Clear Sky Science · en
A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool
Why this matters for patient care
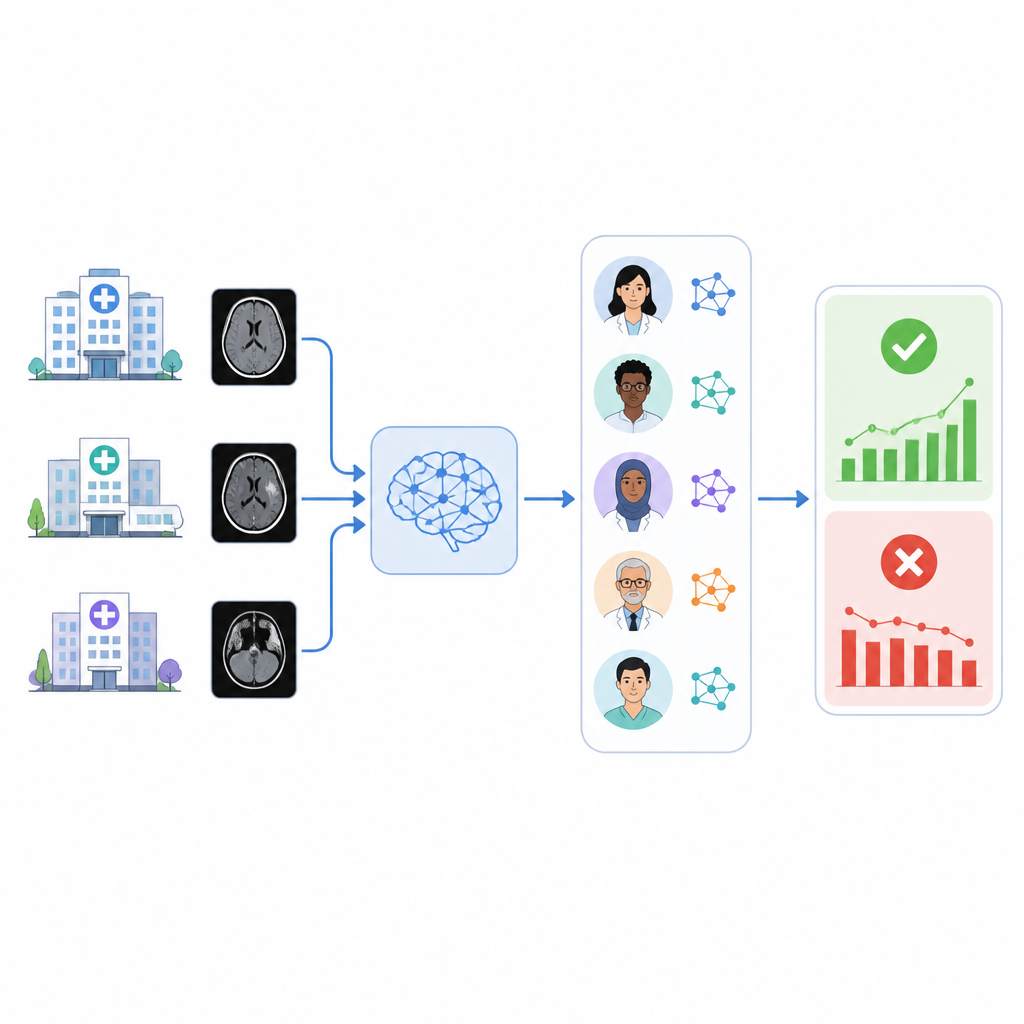
Hospitals are increasingly turning to artificial intelligence tools to flag urgent conditions on medical scans, such as bleeding in the brain. But these tools can quietly lose accuracy over time, and many health systems lack an easy way to check whether they are still working well on their own patients. This study explores whether a team of language-based AI systems can automatically read radiology reports and keep watch over a commercial brain bleed triage tool in the background.
The challenge of checking medical AI
Once an AI tool is installed in a hospital, it faces a changing world: new scanners, updated imaging protocols, and shifting patient populations can all erode performance. Vendors often provide only limited monitoring, and hospitals are responsible for detecting unfair biases and performance drift. Manually reviewing thousands of brain scans or medical records to verify how often an AI tool is right is far too time consuming for radiologists. As a practical shortcut, many groups treat the final radiology report as the best available summary of what was truly found on the images, but even then, someone or something still has to read those reports.
