Clear Sky Science · ar
إطار عمل قائم على نماذج لغوية متعددة الوكلاء لتقييم أداء أداة فرز سريرية قائمة على الذكاء الاصطناعي تلقائيًا
لماذا يهم هذا لرعاية المرضى
تتجه المستشفيات بشكل متزايد إلى أدوات الذكاء الاصطناعي للإشارة إلى الحالات العاجلة في الصور الطبية، مثل النزف داخل المخ. لكن هذه الأدوات قد تفقد دقتها تدريجيًا دون أن يلاحظ أحد، والعديد من أنظمة الرعاية الصحية تفتقر إلى وسيلة سهلة للتحقق مما إذا كانت لا تزال تعمل جيدًا على مرضاها. تستكشف هذه الدراسة ما إذا كان بإمكان فريق من أنظمة الذكاء الاصطناعي القائمة على اللغة قراءة تقارير الأشعة تلقائيًا ومراقبة أداة تجارية لفرز نزف المخ في الخلفية.
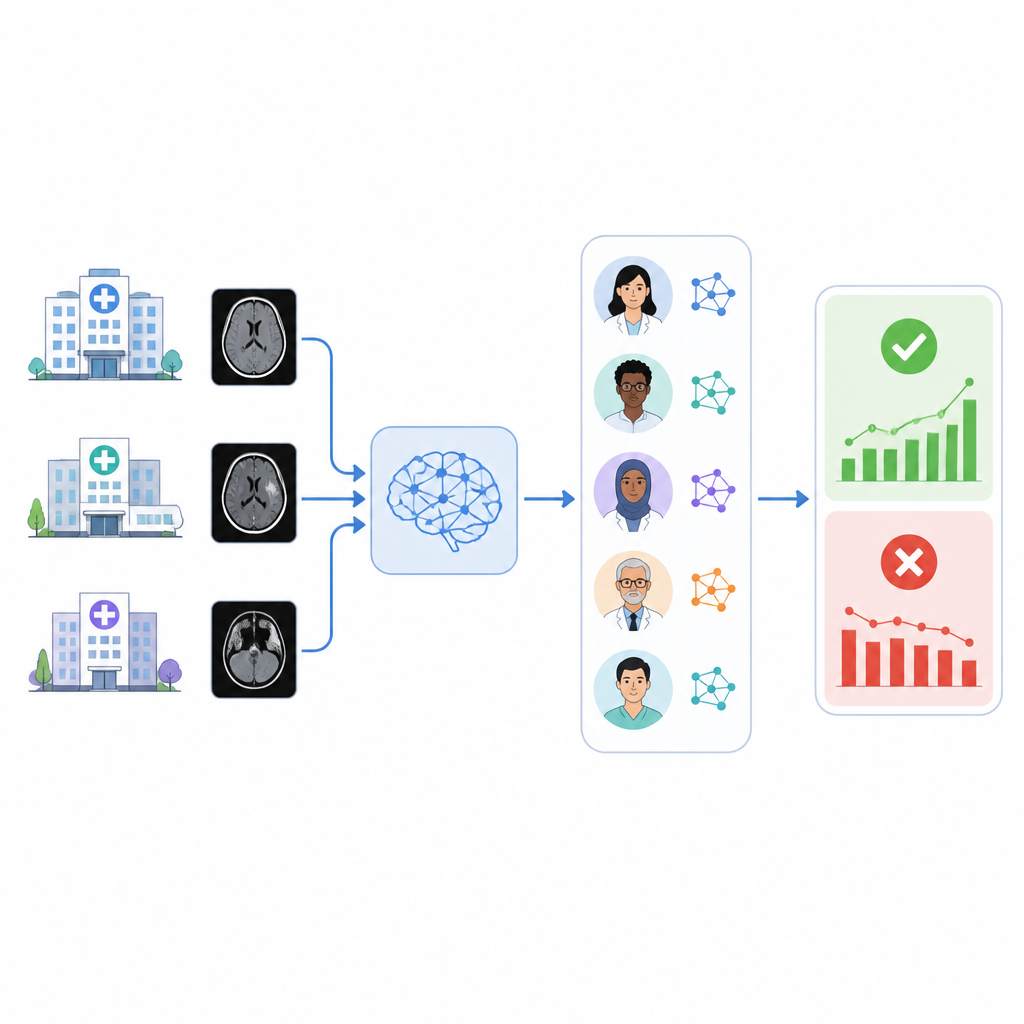
تحدي فحص ذكاء اصطناعي طبي
بمجرد تثبيت أداة ذكاء اصطناعي في مستشفى، فإنها تواجه عالمًا متغيرًا: الأجهزة الجديدة، بروتوكولات التصوير المحدثة، وتغير تركيبة المرضى يمكن أن تؤدي جميعها إلى تآكل الأداء. غالبًا ما يوفر البائعون مراقبة محدودة فقط، وتقع على عاتق المستشفيات مسؤولية اكتشاف الانحيازات وعدم ثبات الأداء. إن مراجعة آلاف الفحوصات الدماغية أو السجلات الطبية يدويًا للتحقق من مدى صحة أداة الذكاء الاصطناعي تستغرق وقتًا طويلاً لعلماء الأشعة. كحل عملي، يعتبر العديد من الفرق أن التقرير النهائي للأشعة هو أفضل ملخص متاح لما عُثر عليه فعليًا في الصور، ولكن حتى في هذه الحالة، يجب على شخص أو نظام أن يقرأ تلك التقارير.
