Clear Sky Science · nl
Een raamwerk met meerdere agenten voor grote taalmodellen om automatisch de prestaties van een klinische AI-triagetool te beoordelen
Waarom dit belangrijk is voor de patiëntenzorg
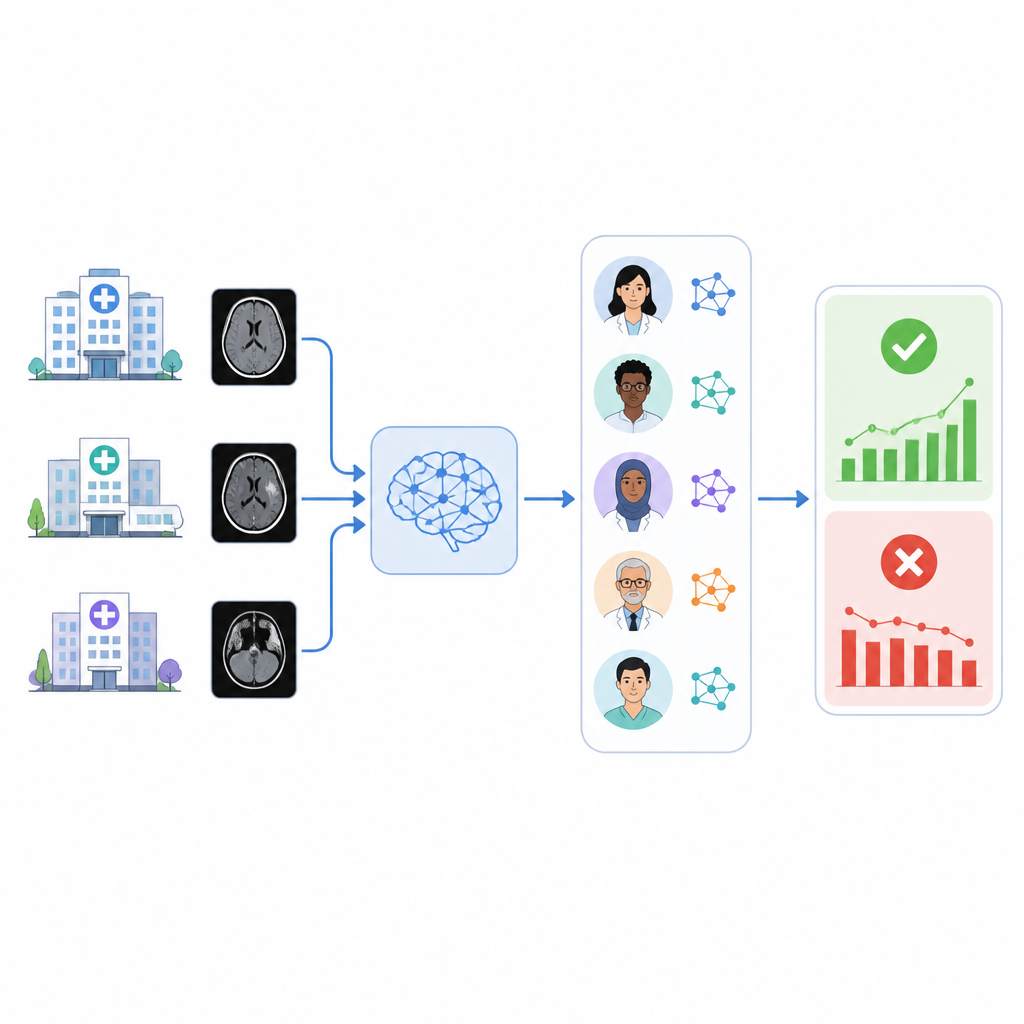
Ziekenhuizen zetten steeds vaker kunstmatige-intelligentiehulpmiddelen in om urgente aandoeningen op beeldvorming te signaleren, zoals bloedingen in de hersenen. Maar deze hulpmiddelen kunnen in stilte aan nauwkeurigheid inboeten na verloop van tijd, en veel zorgsystemen hebben geen eenvoudige manier om te controleren of ze nog goed werken voor hun eigen patiënten. Deze studie onderzoekt of een team van op taal gebaseerde AI-systemen radiologierapporten automatisch kan lezen en op de achtergrond toezicht kan houden op een commerciële triage-AI voor hersenbloedingen.
