Clear Sky Science · pl
Rama wieloagentowego dużego modelu językowego do automatycznej oceny wydajności klinicznego narzędzia triage AI
Dlaczego to ma znaczenie dla opieki nad pacjentem
Szpitale coraz częściej sięgają po narzędzia sztucznej inteligencji, które sygnalizują pilne stany na badaniach obrazowych, na przykład krwawienie w mózgu. Jednak takie narzędzia mogą stopniowo tracić dokładność, a wiele systemów ochrony zdrowia nie ma prostego sposobu, by sprawdzać, czy nadal działają dobrze na ich własnych pacjentach. Badanie to bada, czy zespół opartych na języku systemów AI może automatycznie czytać raporty radiologiczne i w tle nadzorować komercyjne narzędzie triage wykrywające krwawienia mózgowe.
Problem sprawdzania medycznej AI
Gdy narzędzie AI zostanie wdrożone w szpitalu, napotyka na zmieniający się świat: nowe skanery, zaktualizowane protokoły obrazowania i zmiany w populacji pacjentów mogą osłabiać jego wydajność. Dostawcy często oferują tylko ograniczony monitoring, a odpowiedzialność za wykrywanie niesprawiedliwych uprzedzeń i dryfu wydajności spoczywa na szpitalach. Ręczne przeglądanie tysięcy skanów mózgu lub dokumentacji medycznej, by zweryfikować, jak często narzędzie AI ma rację, zajmuje radiologom zdecydowanie zbyt dużo czasu. Jako praktyczne uproszczenie wiele grup traktuje końcowy raport radiologiczny jako najlepsze dostępne podsumowanie tego, co faktycznie znaleziono na obrazach, ale nawet wtedy ktoś lub coś nadal musi te raporty przeczytać.
Wykorzystanie modeli językowych do czytania raportów radiologicznych
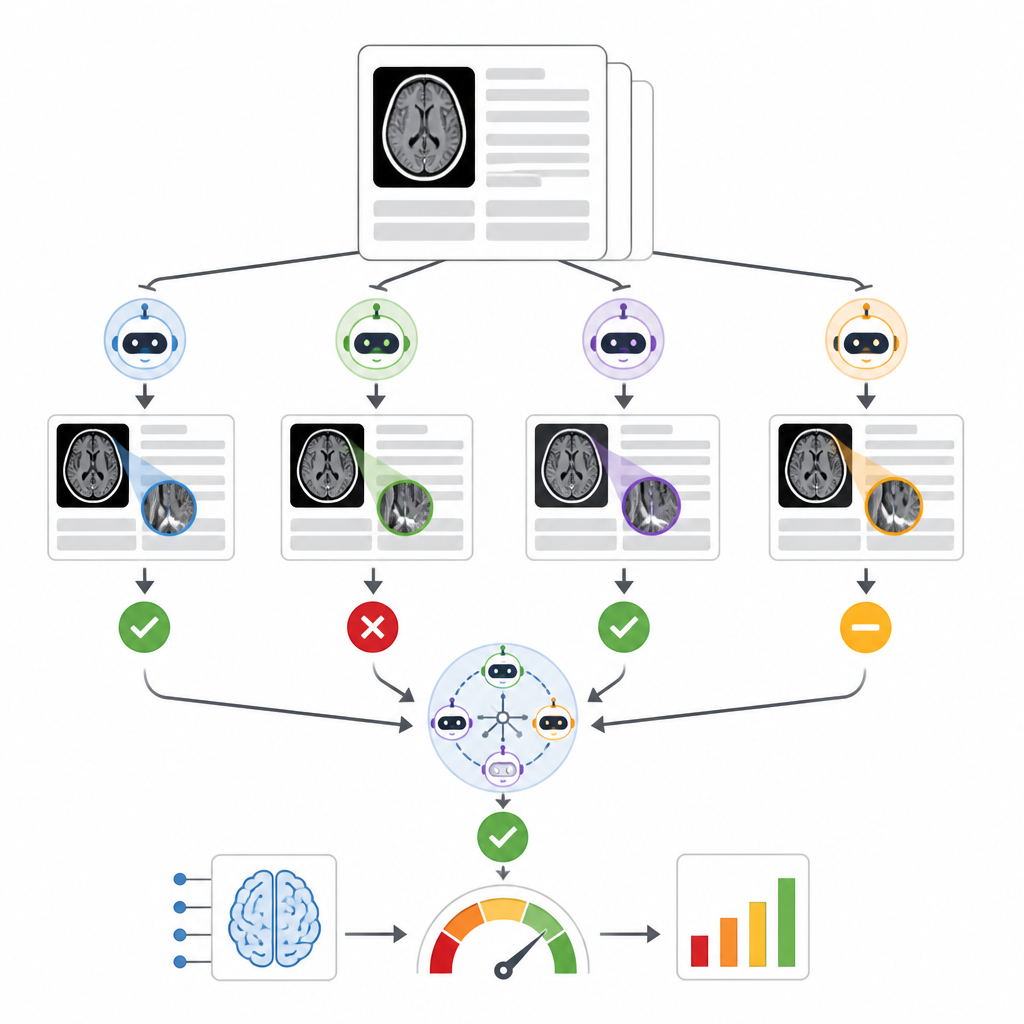
Autorzy stworzyli system nazwany RADAR, który nasłuchuje wyników komercyjnego narzędzia triage wykrywającego krwotok wewnątrzczaszkowy używanego na prawie 30 000 niekontrastowych tomografii komputerowych głowy ze 14 szpitali. Dla każdego badania RADAR później pobiera końcowy raport radiologiczny i wyodrębnia jedynie sekcję "wniosek", w której radiolog przedstawia sedno sprawy. Ten krótki tekst jest przesyłany, wraz z tymi samymi starannie sformułowanymi instrukcjami, do ośmiu otwartoźródłowych modeli językowych działających lokalnie oraz do bezpiecznej, hostowanej w szpitalu wersji GPT-4o. Każdy model po prostu decyduje, czy raport wyraźnie opisuje ostre krwawienie mózgowe, czy nie, a badacze obliczają także odpowiedź konsensusową opartą na większościowym porozumieniu między modelami.
