Clear Sky Science · zh
一种以数据为中心的方法,用于检测和缓解儿科心理健康文本中的人口统计偏差
这项研究对家庭的重要性
随着越来越多的医生借助人工智能(AI)来识别心理健康问题的早期迹象,一个关键问题浮现:这些工具对所有儿童是否同样准确?本研究仔细审视了AI如何解读医生笔记以预测儿童和青少年的焦虑——并发现女生,尤其是青春期少女,更可能被漏诊。研究人员随后提出了一种实用方法,使这些系统更公平,同时保留有价值的医疗信息。
在压力重重的一代中日益上升的焦虑
近年儿童和青少年的焦虑与抑郁显著增加,在COVID-19疫情期间临床显著焦虑症状的发生率几乎翻倍。医疗体系面临压力:全面评估耗时,需要家长、教师和当事青少年的参与,并且需要受过专门训练的临床医生。AI提供了一种可能的辅助——通过扫描临床人员已经撰写的自由文本笔记,快速筛查大量患者。但如果这些笔记中存在隐性偏见,而AI模型只是从中学习,技术可能会在不知不觉中加剧现有的不平等,而非缓解它们。
研究团队如何在真实医院记录中研究偏差
研究人员利用了2009年至2022年间辛辛那提儿童医院超过130万名患者的电子健康记录。从中他们关注了大约73,000名最终被诊断为焦虑的5至15岁儿童,并为每名患者匹配了一个在年龄、性别和临床病史上相似但未被诊断为焦虑的儿童。对于每个孩子,他们收集了在首次焦虑诊断前至少一个月内最多25条最近的医生和护士笔记,并使用现代语言模型Clinical‑BigBird学习文本与后续焦虑之间的模式。然后他们分别检验模型在男孩和女孩、以及不同种族群体中的表现,采用了公平性研究中常用的错误率指标。
女孩及其他群体出了什么问题
跨年龄组来看,AI模型的整体准确率中等——约61%——但更深入的分析显示出一个一致且令人担忧的模式。对于女孩,模型的准确率约低4个百分点,产生大约9%更多的假阴性,这意味着焦虑的女孩更经常被判定为没有焦虑。模型对女孩的预测也更常表现为“不确定”,处于临界范围。团队检查基础文本时发现,关于男孩的笔记平均约长500字,而且用于描述男孩和女孩的词汇集仅部分重叠,尤其在最小与最大年龄段更为明显。这些差异很可能反映了儿童就诊的科室差异(例如男孩可能更多出现在神经科或胃肠科,而女孩更多在普通或发展儿科)以及这些科室的临床记录方式,而非焦虑的真实生物学差异。
