Clear Sky Science · sv
En ram för stora flera-agenters språkmodeller för att automatiskt utvärdera prestanda hos ett kliniskt AI-triageverktyg
Varför detta är viktigt för patientvården
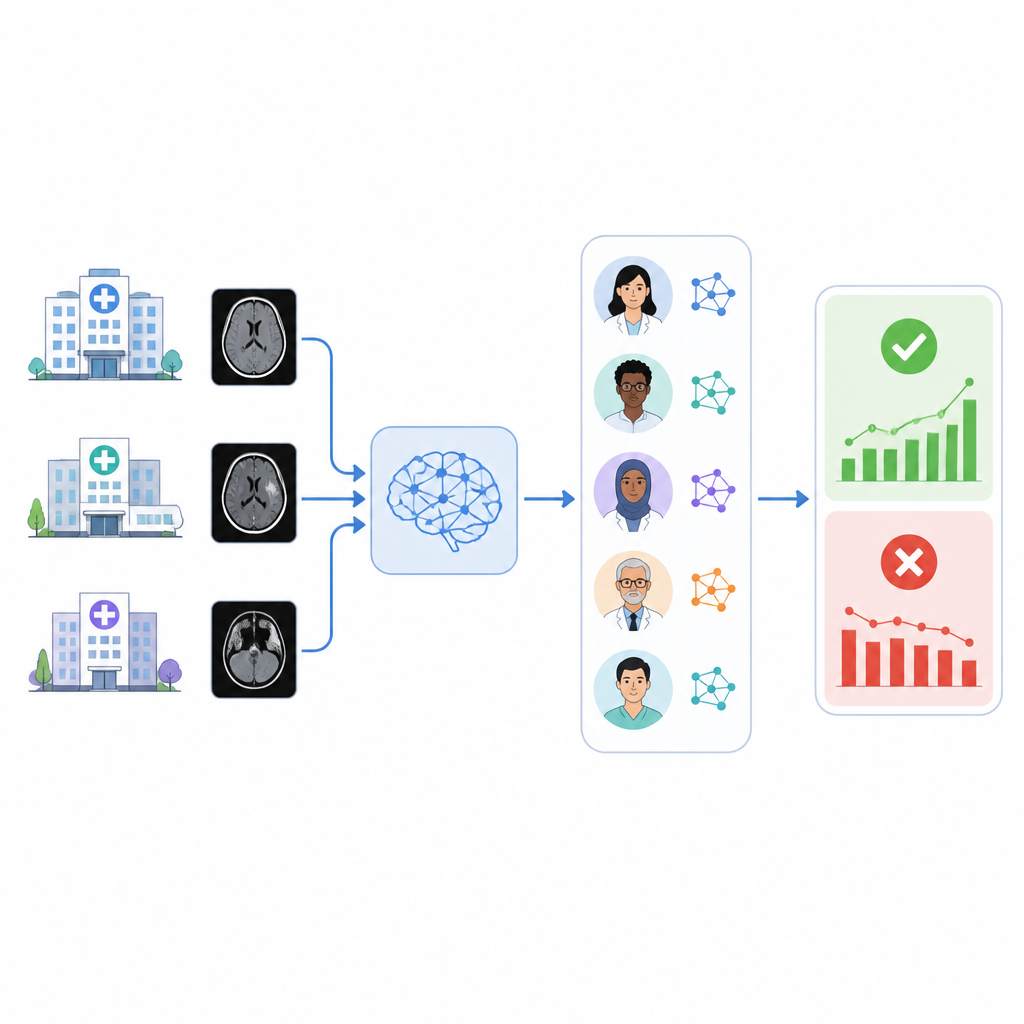
Sjukhus vänder sig i allt högre grad till artificiella intelligensverktyg för att uppmärksamma akuta tillstånd på medicinska skanningar, till exempel blödningar i hjärnan. Men dessa verktyg kan tyst tappa i noggrannhet över tid, och många vårdsystem saknar ett enkelt sätt att kontrollera om de fortfarande fungerar bra på sina egna patienter. Denna studie undersöker om ett team av språkbaserade AI-system automatiskt kan läsa radiologirapporter och i bakgrunden övervaka ett kommersiellt triageverktyg för hjärnblödning.