Na ile czytelnicy AI zgadzali się z ekspertami
Aby ocenić dokładność, dwaj doświadczeni radiolodzy ręcznie przejrzeli 1 726 wniosków z raportów, skupiając się szczególnie na przypadkach, w których oryginalne narzędzie triage i konsensus modeli językowych się nie zgadzały. Raporty niejednoznaczne lub niekompletne odrzucono, pozostawiając 1 490 jasnych pozytywów lub negatywów dotyczących krwawienia mózgowego. Wśród dziewięciu modeli językowych wydajność różniła się znacząco. Mały model miał trudności i nie był lepszy niż losowy wybór, podczas gdy bardzo duży model Llama3.3:70b oraz GPT-4o wykazały najsilniejszą zdolność do dopasowania się do oceny ludzkiej, z solidnymi wynikami zarówno w wykrywaniu rzeczywistych krwawień, jak i w unikaniu fałszywych alarmów. Kiedy autorzy porównywali różne sposoby łączenia modeli, odkryli, że zespoły zbudowane z najlepszych wykonawców, ze wszystkich dziewięciu modeli, lub z ośmiu lokalnych modeli w konsensusie dawały podobne i odporne oceny komercyjnego narzędzia triage, i wszystkie były bardziej spójne niż poleganie wyłącznie na GPT-4o.
Radzenie sobie z realnym bałaganem w tekście klinicznym
Badanie uwypukla chaotyczną rzeczywistość raportowania klinicznego. Około 14 procent badanych raportów używało języka zbyt niejednoznacznego lub sprzecznego, by zarówno ludzie, jak i modele językowe mogły z pełnym przekonaniem stwierdzić, czy obecne jest świeże krwawienie mózgowe. Niektóre błędy pojawiły się, gdy podpowiedź nie rozróżniała wyraźnie krwawienia wewnątrzczaszkowego od drobnego obrzęku skóry głowy, co pokazuje, że nawet proste pytania mogą potykać automatycznych czytelników bez starannego formułowania i bieżącej weryfikacji. Większe modele miały tendencję do lepszej wydajności ogólnie, ale niektóre średnio duże otwartoźródłowe modele radziły sobie niemal równie dobrze, co sugeruje, że projekt i inżynieria promptów mają równie duże znaczenie co sama wielkość.
Co to oznacza dla przyszłych systemów AI w szpitalach
Autorzy wnioskują, że niewielki zespół współpracujących modeli językowych może działać jak panel ekspertów recenzentów, oferując szpitalom praktyczny, niedrogi i neutralny wobec dostawcy sposób monitorowania narzędzi obrazowych AI, które wydają proste decyzje tak/nie. Poprzez ciągłe czytanie rutynowych raportów radiologicznych takie zespoły mogą pomagać wykrywać momenty, gdy wydajność narzędzia triage ulega dryfowi, wspierać dochodzenia dotyczące możliwych uprzedzeń między placówkami czy skanerami oraz zmniejszać potrzebę żmudnych audytów ręcznych. Dla systemów opieki zdrowotnej podejście to oferuje sposób przekształcenia istniejących tekstów raportów w zawsze aktywne zabezpieczenie dla klinicznej AI.
Cytowanie: Flanders, A.E., Peng, Y., Prevedello, L. et al. A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool. npj Health Syst. 3, 35 (2026). https://doi.org/10.1038/s44401-026-00100-4
Słowa kluczowe: monitorowanie AI w klinice, raporty radiologiczne, duże modele językowe, krwotok wewnątrzczaszkowy, dryf wydajności AI