Clear Sky Science · fr
Un cadre multi-agents de modèles de langage de grande taille pour évaluer automatiquement les performances d’un outil clinique de triage
Pourquoi cela compte pour les soins aux patients
Les hôpitaux recourent de plus en plus à des outils d’intelligence artificielle pour signaler des situations urgentes sur des examens médicaux, comme une hémorragie cérébrale. Mais ces outils peuvent perdre silencieusement de leur précision avec le temps, et de nombreux systèmes de santé n’ont pas de méthode simple pour vérifier s’ils fonctionnent toujours correctement sur leurs propres patients. Cette étude explore si une équipe de systèmes d’IA basés sur le langage peut lire automatiquement les comptes rendus de radiologie et surveiller en tâche de fond un outil commercial de triage des hémorragies cérébrales.
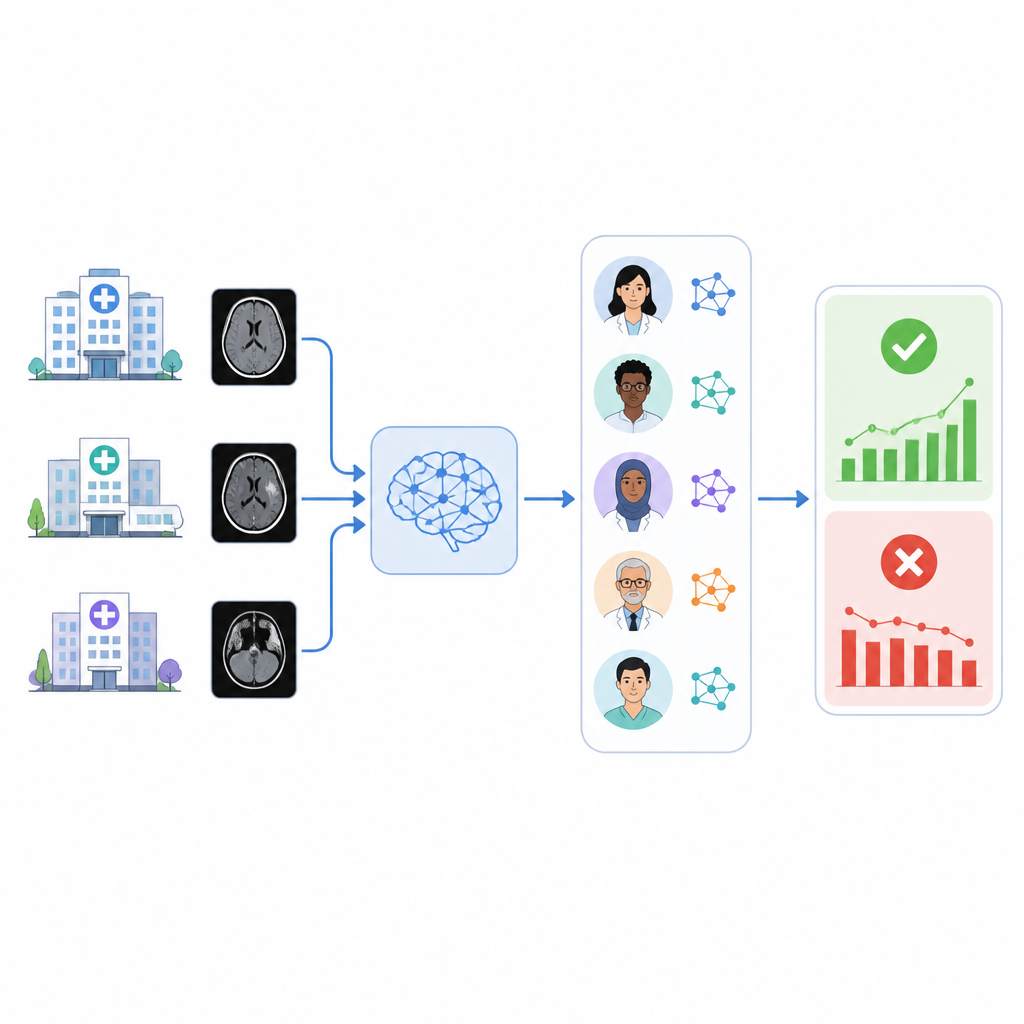
Le défi de contrôler l’IA médicale
Une fois déployé dans un hôpital, un outil d’IA doit faire face à un monde en mutation : nouveaux appareils, protocoles d’imagerie mis à jour et populations de patients changeantes peuvent tous dégrader la performance. Les fournisseurs offrent souvent une surveillance limitée, et les hôpitaux sont responsables de détecter les biais et la dérive des performances. Examiner manuellement des milliers de scanners ou de dossiers médicaux pour vérifier à quelle fréquence un outil d’IA a raison est bien trop chronophage pour les radiologues. Comme solution pratique, de nombreux groupes considèrent le compte rendu radiologique final comme le meilleur résumé disponible de ce qui a réellement été observé sur les images, mais même dans ce cas, il faut que quelqu’un ou quelque chose lise ces comptes rendus.
