Clear Sky Science · tr
Bir klinik AI triage aracının performansını otomatik olarak değerlendirmek için çok ajanlı büyük dil modeli çerçevesi
Hasta bakımı için bunun önemi
Hastaneler, beyin içindeki kanama gibi acil durumları tespit etmek için tıbbi görüntülerde yapay zeka araçlarına giderek daha fazla güveniyor. Ancak bu araçlar zamanla fark edilmeden doğruluk kaybedebilir ve birçok sağlık sistemi, kendi hastalarında hâlâ iyi çalışıp çalışmadıklarını kolayca kontrol edecek bir yönteme sahip değil. Bu çalışma, dil tabanlı AI sistemlerinden oluşan bir ekibin radyoloji raporlarını otomatik olarak okuyup arka planda ticari bir beyin kanaması triage aracını izleyip izleyemeyeceğini araştırıyor.
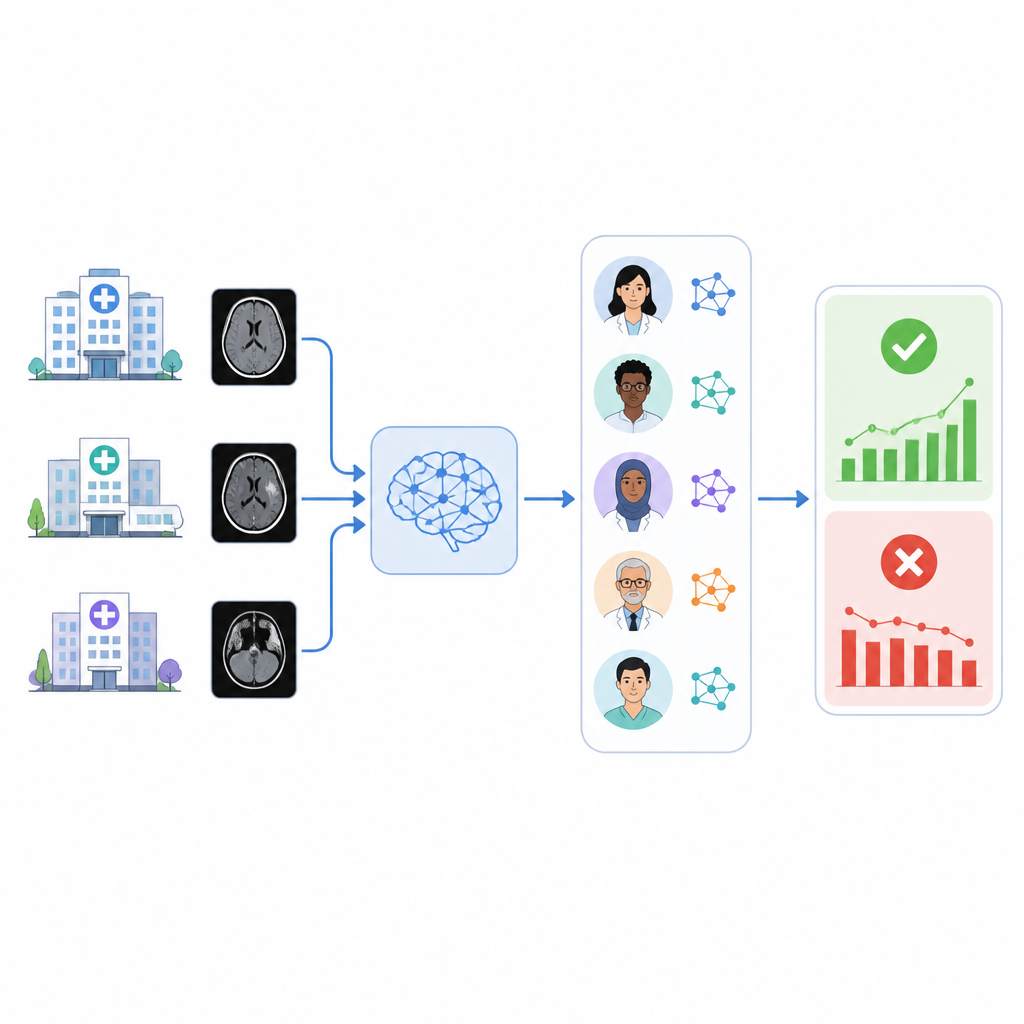
Tıbbi AI’yı kontrol etmenin zorluğu
Bir AI aracı hastaneye kurulduktan sonra değişen bir dünyayla karşılaşır: yeni tarayıcılar, güncellenmiş görüntüleme protokolleri ve değişen hasta nüfusları performansı aşındırabilir. Sağlayıcılar genellikle yalnızca sınırlı izleme sunar ve hastaneler adaletsizlikleri ve performans sürüklenmesini tespit etmekten sorumludur. Bir AI aracının ne sıklıkta doğru olduğunu doğrulamak için binlerce beyin taramasını veya tıbbi kaydı elle gözden geçirmek, radyologlar için çok zaman alıcıdır. Pratik bir kestirme olarak birçok grup, görüntülerde gerçekten bulunanların en iyi mevcut özeti olarak nihai radyoloji raporunu kabul eder, ancak yine de bu raporları birinin veya bir şeyin okuması gerekir.