在不丢失病史的情况下清理文本
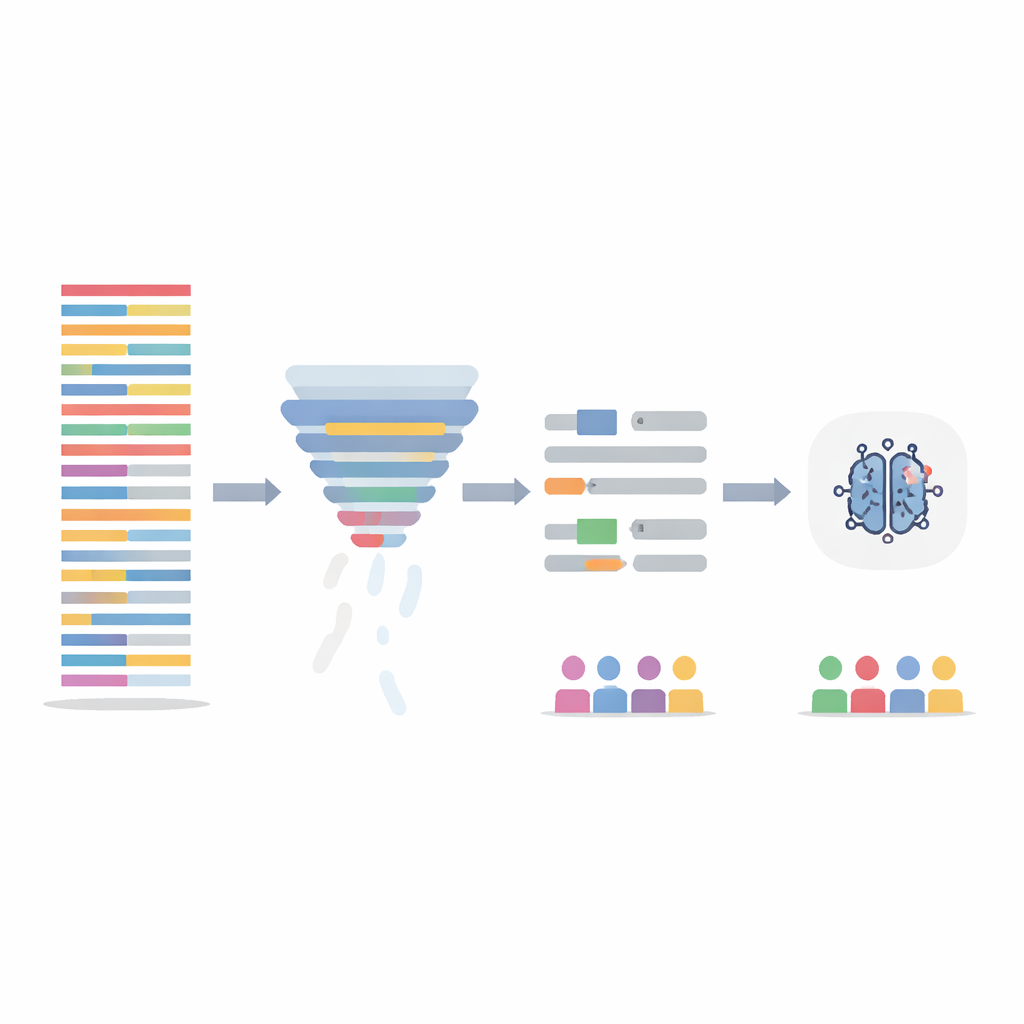
研究团队没有改变AI模型本身,而是将注意力放在以两种方式清理训练数据。首先,他们使用信息过滤步骤,对每句子按其在整个数据集中词语的信息量进行评分,然后删除信息量最少的20%。这可以缩短冗长重复的笔记,并平衡各患者间的信息密度。第二,他们针对明显带有性别色彩的语言——姓名和代词——进行处理,自动将其替换为中性占位符和性别中性代词,以避免模型将“他”或“她”作为线索。这两步单独和组合均被测试,模型在被修改的笔记上重新训练,但评估则使用原始未处理的测试笔记。
在不牺牲实用性的情况下获得更公平的结果
使用清理后数据的模型在整体准确率上表现与原模型相当或略优,但在更公平对待不同群体方面表现更好。尤其是句子过滤方法,将男孩与女孩之间漏诊焦虑的差距最多缩小了约三分之一,并减少了女孩额外的不确定性。当两种方法结合时,也有助于减轻不同种族群体间的差异。使用解释性工具的额外检查表明,去偏后模型对性别相关词的依赖减少,更多依赖诸如“表现为”或“主诉”之类具有临床意义的上下文词,这表明决策过程更为健康。
这对未来儿童医疗中的AI意味着什么
研究得出结论:用于儿科心理健康的AI工具容易受到根源于护理记录方式而非生物学的偏差影响。通过系统地过滤低价值句子并中和带性别色彩的语言,研究人员展示了有可能在不降低性能的前提下减少这些不公平差距。尽管这项工作仍是概念验证,需要在其他模型和医院中进一步测试,但它为让AI辅助筛查对女孩和其他可能被忽视的群体更公平,提供了一个具体的以数据为中心的方案。
引用: Ive, J., Bondaronek, P., Yadav, V. et al. A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text. Commun Med 6, 221 (2026). https://doi.org/10.1038/s43856-026-01480-2
关键词: 儿科焦虑, 临床文本偏差, 人工智能公平性, 电子健康记录, 心理健康筛查