Utiliser des IA de langage pour lire les comptes rendus de radiologie
Les auteurs ont construit un système appelé RADAR qui surveille les résultats d’un outil commercial de triage des hémorragies intracrâniennes utilisé sur près de 30 000 scanners cérébraux sans contraste provenant de 14 hôpitaux. Pour chaque examen, RADAR récupère ensuite le compte rendu radiologique final et extrait uniquement la section « impression », où le radiologue donne la conclusion. Ce court texte est envoyé, avec les mêmes instructions soigneusement rédigées, à huit modèles de langage open source exécutés localement ainsi qu’à une version sécurisée hébergée par l’hôpital de GPT-4o. Chaque modèle décide simplement si le compte rendu décrit clairement une hémorragie cérébrale aiguë ou non, et les chercheurs calculent également une réponse de consensus basée sur la majorité d’accord entre les modèles.
Quel degré d’accord entre les lecteurs IA et les experts
Pour évaluer la précision, deux radiologues expérimentés ont relu manuellement 1 726 sections d’impression de comptes rendus, en se concentrant particulièrement sur les cas où l’IA de triage originale et le consensus des modèles de langage étaient en désaccord. Les comptes rendus ambigus ou incomplets ont été mis de côté, laissant 1 490 positifs ou négatifs clairs pour l’hémorragie cérébrale. Parmi neuf modèles de langage, les performances variaient largement. Un petit modèle a eu des difficultés et n’était guère meilleur que le hasard, tandis qu’un très grand modèle, Llama3.3:70b, et GPT-4o ont montré la plus forte capacité à correspondre à l’évaluation humaine, avec de bons scores tant pour détecter les hémorragies réelles que pour éviter les fausses alertes. Lorsque les auteurs ont comparé différentes façons de combiner les modèles, ils ont constaté que des ensembles construits à partir des meilleurs performeurs, de l’ensemble des neuf modèles, ou des huit modèles locaux en consensus produisaient tous des évaluations similaires et robustes de l’outil commercial de triage, et qu’ils étaient tous plus cohérents que de se fier uniquement à GPT-4o.
