Clear Sky Science · pt
Uma estrutura de modelo de linguagem multagente para avaliar automaticamente o desempenho de uma ferramenta clínica de triagem por IA
Por que isso importa para o cuidado ao paciente
Hospitais recorrem cada vez mais a ferramentas de inteligência artificial para sinalizar condições urgentes em exames médicos, como sangramento no cérebro. Mas essas ferramentas podem perder precisão silenciosamente ao longo do tempo, e muitos sistemas de saúde não têm um método simples para verificar se ainda funcionam bem em seus próprios pacientes. Este estudo investiga se uma equipe de sistemas de IA baseados em linguagem pode ler automaticamente laudos de radiologia e monitorar em segundo plano uma ferramenta comercial de triagem de hemorragia cerebral.
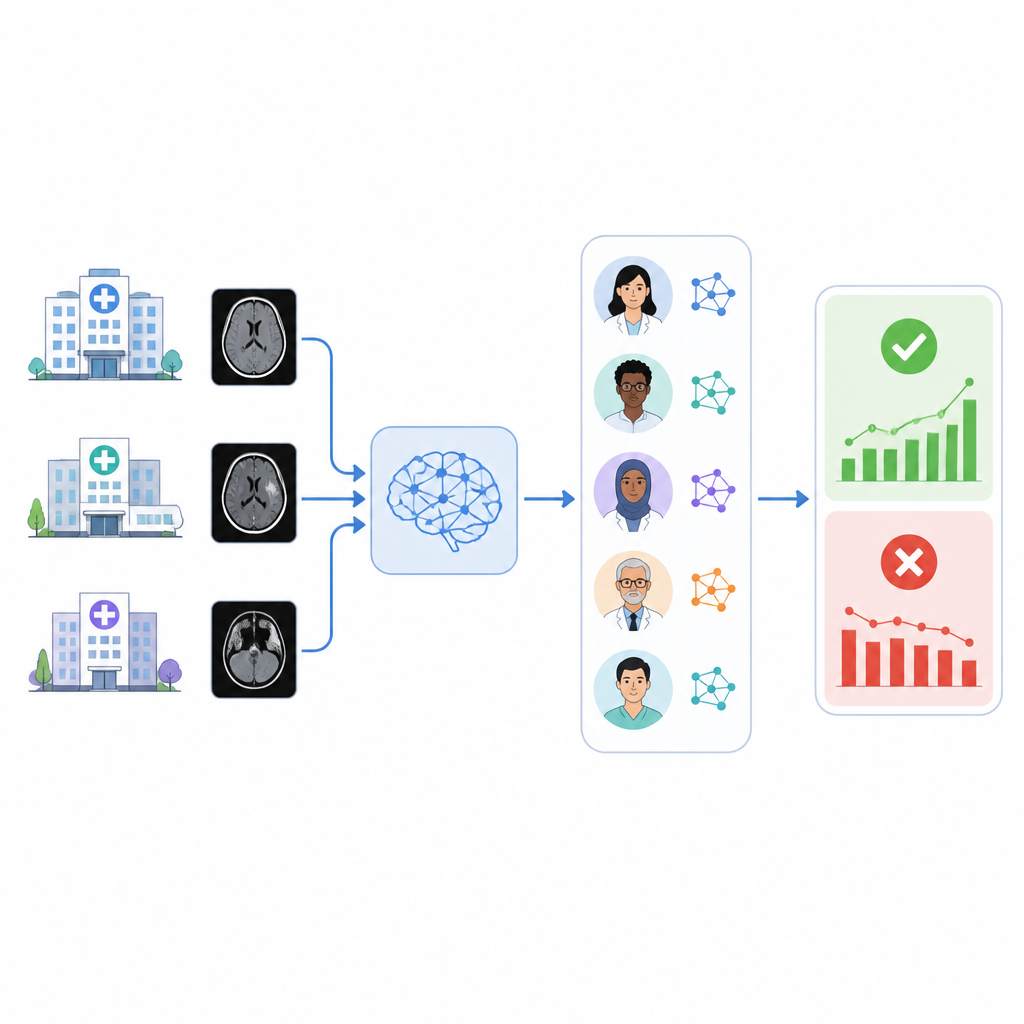
O desafio de checar a IA médica
Uma vez instalada em um hospital, uma ferramenta de IA enfrenta um mundo em mudança: novos aparelhos, protocolos de imagem atualizados e mudanças na população de pacientes podem corroer o desempenho. Fornecedores frequentemente oferecem monitoramento limitado, e os hospitais são responsáveis por detectar vieses injustos e deriva de desempenho. Revisar manualmente milhares de tomografias ou registros médicos para verificar com que frequência uma ferramenta de IA acerta demanda tempo demais dos radiologistas. Como atalho prático, muitos grupos tratam o laudo radiológico final como o melhor resumo disponível do que foi realmente encontrado nas imagens, mas mesmo assim alguém ou algo precisa ler esses laudos.
