Clear Sky Science · es
Un marco de modelos de lenguaje multimodal para evaluar automáticamente el rendimiento de una herramienta clínica de triaje por IA
Por qué esto importa para la atención al paciente
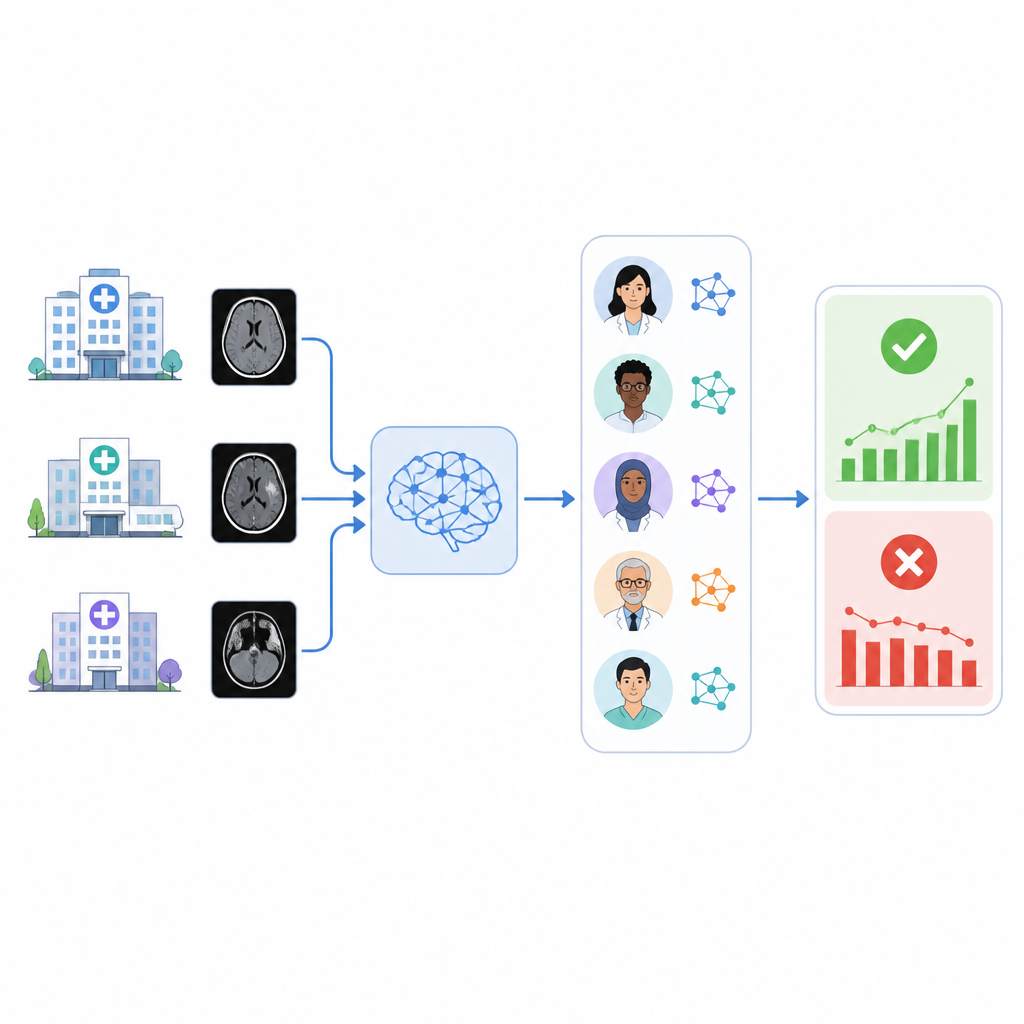
Los hospitales recurren cada vez más a herramientas de inteligencia artificial para señalar condiciones urgentes en exploraciones médicas, como hemorragias cerebrales. Pero estas herramientas pueden perder precisión de forma silenciosa con el tiempo, y muchos sistemas sanitarios no disponen de un método sencillo para comprobar si siguen funcionando bien con sus propios pacientes. Este estudio explora si un equipo de sistemas de IA basados en lenguaje puede leer automáticamente informes de radiología y vigilar en segundo plano una herramienta comercial de triaje de hemorragia cerebral.