De uitdaging van het controleren van medische AI
Zodra een AI-tool in een ziekenhuis is geïmplementeerd, staat hij in een veranderende omgeving: nieuwe scanners, bijgewerkte beeldvormingsprotocollen en verschuivende patiëntpopulaties kunnen allemaal de prestaties aantasten. Leveranciers bieden vaak slechts beperkte monitoring, en ziekenhuizen zijn verantwoordelijk voor het opsporen van oneerlijke vooroordelen en prestatieafwijkingen. Het handmatig beoordelen van duizenden hersenscans of medische dossiers om te verifiëren hoe vaak een AI-tool gelijk heeft, kost radiologen veel te veel tijd. Als praktische tussenoplossing beschouwen veel groepen het uiteindelijke radiologierapport als de best beschikbare samenvatting van wat er werkelijk op de beelden werd gevonden, maar zelfs dan moet iemand of iets die rapporten nog steeds lezen.
Het gebruik van taal-AI’s om radiologierapporten te lezen
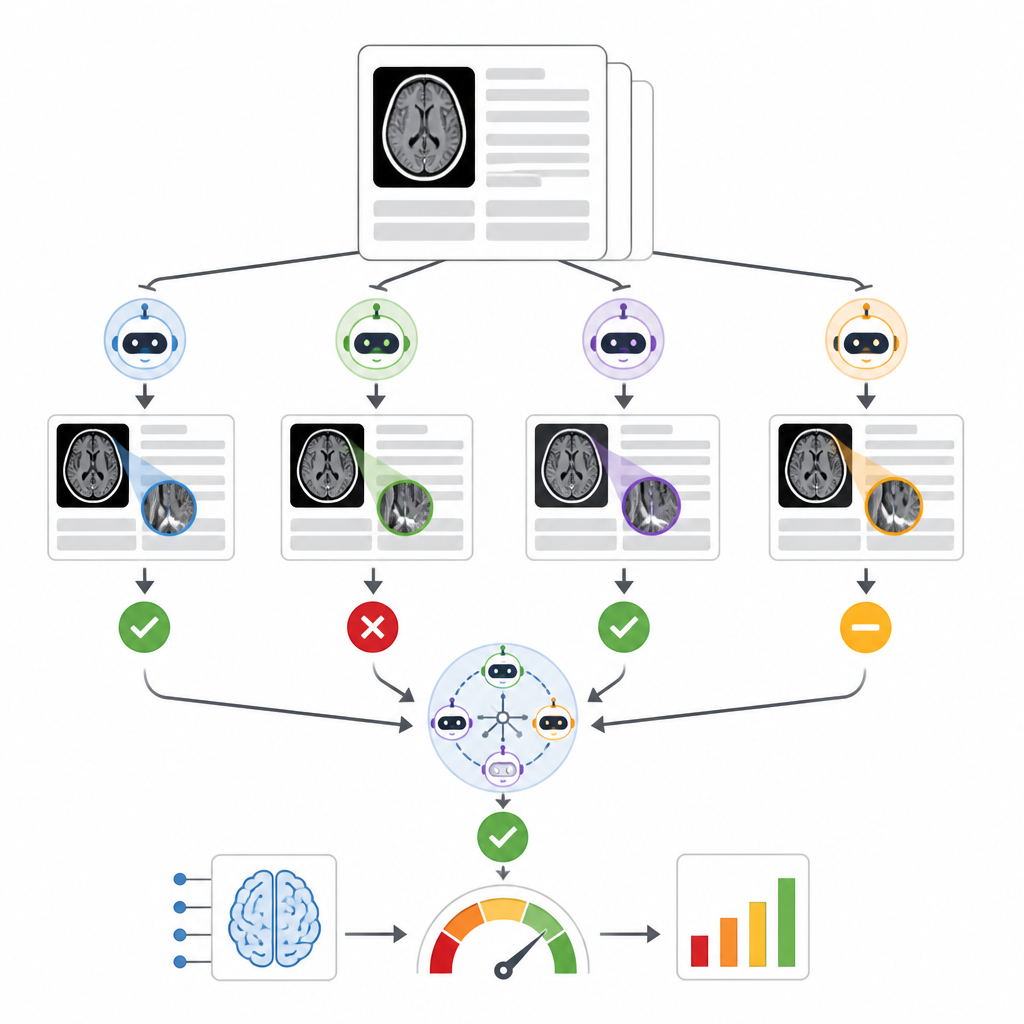
De auteurs bouwden een systeem genaamd RADAR dat luistert naar resultaten van een commerciële triagetool voor intracraniële bloedingen, gebruikt op bijna 30.000 niet-gekontrastte head-CT’s van 14 ziekenhuizen. Voor elk onderzoek haalt RADAR later het definitieve radiologierapport op en extraheert alleen de sectie 'conclusie', waar de radioloog de kernzin geeft. Die korte tekst wordt, met dezelfde zorgvuldig geformuleerde instructies, naar acht open-source taalmodellen die lokaal draaien gestuurd, plus een beveiligde door het ziekenhuis gehoste versie van GPT-4o. Elk model beslist eenvoudig of het rapport duidelijk een acute hersenbloeding beschrijft of niet, en de onderzoekers berekenen ook een consensusantwoord op basis van de meerderheidsovereenkomst tussen de modellen.