استخدام نماذج لغوية لقراءة تقارير الأشعة
بنى المؤلفون نظامًا يُدعى RADAR يراقب نتائج أداة تجارية لفرز النزف داخل القحف استُخدمت على ما يقرب من 30,000 فحص CT للرأس بدون مادة تباين من 14 مستشفى. لكل فحص، يستخرج RADAR في وقت لاحق التقرير النهائي للأشعة ويقتصر على قسم الاستنتاج، حيث يقدم أخصائي الأشعة الخلاصة. يُرسل ذلك النص القصير، مع نفس التعليمات المكتوبة بعناية، إلى ثمانية نماذج لغوية مفتوحة المصدر تعمل محليًا بالإضافة إلى نسخة GPT-4o المستضافة بأمان في المستشفى. يقرر كل نموذج ببساطة ما إذا كان التقرير يصف بوضوح نزفًا دماغيًا حادًا أم لا، كما يحسب الباحثون إجابة إجماعية اعتمادًا على اتفاق الأغلبية بين النماذج.
مدى توافق قراءات الذكاء الاصطناعي مع خبراء البشر
لتقييم الدقة، راجع طبيبان أشعة ذوا خبرة يدويًا 1,726 خلاصة تقرير، مع تركيز خاص على الحالات التي اختلفت فيها نتيجة أداة الفرز الأصلية للذكاء الاصطناعي مع إجماع النماذج اللغوية. وُضعت التقارير الغامضة أو الناقصة جانبًا، تاركة 1,490 حالة إيجابية أو سلبية واضحة بالنسبة لنزف المخ. عبر تسعة نماذج لغوية، تباين الأداء بشكل واسع. عانى نموذج صغير وكان أداؤه لا يَفُوق الصدفة، بينما أظهر نموذج كبير جدًا، Llama3.3:70b، وGPT-4o أقوى قدرة على مطابقة مراجعة البشر، مع درجات جيدة سواء في اكتشاف النزف الحقيقي أو تجنُّب الإنذارات الكاذبة. عندما قارن المؤلفون طرقًا مختلفة لدمج النماذج، وجدوا أن التجميعات المبنية من أفضل المؤدين، أو من جميع النماذج التسعة، أو من النماذج المحلية الثمانية في إجماع كلّها قدَّمت تقييمات مشابهة وقوية لأداء أداة الفرز التجارية، وكانت كلها أكثر اتساقًا من الاعتماد على GPT-4o وحده.