El reto de supervisar la IA médica
Una vez que se instala una herramienta de IA en un hospital, se enfrenta a un mundo cambiante: nuevos escáneres, protocolos de imagen actualizados y poblaciones de pacientes distintas pueden deteriorar su rendimiento. Los proveedores a menudo ofrecen supervisión limitada, y los hospitales son responsables de detectar sesgos injustos y deriva en el rendimiento. Revisar manualmente miles de exploraciones cerebrales o registros médicos para verificar con qué frecuencia una herramienta de IA acierta consume demasiado tiempo para los radiólogos. Como atajo práctico, muchos grupos tratan el informe radiológico final como el mejor resumen disponible de lo que realmente se encontró en las imágenes, pero aun así, alguien o algo debe leer esos informes.
Usar IAs de lenguaje para leer informes de radiología
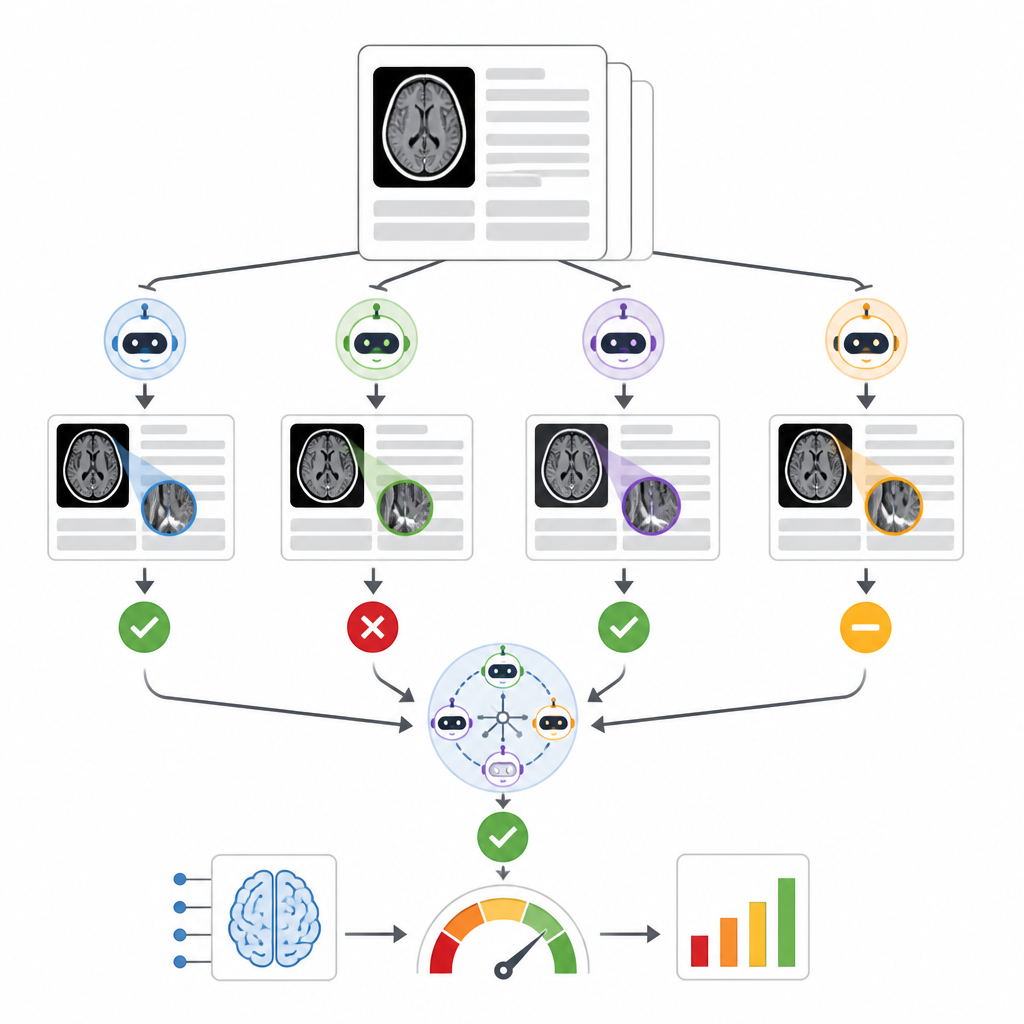
Los autores construyeron un sistema llamado RADAR que escucha los resultados de una herramienta comercial de triaje de hemorragia intracraneal utilizada en casi 30 000 tomografías computarizadas de cabeza sin contraste procedentes de 14 hospitales. Para cada examen, RADAR recupera más tarde el informe radiológico final y extrae únicamente la sección de impresión, donde el radiólogo ofrece la conclusión. Ese texto corto se envía, con las mismas instrucciones cuidadosamente redactadas, a ocho modelos de lenguaje de código abierto ejecutados localmente y a una versión segura alojada en el hospital de GPT-4o. Cada modelo decide simplemente si el informe describe claramente una hemorragia cerebral aguda o no, y los investigadores también calculan una respuesta de consenso basada en la mayoría de acuerdo entre los modelos.