Usando IAs de linguagem para ler laudos de radiologia
Os autores construíram um sistema chamado RADAR que monitora resultados de uma ferramenta comercial de triagem de hemorragia intracraniana usada em quase 30.000 tomografias de crânio sem contraste de 14 hospitais. Para cada exame, o RADAR posteriormente obtém o laudo radiológico final e extrai apenas a seção de impressão, onde o radiologista dá a conclusão. Esse texto curto é enviado, com as mesmas instruções cuidadosamente redigidas, para oito modelos de linguagem de código aberto executados localmente mais uma versão segura hospedada no hospital do GPT-4o. Cada modelo decide simplesmente se o laudo descreve claramente uma hemorragia cerebral aguda ou não, e os pesquisadores também computam uma resposta de consenso baseada na concordância majoritária entre os modelos.
Quão bem os leitores de IA concordaram com especialistas
Para avaliar a acurácia, dois radiologistas experientes revisaram manualmente 1.726 impressões de laudos, concentrando-se especialmente em casos onde a IA de triagem original e o consenso dos modelos de linguagem discordaram. Laudos ambíguos ou incompletos foram deixados de lado, resultando em 1.490 positivos ou negativos claros para hemorragia cerebral. Entre nove modelos de linguagem, o desempenho variou amplamente. Um modelo pequeno teve desempenho fraco e não foi melhor que o acaso, enquanto um modelo muito grande, Llama3.3:70b, e o GPT-4o mostraram maior capacidade de corresponder à revisão humana, com pontuações sólidas tanto na detecção de hemorragias reais quanto em evitar alarmes falsos. Quando os autores compararam diferentes formas de combinar modelos, descobriram que ensembles construídos a partir dos melhores desempenhos, dos nove modelos completos ou dos oito modelos locais em consenso produziram avaliações similares e robustas da ferramenta comercial de triagem, e todos foram mais consistentes do que depender apenas do GPT-4o.
