Clear Sky Science · he
מסגרת מבוססת מודלים לשוניים מרובי-סוכנים להערכה אוטומטית של ביצועי כלי טריאז' קליני מבוסס AI
מדוע זה חשוב לטיפול בחולים
בתי חולים פונים יותר ויותר לכלי בינה מלאכותית שמסמנים מצבים דחופים בסריקות רפואיות, כגון דימום במוח. אך כלים אלה עלולים לאבד דיוק בהדרגה, ורבים ממערכות הבריאות חסרות דרך פשוטה לבדוק אם הם עדיין עובדים היטב על מטופליהן. המחקר הזה בודק האם צוות של מערכות מבוססות שפה יכול לקרוא באופן אוטומטי דוחות רדיולוגיים ולפקח על כלי מסחרי לטריאז' דימומי מוח ברקע.
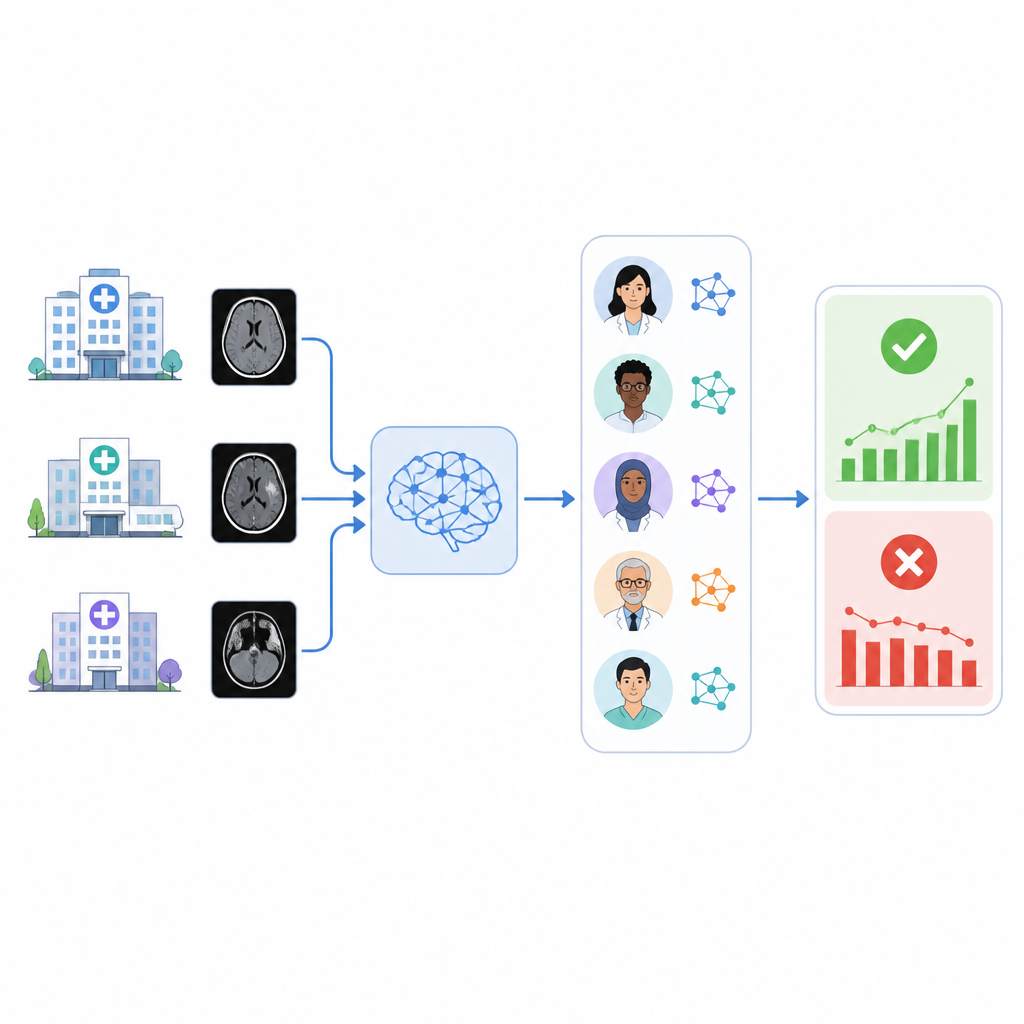
האתגר בבדיקת AI רפואי
לאחר התקנת כלי AI בבית חולים, הוא נתון לעולם שמשתנה: סורקים חדשים, פרוטוקולי הדמיה מעודכנים ואוכלוסיות מטופלים משתנות עשויים כולם לפגוע בביצועים. הספקים לרוב מספקים ניטור מוגבל, ובתי החולים אחראים לזהות הטיות וביצועי סטייה. בדיקה ידנית של אלפי סריקות מוח או רשומות רפואיות כדי לאמת כמה פעמים הכלי צדק אורכת זמן רב מדי עבור רדיולוגים. כקיצור מעשי, קבוצות רבות מתייחסות לדוח הרדיולוגיה הסופי כסיכום הטוב ביותר למה שנמצא בתמונות, אך גם אז מישהו או משהו עדיין צריך לקרוא את אותם דוחות.