Radyoloji raporlarını okumak için dil AI’larının kullanılması
Yazarlar, RADAR adını verdikleri; 14 hastaneden neredeyse 30.000 kontrastsız kafa BT taramasında kullanılan ticari bir intrakraniyal hemoraji triage aracının sonuçlarını dinleyen bir sistem geliştirdiler. Her inceleme için RADAR, daha sonra nihai radyoloji raporunu çeker ve radyoloğun sonuç özetini verdiği sadece “izlenim” bölümünü çıkarır. Bu kısa metin, aynı özenle hazırlanmış talimatlarla birlikte yerel olarak çalışan sekiz açık kaynak dil modeline ve güvenli şekilde hastane sunucusunda barındırılan GPT‑4o’ya gönderilir. Her model, raporda açıkça akut bir beyin kanamasının tanımlanıp tanımlanmadığına karar verir ve araştırmacılar ayrıca modeller arasında çoğunluk oyuna dayalı bir uzlaşı cevabı hesaplar.
AI okuyucularının uzmanlarla ne kadar uyumlu olduğu
Doğruluğu değerlendirmek için iki deneyimli radyolog 1.726 rapor izlenimini elle inceledi; özellikle orijinal triage AI ile dil modeli uzlaşısının çeliştiği vakalara odaklandılar. Belirsiz veya eksik raporlar bir kenara bırakıldı ve geriye beyin kanaması için 1.490 net pozitif veya negatif vaka kaldı. Dokuz dil modeli arasında performans büyük ölçüde değişti. Küçük bir model zorlandı ve şans düzeyinden daha iyi değildi; çok büyük bir model olan Llama3.3:70b ve GPT‑4o ise insan incelemesiyle eşleşmede en güçlü yeteneği gösterdi; hem gerçek kanamaları tespit etmede hem de yanlış alarm vermemede sağlam puanlar aldılar. Yazarlar farklı model birleştirme yollarını karşılaştırdıklarında, en iyi performans gösterenlerden, dokuz modelin tamamından veya yerel sekiz modelin uzlaşısından oluşturulan birliklerin, ticari triage aracının benzer ve sağlam değerlendirmelerini ürettiğini ve bunların tek başına GPT‑4o’ya güvenmekten daha tutarlı olduğunu buldular.
