Clear Sky Science · it
Un framework multi-agente basato su grandi modelli linguistici per valutare automaticamente le prestazioni di uno strumento clinico di triage AI
Perché è importante per la cura dei pazienti
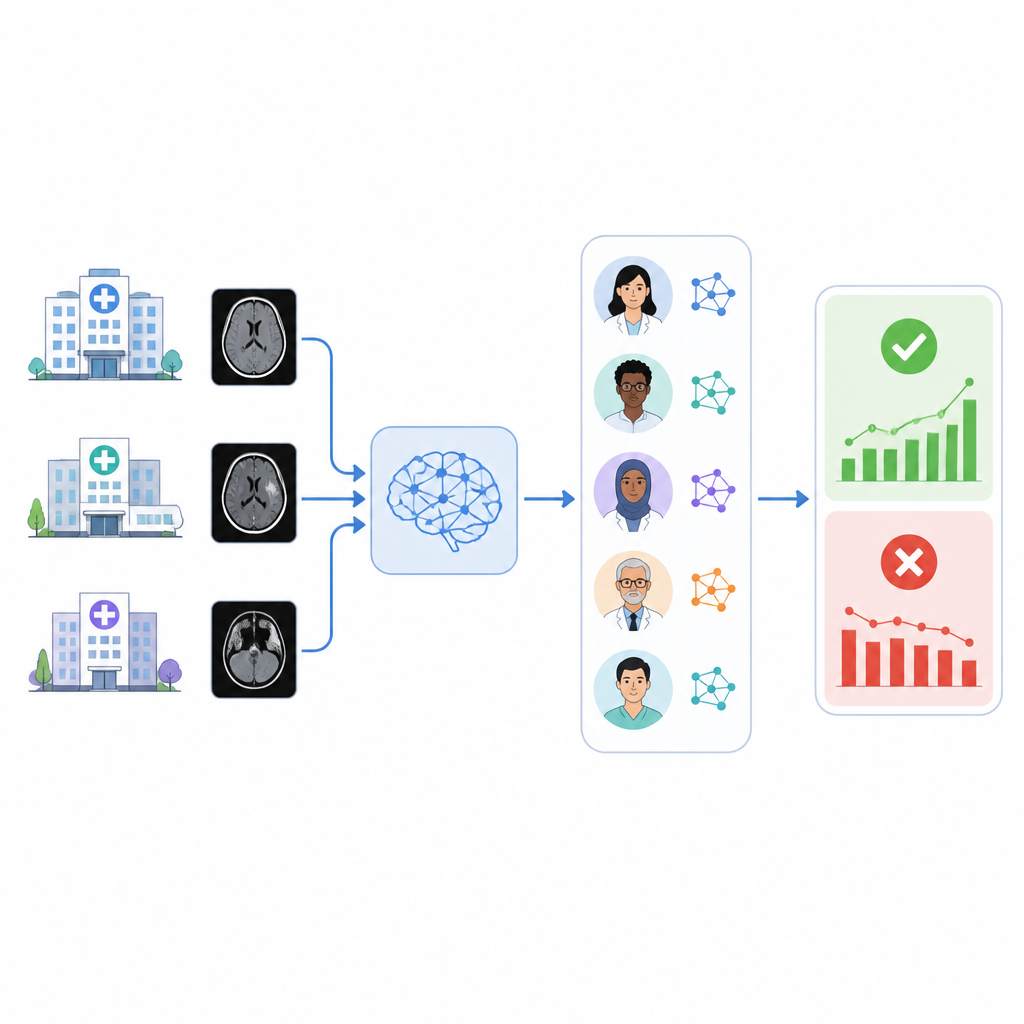
Gli ospedali si affidano sempre più a strumenti di intelligenza artificiale per segnalare condizioni urgenti nelle immagini mediche, come le emorragie cerebrali. Ma questi sistemi possono perdere accuratezza nel tempo e molte strutture sanitarie non hanno un modo semplice per verificare se funzionano ancora correttamente sui propri pazienti. Questo studio esplora se un gruppo di sistemi IA basati sul linguaggio possa leggere automaticamente i referti radiologici e monitorare in background uno strumento commerciale di triage per emorragia cerebrale.