Utmaningen med att kontrollera medicinsk AI
När ett AI-verktyg väl är installerat på ett sjukhus möter det en föränderlig verklighet: nya skannrar, uppdaterade bildprotokoll och skiftande patientpopulationer kan alla försämra prestanda. Leverantörer erbjuder ofta bara begränsad övervakning, och sjukhusen ansvarar för att upptäcka orättvisor och prestandaförskjutning. Att manuellt granska tusentals hjärnskanningar eller medicinska journaler för att verifiera hur ofta ett AI-verktyg har rätt är alltför tidskrävande för radiologer. Som en praktisk genväg behandlar många grupper det slutliga radiologirapporten som den bästa tillgängliga sammanfattningen av vad som faktiskt påträffades på bilderna, men även då måste någon eller något läsa dessa rapporter.
Använda språkliga AI:er för att läsa radiologirapporter
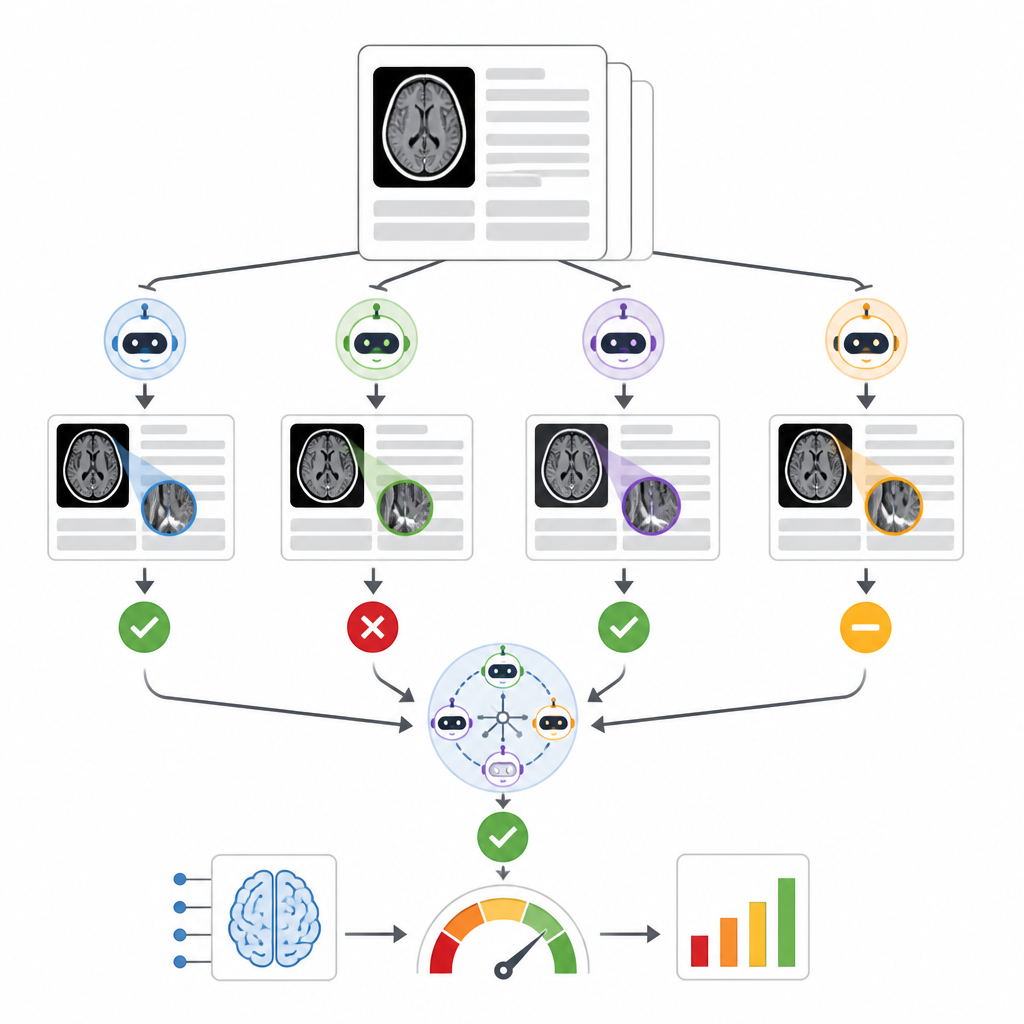
Författarna byggde ett system kallat RADAR som lyssnar efter resultat från ett kommersiellt triageverktyg för intrakraniell blödning som användes på nästan 30 000 icke-kontrast CT-huvudskanningar från 14 sjukhus. För varje undersökning hämtar RADAR senare den slutliga radiologirapporten och extraherar endast avsnittet "impression", där radiologen ger slutsatsen. Den korta texten skickas, med samma noggrant formulerade instruktioner, till åtta open source-språkmodeller som körs lokalt samt en säker sjukhusvärdad version av GPT-4o. Varje modell bestämmer helt enkelt om rapporten tydligt beskriver en akut hjärnblödning eller inte, och forskarna beräknar också ett konsensussvar baserat på majoritetsöverenskommelse bland modellerna.