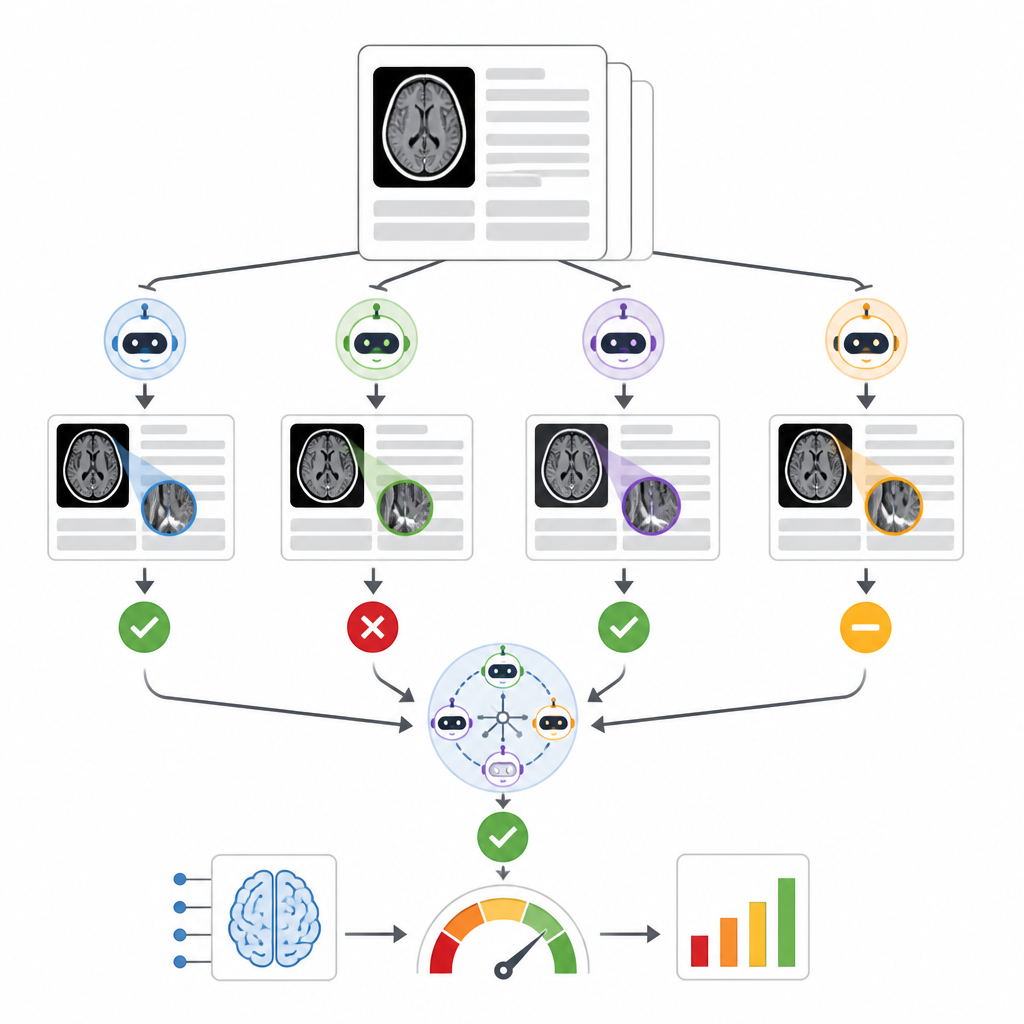
التعامل مع الفوضى الحقيقية في النصوص السريرية
تُبرز الدراسة واقع التقارير السريرية الفوضوي. استخدم نحو 14 بالمئة من التقارير التي فُحصت لغة غامضة أو متضاربة للغاية بحيث لا يمكن للبشر أو النماذج اللغوية الجزم بوجود نزف دماغي جديد. نشأت بعض الأخطاء عندما لم يميز الطلب (البْرومبت) بوضوح بين النزف داخل الجمجمة وتورم طفيف في فروة الرأس، مما يبيّن أن حتى الأسئلة البسيطة قد تُعقِّد القُرَّاء الآليين دون صياغة دقيقة وفحوص مستمرة. ميَّزت النماذج الأكبر أداءً أفضل بشكل عام، لكن بعض النماذج مفتوحة المصدر متوسطة الحجم أدت أداءً مقاربًا، مما يشير إلى أن التصميم وهندسة الطلبات لا يقلان أهمية عن الحجم البحت.
ماذا يعني هذا لمستقبل الذكاء الاصطناعي في المستشفيات
يخلص المؤلفون إلى أن فريقًا صغيرًا من النماذج اللغوية المتعاونة يمكن أن يعمل مثل مجلس من المراجعين الخبراء، مقدمًا للمستشفيات وسيلة عملية ومنخفضة التكلفة ومحايدة البائع لمراقبة أدوات تصويرية للذكاء الاصطناعي تُصدر قرارات نعم أم لا بسيطة. عبر قراءة تقارير الأشعة الروتينية باستمرار، يمكن لمثل هذه التجميعات المساعدة في اكتشاف انحراف أداء أدوات الفرز، ودعم التحقيقات في احتمالية التحيز عبر المواقع أو الأجهزة، وتقليل الحاجة إلى عمليات تدقيق يدوية مرهقة. بالنسبة لأنظمة الرعاية الصحية، يوفّر هذا النهج طريقة لتحويل نصوص التقارير القائمة إلى شبكة أمان دائمة التشغيل للذكاء الاصطناعي السريري.
الاستشهاد: Flanders, A.E., Peng, Y., Prevedello, L. et al. A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool. npj Health Syst. 3, 35 (2026). https://doi.org/10.1038/s44401-026-00100-4
الكلمات المفتاحية: مراقبة الذكاء الاصطناعي السريري, تقارير الأشعة, نماذج لغوية كبيرة, نزف داخل القحف, انحراف أداء الذكاء الاصطناعي