denen das ursprüngliche Triage‑KI‑System und der Konsens der Sprachmodelle uneins waren. Mehrdeutige oder unvollständige Berichte wurden ausgesondert, sodass 1.490 eindeutige positive oder negative Befunde für Hirnblutungen verblieben. Bei den neun Sprachmodellen schwankte die Leistung stark. Ein kleines Modell hatte Schwierigkeiten und war kaum besser als Zufall, während ein sehr großes Modell (Llama3.3:70b) und GPT‑4o die stärkste Übereinstimmung mit der menschlichen Begutachtung zeigten und solide Werte sowohl beim Erkennen echter Blutungen als auch beim Vermeiden von Fehlalarmen erreichten. Beim Vergleich unterschiedlicher Methoden zur Kombination der Modelle zeigte sich, dass Ensembles, die aus den besten Modellen, aus allen neun Modellen oder aus den acht lokalen Modellen im Konsens gebildet wurden, ähnliche und robuste Bewertungen des kommerziellen Triage‑Tools lieferten und alle konsistenter waren als die alleinige Verwendung von GPT‑4o.
Umgang mit der realen Unordnung klinischer Texte
Die Studie macht die unordentliche Realität klinischer Berichte deutlich. Etwa 14 Prozent der untersuchten Berichte verwendeten eine Sprache, die zu vage war oder widersprüchliche Angaben enthielt, sodass weder Menschen noch Sprachmodelle mit Vertrauen sagen konnten, ob eine frische Hirnblutung vorlag. Einige Fehler entstanden, wenn die Eingabeaufforderung nicht klar zwischen innerer Schädelblutung und geringer Kopfhautschwellung unterschied — ein Hinweis darauf, dass selbst einfache Fragen automatischen Lesern ohne präzise Formulierung und fortlaufende Kontrollen Probleme bereiten können. Größere Modelle schnitten im Allgemeinen besser ab, doch einige mittelgroße Open‑Source‑Modelle kamen fast an diese Leistung heran, was darauf hindeutet, dass Design und Prompt‑Engineering ebenso wichtig sind wie die reine Modellgröße.
Was das für künftige KI in Krankenhäusern bedeutet
Die Autorinnen und Autoren schließen, dass ein kleines Team kooperierender Sprachmodelle wie ein Gremium von Expertengutachtern wirken kann und Kliniken eine praktische, kostengünstige und anbieterneutrale Möglichkeit bietet, Bildgebungs‑KI‑Tools zu überwachen, die einfache Ja‑/Nein‑Ergebnisse liefern. Indem solche Ensembles routinemäßig Radiologieberichte lesen, können sie helfen zu erkennen, wann die Leistung eines Triage‑Tools driftet, Untersuchungen zu möglichen Verzerrungen über Standorte oder Scanner hinweg unterstützen und den Bedarf an mühsamen manuellen Audits verringern. Für Gesundheitssysteme bietet dieser Ansatz eine Möglichkeit, vorhandenen Berichtstext in ein permanentes Sicherheitsnetz für klinische KI zu verwandeln.
Zitation: Flanders, A.E., Peng, Y., Prevedello, L. et al. A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool. npj Health Syst. 3, 35 (2026). https://doi.org/10.1038/s44401-026-00100-4
Schlüsselwörter: Überwachung klinischer KI, Radiologieberichte, große Sprachmodelle, intrakranielle Blutung, Leistungsverlust von KI