Using language AIs to read radiology reports
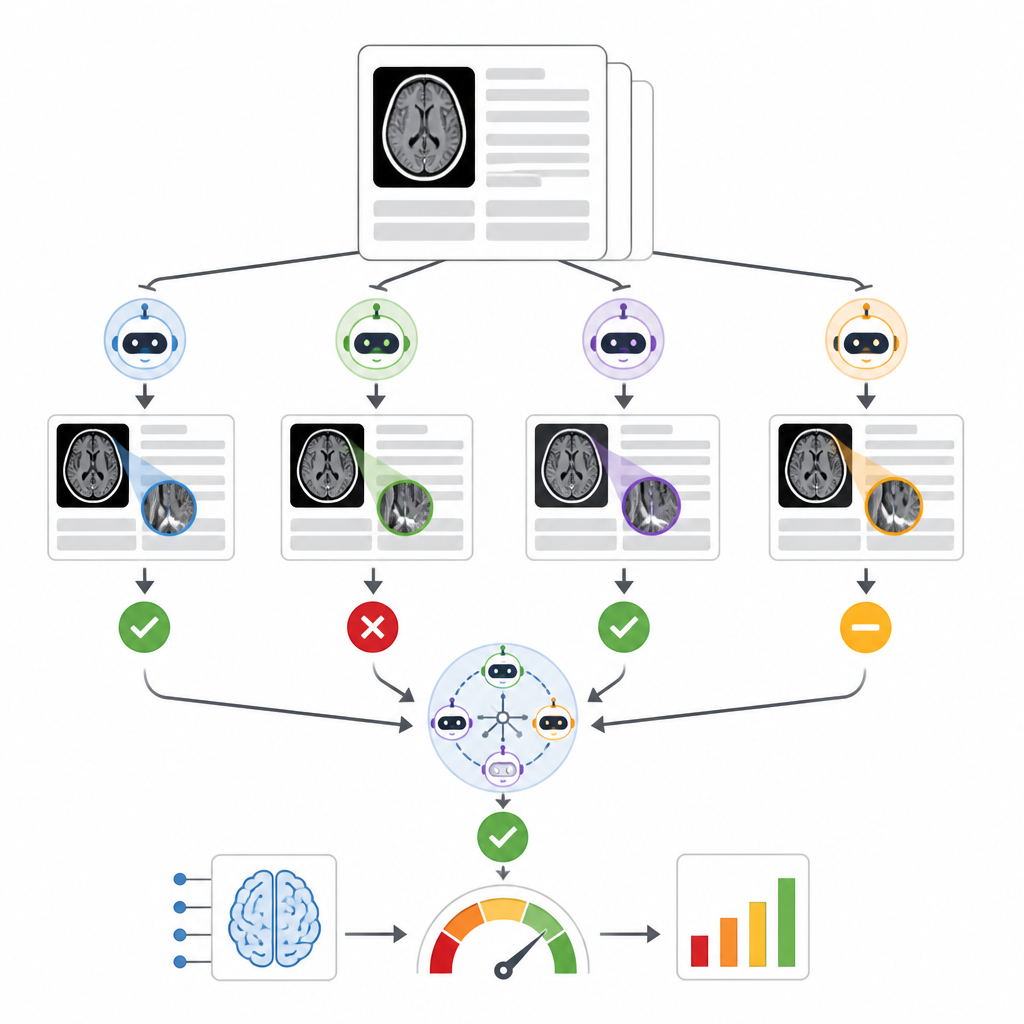
The authors built a system called RADAR that listens for results from a commercial intracranial hemorrhage triage tool used on almost 30,000 non-contrast head CT scans from 14 hospitals. For each exam, RADAR later pulls the final radiology report and extracts only the impression section, where the radiologist gives the bottom line. That short text is sent, with the same carefully written instructions, to eight open-source language models running locally plus a secure hospital-hosted version of GPT-4o. Each model simply decides whether the report clearly describes an acute brain bleed or not, and the researchers also compute a consensus answer based on majority agreement among models.
How well the AI readers agreed with experts
To judge accuracy, two experienced radiologists manually reviewed 1,726 report impressions, focusing especially on cases where the original triage AI and the language model consensus disagreed. Ambiguous or incomplete reports were set aside, leaving 1,490 clear positives or negatives for brain bleed. Across nine language models, performance varied widely. A small model struggled and was no better than chance, while a very large model, Llama3.3:70b, and GPT-4o showed the strongest ability to match human review, with solid scores on both detecting real bleeds and avoiding false alarms. When the authors compared different ways of combining models, they found that ensembles built from the top performers, from all nine models, or from the eight local models in consensus all produced similar and robust assessments of the commercial triage tool, and all were more consistent than relying on GPT-4o alone.
Handling real-world messiness in clinical text
The study highlights the messy reality of clinical reporting. About 14 percent of the examined reports used language that was too vague or conflicted for either humans or language models to confidently say whether a fresh brain bleed was present. Some errors arose when the prompt did not clearly distinguish bleeding inside the skull from minor scalp swelling, showing that even simple questions can trip up automated readers without careful wording and ongoing checks. Larger models tended to perform better overall, but some medium-sized open-source models did nearly as well, suggesting that design and prompt engineering matter as much as sheer size.
What this means for future hospital AI
The authors conclude that a small team of collaborating language models can act like a panel of expert reviewers, offering hospitals a practical, low-cost, and vendor-neutral way to keep tabs on imaging AI tools that output simple yes or no decisions. By continuously reading routine radiology reports, such ensembles can help detect when a triage tool’s performance drifts, support investigations into possible bias across sites or scanners, and reduce the need for laborious manual audits. For health systems, this approach offers a way to turn existing report text into an always-on safety net for clinical AI.
Citation: Flanders, A.E., Peng, Y., Prevedello, L. et al. A multi-agent large language model framework to automatically assess performance of a clinical AI Triage tool. npj Health Syst. 3, 35 (2026). https://doi.org/10.1038/s44401-026-00100-4
Keywords: clinical AI monitoring, radiology reports, large language models, intracranial hemorrhage, AI performance drift