Qué tan bien los lectores de IA coincidieron con los expertos
Para juzgar la precisión, dos radiólogos experimentados revisaron manualmente 1 726 impresiones de informes, centrándose especialmente en los casos en que la IA de triaje original y el consenso de modelos lingüísticos discrepaban. Los informes ambiguos o incompletos se apartaron, dejando 1 490 positivos o negativos claros respecto a hemorragia cerebral. Entre los nueve modelos de lenguaje, el rendimiento varió ampliamente. Un modelo pequeño tuvo dificultades y no fue mejor que el azar, mientras que un modelo muy grande, Llama3.3:70b, y GPT-4o mostraron la mayor capacidad para igualar la revisión humana, con puntuaciones sólidas tanto en detectar hemorragias reales como en evitar falsas alarmas. Cuando los autores compararon diferentes formas de combinar modelos, encontraron que ensamblajes construidos a partir de los mejores, de los nueve modelos completos o de los ocho modelos locales en consenso producían evaluaciones similares y robustas de la herramienta comercial de triaje, y todos fueron más consistentes que confiar únicamente en GPT-4o.
Manejar la complejidad del mundo real en el texto clínico
El estudio destaca la realidad caótica de la elaboración de informes clínicos. Aproximadamente el 14 por ciento de los informes examinados emplearon un lenguaje demasiado vago o contradictorio para que tanto humanos como modelos de lenguaje pudieran afirmar con confianza si había una hemorragia cerebral reciente. Algunos errores surgieron cuando la instrucción no distinguía claramente la hemorragia intracraneal del leve hematoma en el cuero cabelludo, lo que muestra que incluso preguntas sencillas pueden confundir a los lectores automáticos sin una redacción cuidadosa y controles continuos. Los modelos más grandes tendieron a rendir mejor en general, pero algunos modelos de código abierto de tamaño medio se acercaron, lo que sugiere que el diseño y la ingeniería de instrucciones importan tanto como el mero tamaño.
Qué significa esto para la IA hospitalaria futura
Los autores concluyen que un pequeño equipo de modelos de lenguaje colaborativos puede actuar como un panel de revisores expertos, ofreciendo a los hospitales una forma práctica, de bajo coste y neutral frente a proveedores para vigilar herramientas de imagen que dan decisiones simples de sí o no. Leyendo continuamente los informes radiológicos rutinarios, tales ensamblajes pueden ayudar a detectar cuando el rendimiento de una herramienta de triaje deriva, apoyar investigaciones sobre posibles sesgos entre centros o escáneres y reducir la necesidad de auditorías manuales laboriosas. Para los sistemas sanitarios, este enfoque ofrece una forma de convertir el texto de los informes existentes en una red de seguridad siempre activa para la IA clínica.
Cita: Flanders, A.E., Peng, Y., Prevedello, L. et al. A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool. npj Health Syst. 3, 35 (2026). https://doi.org/10.1038/s44401-026-00100-4
Palabras clave: monitorización de IA clínica, informes de radiología, modelos de lenguaje grande, hemorragia intracraneal, deriva del rendimiento de la IA