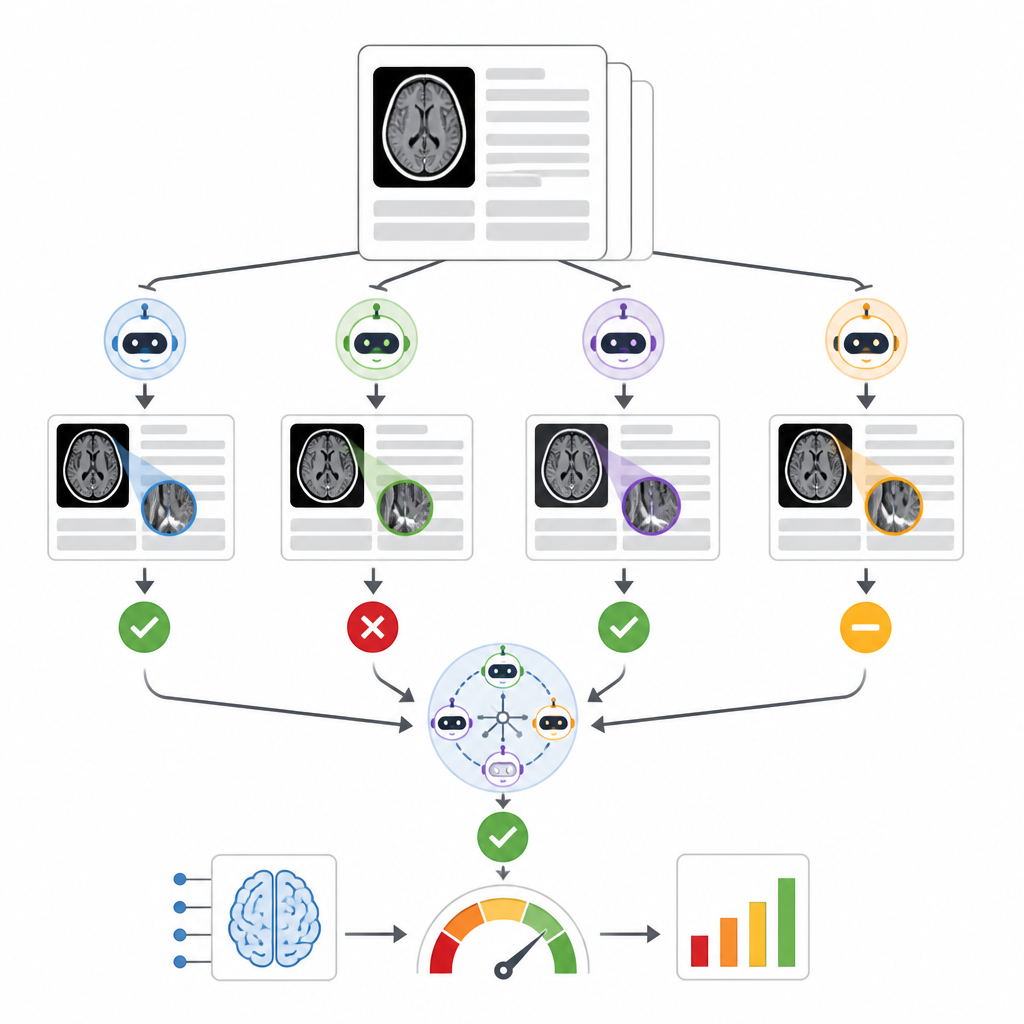
Gérer la complexité du monde réel dans le texte clinique
L’étude met en évidence la réalité souvent désordonnée des comptes rendus cliniques. Environ 14 % des comptes rendus examinés utilisaient un langage trop vague ou contradictoire pour que des humains ou des modèles de langage puissent affirmer avec confiance la présence d’une hémorragie cérébrale récente. Certaines erreurs sont survenues lorsque l’invite (« prompt ») ne distinguait pas clairement un saignement intracrânien d’un léger œdème du cuir chevelu, montrant que même des questions simples peuvent dérouter des lecteurs automatisés sans formulation attentive et vérifications continues. Les modèles de plus grande taille avaient tendance à mieux performer globalement, mais certains modèles open source de taille moyenne ont presque obtenu les mêmes résultats, ce qui suggère que la conception et l’ingénierie des prompts comptent autant que la taille brute.
Ce que cela implique pour l’IA hospitalière future
Les auteurs concluent qu’une petite équipe de modèles de langage collaboratifs peut agir comme un panel d’experts réviseurs, offrant aux hôpitaux une manière pratique, peu coûteuse et neutre vis-à-vis des fournisseurs de surveiller les outils d’imagerie qui fournissent des décisions simples oui/non. En lisant en continu les comptes rendus radiologiques de routine, de tels ensembles peuvent aider à détecter la dérive de performance d’un outil de triage, soutenir les enquêtes sur d’éventuels biais entre sites ou appareils, et réduire le besoin d’audits manuels laborieux. Pour les systèmes de santé, cette approche permet de transformer le texte existant des comptes rendus en un filet de sécurité toujours actif pour l’IA clinique.
Citation: Flanders, A.E., Peng, Y., Prevedello, L. et al. A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool. npj Health Syst. 3, 35 (2026). https://doi.org/10.1038/s44401-026-00100-4
Mots-clés: surveillance des IA cliniques, comptes rendus de radiologie, modèles de langage de grande taille, hémorragie intracrânienne, dérive des performances de l’IA