שימוש במודלים לשוניים לקריאת דוחות רדיולוגיים
המחברים בנו מערכת בשם RADAR ששומעת תוצאות מכלי טריאז' לדימום תוך-גולגולתי מסחרי שהופעל על כמעט 30,000 סריקות CT ראש ללא חומר ניגוד מ-14 בתי חולים. עבור כל בדיקה, RADAR מושכת מאוחר יותר את דוח הרדיולוגיה הסופי ומחלצת רק את חלקת ה"מסקנה", שבה הרדיולוג נותן את התוצאה הסופית. אותו טקסט קצר נשלח, עם הוראות כתובות זהירות, לשמונה מודלים פתוחים בקוד שרצים מקומית בנוסף לגרסה מאובטחת המושבתת בשרת בית החולים של GPT-4o. כל מודל מחליט האם הדוח מתאר באופן ברור דימום מוחי אקוטי או לא, והחוקרים גם מחשבים תשובת קונצנזוס מבוססת הסכמה ברוב המודלים.
כמה הסכימו קוראי ה-AI עם המומחים
כדי לשפוט דיוק, שני רדיולוגים מנוסים בדקו ידנית 1,726 מסקנות דוחות, עם דגש על מקרים שבהם כלי הטריאז' המקורי והקונצנזוס של המודלים הסתירו. דוחות עמומים או לא שלמים הושמו בצד, ונשארו 1,490 חיוביים או שליליים ברורים לדימום מוחי. בין תשעת המודלים הלשוניים הביצועים השתנו באופן משמעותי. מודל קטן התקשה ולא היה טוב יותר מהגרלה, בעוד שמודל גדול מאוד, Llama3.3:70b, ו-GPT-4o הפגינו את היכולת החזקה ביותר להתאים לסקירת האדם, עם ציונים מוצקים הן בזיהוי דימומים אמיתיים והן במניעת התרעות שווא. כשמשווים דרכים שונות לשילוב מודלים, המחברים מצאו כי אנסמבלים המורכבים מהמובילים, מכל תשעת המודלים, או משמונת המודלים המקומיים בקונצנזוס ייצרו הערכות דומות וחזקות של כלי הטריאז' המסחרי, וכולם היו עקביים יותר מאשר הסתמכות על GPT-4o בלבד.
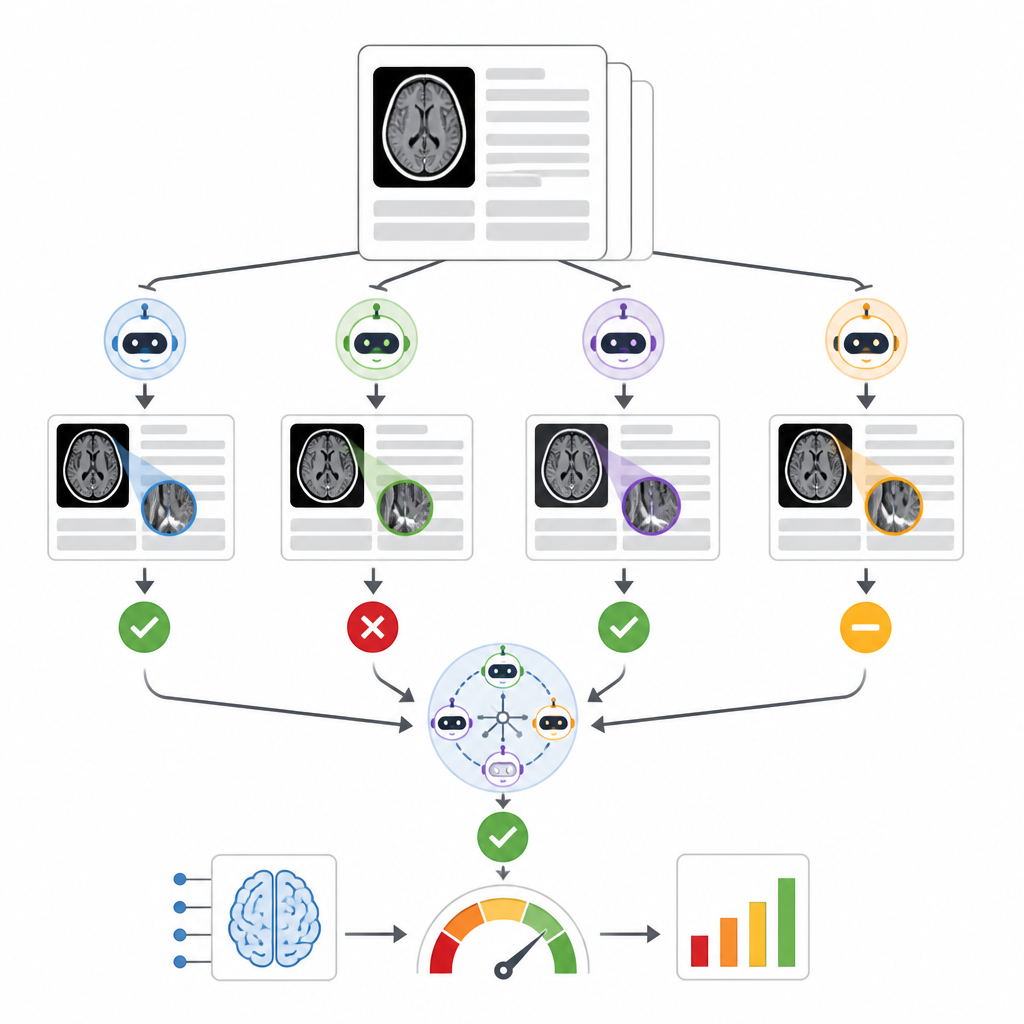