Hur väl AI-läsarna överensstämde med experter
För att bedöma noggrannheten granskade två erfarna radiologer manuellt 1 726 rapportintryck, med särskilt fokus på fall där det ursprungliga triage-AI:t och språkmodellskonsensusen var oense. Oklara eller ofullständiga rapporter sattes åt sidan, vilket lämnade 1 490 tydliga positiva eller negativa fall för hjärnblödning. Bland nio språkmodeller varierade prestandan kraftigt. En liten modell hade svårt och var inte bättre än slumpen, medan en mycket stor modell, Llama3.3:70b, och GPT-4o visade störst förmåga att matcha mänsklig granskning, med stabila resultat både för att upptäcka verkliga blödningar och undvika falska larm. När författarna jämförde olika sätt att kombinera modeller fann de att ensemblemetoder byggda av toppresterande modeller, av alla nio modeller eller av de åtta lokala modellerna i samförstånd gav liknande och robusta bedömningar av det kommersiella triageverktyget, och alla var mer konsekventa än att förlita sig på GPT-4o ensam.
Hantering av verklighetens röriga kliniska text
Studien belyser den röriga verkligheten i klinisk rapportering. Ungefär 14 procent av de granskade rapporterna använde ett språk som var för vagt eller motsägelsefullt för att vare sig människor eller språkmodeller säkert skulle kunna säga om en färsk hjärnblödning var närvarande. Vissa fel uppstod när prompten inte tydligt skiljde blödning inuti skallen från mindre svullnad i hårbotten, vilket visar att även enkla frågor kan göra att automatiska läsare snubblar utan noggrann formulering och löpande kontroller. Större modeller tenderade att prestera bättre överlag, men vissa medelstora open source-modeller klarade sig nästan lika bra, vilket tyder på att design och promptengineering spelar lika stor roll som ren storlek.
Vad detta betyder för framtida AI på sjukhus
Författarna drar slutsatsen att ett litet team av samarbetande språkmodeller kan agera som en panel av expertgranskare och erbjuda sjukhus ett praktiskt, kostnadseffektivt och leverantörsneutralt sätt att hålla koll på bilddiagnostiska AI-verktyg som ger enkla ja- eller nej-beslut. Genom att kontinuerligt läsa rutinmässiga radiologirapporter kan sådana ensemblemetoder hjälpa till att upptäcka när ett triageverktygs prestanda förändras, stödja utredningar av möjlig snedvridning mellan platser eller skannrar och minska behovet av arbetsintensiva manuella revisioner. För vårdsystem erbjuder detta tillvägagångssätt ett sätt att göra befintlig rapporttext till ett alltid aktivt säkerhetsnät för klinisk AI.
Citering: Flanders, A.E., Peng, Y., Prevedello, L. et al. A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool. npj Health Syst. 3, 35 (2026). https://doi.org/10.1038/s44401-026-00100-4
Nyckelord: övervakning av klinisk AI, radiologirapporter, stora språkmodeller, intrakraniell blödning, AI-prestandaförskjutning