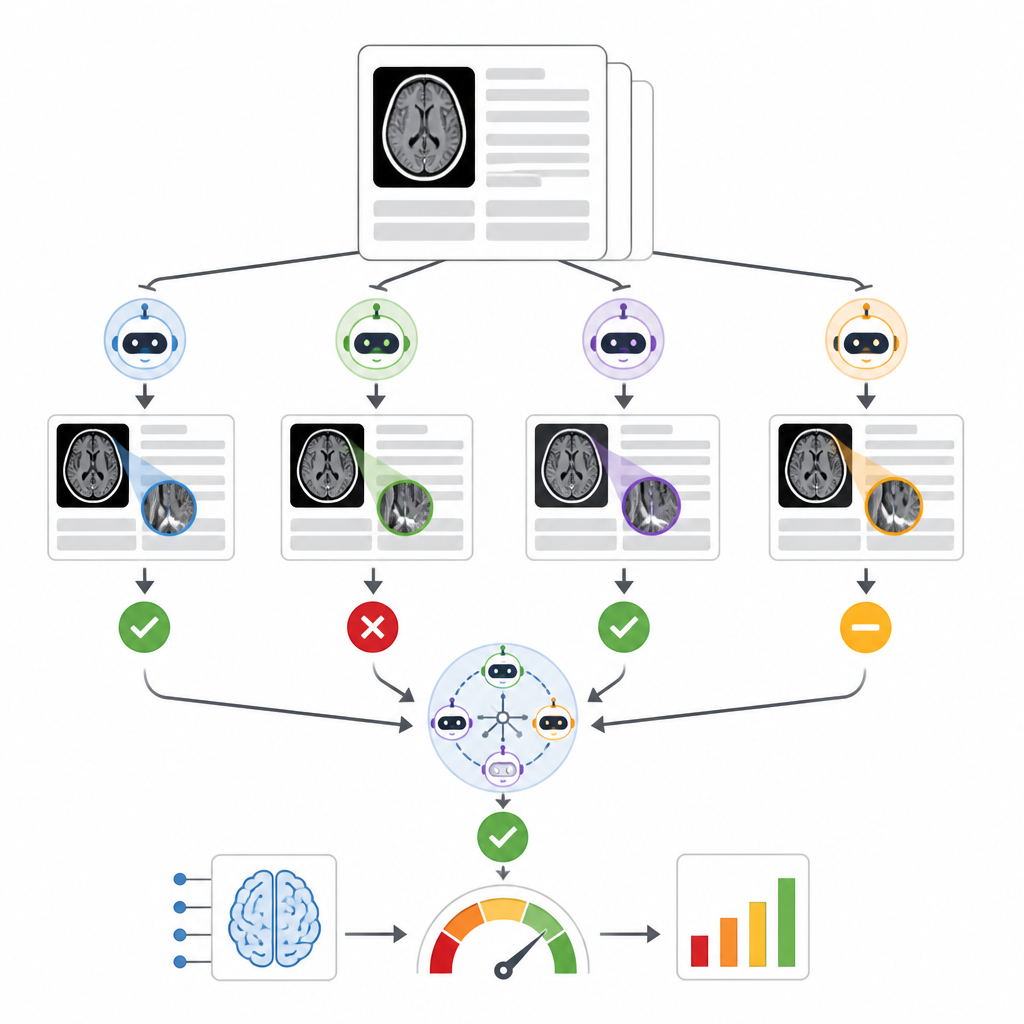
Lidando com a bagunça do mundo real no texto clínico
O estudo destaca a realidade confusa dos relatórios clínicos. Cerca de 14% dos laudos examinados usaram linguagem vaga ou conflitante demais para que humanos ou modelos de linguagem pudessem afirmar com confiança se havia uma nova hemorragia cerebral. Alguns erros surgiram quando o prompt não distinguiu claramente sangramento intracraniano de inchaço leve do couro cabeludo, mostrando que até perguntas simples podem confundir leitores automatizados sem formulação cuidadosa e verificações contínuas. Modelos maiores tendiam a ter desempenho melhor no geral, mas alguns modelos de código aberto de porte médio tiveram desempenho quase equivalente, sugerindo que desenho e engenharia de prompt importam tanto quanto o mero tamanho.
O que isso significa para a IA futura nos hospitais
Os autores concluem que uma pequena equipe de modelos de linguagem colaborativos pode atuar como um painel de revisores especialistas, oferecendo aos hospitais um modo prático, de baixo custo e neutro em relação a fornecedores para monitorar ferramentas de imagem por IA que produzem decisões simples sim ou não. Ao ler continuadamente os laudos rotineiros de radiologia, tais ensembles podem ajudar a detectar quando o desempenho de uma ferramenta de triagem deriva, apoiar investigações sobre possível viés entre locais ou aparelhos e reduzir a necessidade de auditorias manuais extenuantes. Para sistemas de saúde, essa abordagem oferece uma forma de transformar texto de laudos existentes em uma rede de segurança sempre ativa para IA clínica.
Citação: Flanders, A.E., Peng, Y., Prevedello, L. et al. A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool. npj Health Syst. 3, 35 (2026). https://doi.org/10.1038/s44401-026-00100-4
Palavras-chave: monitoramento de IA clínica, laudos de radiologia, grandes modelos de linguagem, hemorragia intracraniana, deriva do desempenho da IA