La sfida nel controllare le IA mediche
Una volta installato in ospedale, uno strumento di IA si trova a operare in un mondo che cambia: nuovi tomografi, protocolli di imaging aggiornati e popolazioni di pazienti diverse possono tutti erodere le prestazioni. I fornitori spesso offrono monitoraggi limitati, e gli ospedali sono responsabili di rilevare bias ingiusti e il degrado delle prestazioni. Riesaminare manualmente migliaia di esami o cartelle cliniche per verificare quante volte l’IA ha ragione richiede troppo tempo per i radiologi. Come scorciatoia pratica, molti gruppi considerano il referto radiologico finale la migliore sintesi disponibile di ciò che è stato effettivamente trovato sulle immagini, ma anche in quel caso qualcuno o qualcosa deve leggere quei referti.
Usare IA linguistiche per leggere i referti radiologici
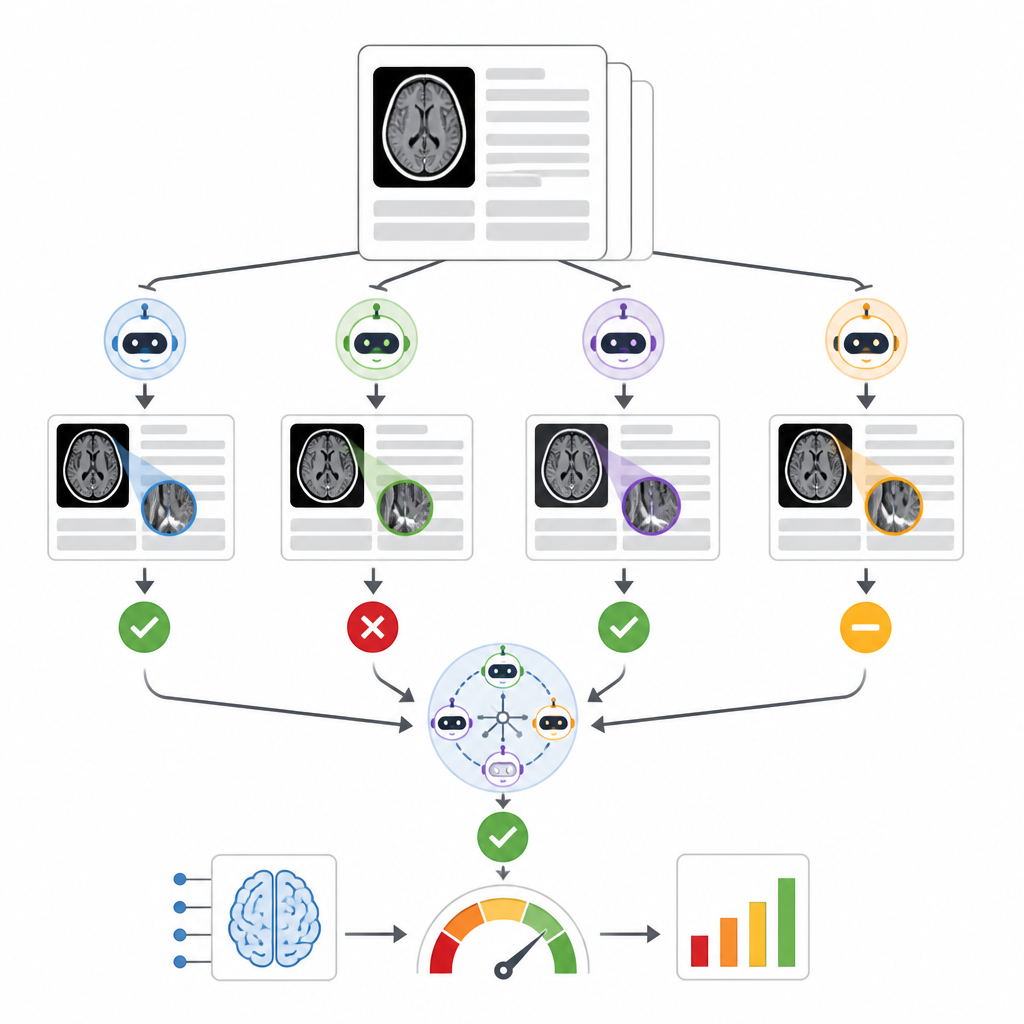
Gli autori hanno costruito un sistema chiamato RADAR che rileva i risultati di uno strumento commerciale di triage per emorragia intracranica usato su quasi 30.000 TAC craniche non contrastate provenienti da 14 ospedali. Per ogni esame, RADAR recupera successivamente il referto radiologico finale ed estrae solo la sezione “impression” (conclusione), dove il radiologo dà il verdetto. Quel breve testo viene inviato, con le stesse istruzioni accuratamente scritte, a otto modelli linguistici open-source eseguiti localmente più una versione sicura ospitata in rete di GPT-4o. Ogni modello decide semplicemente se il referto descrive chiaramente un’emorragia cerebrale acuta o no, e i ricercatori calcolano anche una risposta di consenso basata sulla maggioranza tra i modelli.