Hoe goed de AI-lezers overeenkwamen met experts
Om de nauwkeurigheid te beoordelen, bekeken twee ervaren radiologen handmatig 1.726 rapportconclusies, met speciale aandacht voor gevallen waarin de oorspronkelijke triage-AI en de consensus van de taalmodellen het oneens waren. Ambigue of onvolledige rapporten werden opzijgezet, wat 1.490 duidelijke positieve of negatieve gevallen voor hersenbloeding overliet. Over negen taalmodellen varieerden de prestaties sterk. Een klein model worstelde en deed niet beter dan toeval, terwijl een zeer groot model, Llama3.3:70b, en GPT-4o het sterkst bleken in het overeenkomen met menselijke beoordeling, met degelijke scores zowel bij het detecteren van echte bloedingen als bij het vermijden van valse alarmen. Toen de auteurs verschillende manieren vergeleken om modellen te combineren, vonden ze dat ensembles opgebouwd uit de beste presteerders, uit alle negen modellen of uit de acht lokale modellen in consensus vergelijkbare en robuuste beoordelingen van de commerciële triagetool produceerden, en allemaal consistenter waren dan het vertrouwen op GPT-4o alleen.
Omgaan met real-world rommeligheid in klinische tekst
De studie benadrukt de rommelige realiteit van klinische rapportage. Ongeveer 14 procent van de onderzochte rapporten gebruikte taal die te vaag of tegenstrijdig was om zowel mensen als taalmodellen met vertrouwen te laten zeggen of er een nieuwe hersenbloeding aanwezig was. Sommige fouten ontstonden wanneer de prompt niet duidelijk onderscheidde tussen bloeding binnen de schedel en geringe zwelling van de hoofdhuid, wat laat zien dat zelfs eenvoudige vragen geautomatiseerde lezers kunnen doen struikelen zonder zorgvuldige formulering en voortdurende controles. Grotere modellen presteerden over het algemeen beter, maar sommige middelgrote open-source modellen deden het bijna even goed, wat suggereert dat ontwerp en prompt-engineering net zo belangrijk zijn als louter modelgrootte.
Wat dit betekent voor toekomstige AI in ziekenhuizen
De auteurs concluderen dat een klein team van samenwerkende taalmodellen kan optreden als een panel van deskundige beoordelaars, en ziekenhuizen een praktische, goedkope en leverancier-neutrale manier biedt om imaging-AI-hulpmiddelen die eenvoudige ja/nee-beslissingen leveren, in de gaten te houden. Door routinematig radiologierapporten continu te lezen, kunnen dergelijke ensembles helpen detecteren wanneer de prestaties van een triagetool afwijken, ondersteunen bij onderzoeken naar mogelijke vooringenomenheid tussen locaties of scanners, en de behoefte aan arbeidsintensieve handmatige audits verminderen. Voor zorgsystemen biedt deze aanpak een manier om bestaande rapporttekst om te zetten in een altijd-aan veiligheidsnet voor klinische AI.
Bronvermelding: Flanders, A.E., Peng, Y., Prevedello, L. et al. A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool. npj Health Syst. 3, 35 (2026). https://doi.org/10.1038/s44401-026-00100-4
Trefwoorden: monitoring van klinische AI, radiologierapporten, grote taalmodellen, intracraniële bloeding, prestatieafwijking van AI