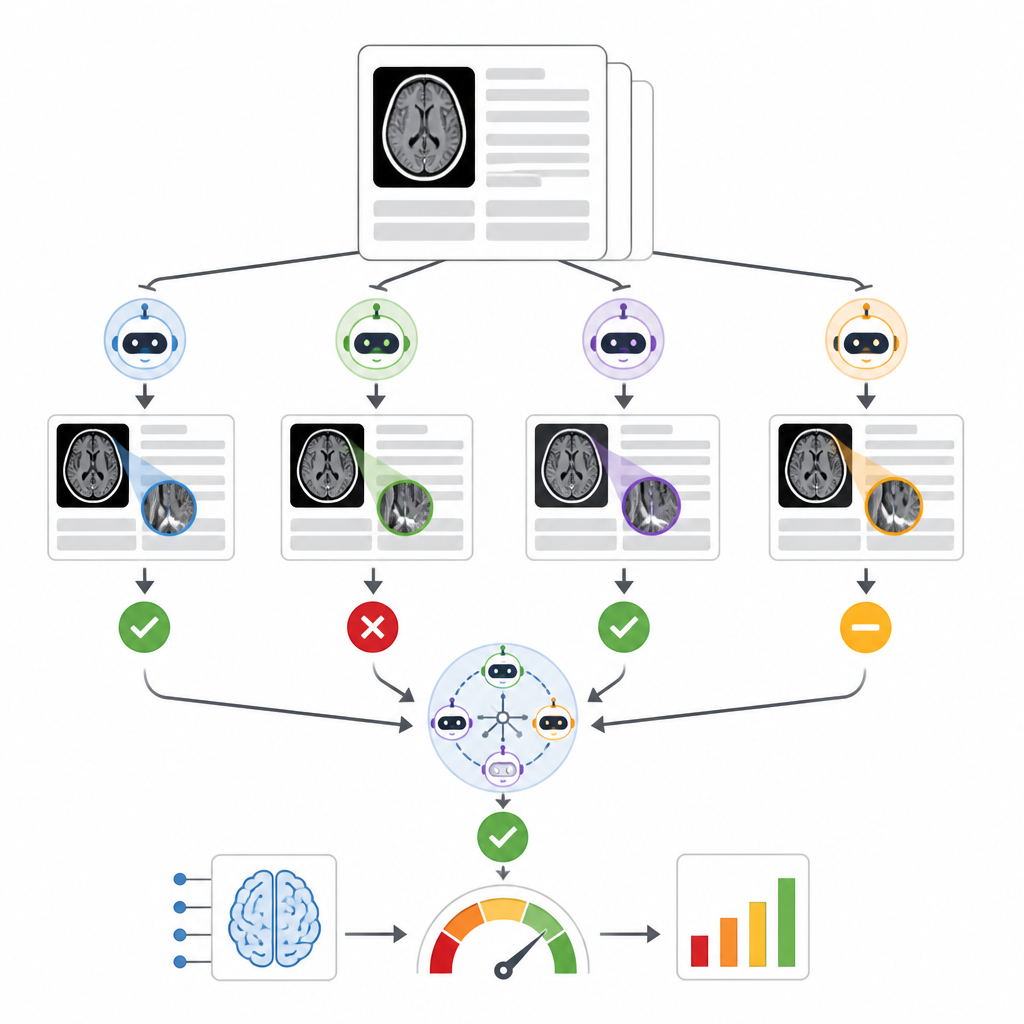
Klinik metindeki gerçek dünya karmaşıklığıyla başa çıkma
Çalışma, klinik raporlamanın dağınık gerçekliğini vurguluyor. İncelenen raporların yaklaşık yüzde 14’ünde kullanılan dil, ne insanlar ne de dil modellerinin taze bir beyin kanaması var mı diye güvenle söyleyebilmesi için çok belirsiz veya çelişkiliydi. Bazı hatalar, istemin kafatası içindeki kanamayı saç derisindeki hafif şişliğe açıkça ayırt etmemesi durumunda ortaya çıktı; bu, basit soruların bile dikkatli ifade ve sürekli kontroller olmadan otomatik okuyucuları yanıltabileceğini gösteriyor. Daha büyük modeller genel olarak daha iyi performans eğilimi gösterse de, bazı orta boy açık kaynak modeller neredeyse aynı kadar iyi performans gösterdi; bu da tasarım ve istem mühendisliğinin salt model büyüklüğü kadar önemli olduğunu düşündürüyor.
Gelecekteki hastane AI’ları için anlamı
Yazarlar, iş birliği yapan küçük bir dil modeli grubunun uzman inceleme panosu gibi hareket ederek hastanelere basit evet/hayır kararı veren görüntüleme AI araçlarını izlemeleri için pratik, düşük maliyetli ve satıcıdan bağımsız bir yol sunabileceği sonucuna varıyor. Rutin radyoloji raporlarını sürekli okuyarak bu tür birlikler bir triage aracının performansının ne zaman sürüklendiğini tespit etmeye, sahalar veya tarayıcılar arasındaki olası önyargıları araştırmaya yardımcı olmaya ve zahmetli elle denetimlere olan ihtiyacı azaltmaya destek olabilir. Sağlık sistemleri için bu yaklaşım, mevcut rapor metnini klinik AI için her zaman açık bir güvenlik ağına dönüştürmenin bir yolunu sunuyor.
Atıf: Flanders, A.E., Peng, Y., Prevedello, L. et al. A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool. npj Health Syst. 3, 35 (2026). https://doi.org/10.1038/s44401-026-00100-4
Anahtar kelimeler: klinik AI izleme, radyoloji raporları, büyük dil modelleri, intrakraniyal hemoraji, AI performans sürüklenmesi