התמודדות עם הבלגן במציאות של טקסט קליני
המחקר מדגיש את המציאות המבוּלת של דיווח קליני. כ-14% מהדוחות שנבדקו השתמשו בשפה שמעורפלת מדי או סותרת כדי שבני אדם או מודלים לשוניים יוכלו לקבוע בביטחון אם יש דימום מוחי טרי. חלק מהטעויות נבעו כשההנחיה (הפרומפט) לא הבחינה בבירור בין דימום בתוך הגולגולת לנפיחות קלה בקרקפת, דבר שהראה שגם שאלות פשוטות עלולות לבלבל קוראים אוטומטיים ללא ניסוח זהיר ובדיקות מתמשכות. מודלים גדולים נטו להצטיין יותר באופן כללי, אך כמה מודלים פתוחים בגודל בינוני היו כמעט זהים בביצועיהם, מה שמרמז שעיצוב והנדסת פרומפט חשובים ככל גודל המודל עצמו.
מה זה אומר למחיר ה-AI בבתי חולים בעתיד
המחברים מסכמים כי צוות קטן של מודלים לשוניים משתפי פעולה יכול לפעול כמו פאנל של מבקרים מומחים, והציע לבית חולים דרך מעשית, זולה ונייטרלית לספקן לעקוב אחר כלי הדימות שמחזירים החלטות פשוטות של כן/לא. על ידי קריאה רציפה של דוחות רדיולוגים שגרתיים, אנסמבלים כאלה יכולים לעזור לזהות מתי ביצועי כלי הטריאז' סטו, לתמוך בחקירות לגבי הטיה אפשרית בין אתרים או סורקים, ולהפחית את הצורך בביקורות ידניות מייגעות. עבור מערכות בריאות, גישה זו מציעה דרך להפוך את טקסט הדוחות הקיים לרשת בטיחות פעילה תמיד עבור AI קליני.
ציטוט: Flanders, A.E., Peng, Y., Prevedello, L. et al. A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool. npj Health Syst. 3, 35 (2026). https://doi.org/10.1038/s44401-026-00100-4
מילות מפתח: ניטור AI קליני, דוחות רדיולוגיה, מודלים לשוניים גדולים, דימום תוך-גולגולתי, סטיית ביצועי AI