Quanto i lettori IA hanno concordato con gli esperti
Per valutare l’accuratezza, due radiologi esperti hanno rivisto manualmente 1.726 impressioni di referti, concentrandosi in particolare sui casi in cui lo strumento di triage originale e il consenso dei modelli linguistici non concordavano. I referti ambigui o incompleti sono stati messi da parte, lasciando 1.490 positivi o negativi chiari per emorragia cerebrale. Tra i nove modelli linguistici, le prestazioni variavano ampiamente. Un modello piccolo ha faticato ed era sostanzialmente al livello del caso, mentre un modello molto grande, Llama3.3:70b, e GPT-4o hanno mostrato la migliore capacità di allinearsi alla revisione umana, con punteggi solidi sia nel rilevare emorragie reali sia nell’evitare falsi allarmi. Quando gli autori hanno confrontato diversi modi di combinare i modelli, hanno scoperto che ensemble costruiti sui migliori performer, su tutti e nove i modelli o sugli otto modelli locali in consenso producevano valutazioni simili e robuste dello strumento commerciale di triage, e tutte erano più coerenti rispetto all’affidarsi solo a GPT-4o.
Gestire la disordine del mondo reale nel testo clinico
Lo studio mette in luce la realtà disordinata del refertare clinico. Circa il 14 percento dei referti esaminati utilizzava un linguaggio troppo vago o conflittuale perché sia gli umani sia i modelli linguistici potessero affermare con fiducia la presenza di una nuova emorragia cerebrale. Alcuni errori sono emersi quando il prompt non distingueva chiaramente il sanguinamento intracranico da un modesto gonfiore del cuoio capelluto, mostrando che anche domande apparentemente semplici possono confondere i lettori automatizzati senza una formulazione attenta e controlli continui. I modelli più grandi tendevano a ottenere migliori prestazioni complessive, ma alcuni modelli open-source di dimensioni medie si sono comportati quasi altrettanto bene, suggerendo che il design e l’ingegneria del prompt contano tanto quanto la sola dimensione del modello.
Cosa significa per l’IA ospedaliera futura
Gli autori concludono che un piccolo team di modelli linguistici collaborativi può agire come una commissione di revisori esperti, offrendo agli ospedali un modo pratico, a basso costo e indipendente dal fornitore per monitorare gli strumenti di imaging AI che producono decisioni semplici sì/no. Leggendo continuamente i referti radiologici di routine, tali ensemble possono aiutare a rilevare quando le prestazioni di uno strumento di triage degradano, supportare le indagini su possibili bias tra sedi o tomografi e ridurre la necessità di audit manuali laboriosi. Per i sistemi sanitari, questo approccio offre un modo per trasformare il testo dei referti esistenti in una rete di sicurezza sempre attiva per l’IA clinica.
Citazione: Flanders, A.E., Peng, Y., Prevedello, L. et al. A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool. npj Health Syst. 3, 35 (2026). https://doi.org/10.1038/s44401-026-00100-4
Parole chiave: monitoraggio IA clinica, referti radiologici, grandi modelli linguistici, emorragia intracranica, degrado delle prestazioni dell’IA