Clear Sky Science · it
Un approccio incentrato sui dati per rilevare e mitigare i bias demografici nel testo sulla salute mentale pediatrica
Perché questa ricerca conta per le famiglie
Man mano che sempre più medici ricorrono all’intelligenza artificiale (IA) per segnalare i primi segnali di problemi di salute mentale, sorge una domanda cruciale: questi strumenti sono ugualmente accurati per tutti i bambini? Questo studio esamina da vicino come l’IA interpreti le note cliniche per prevedere l’ansia nei bambini e negli adolescenti—e mette in luce che le ragazze, in particolare le adolescenti, hanno maggiori probabilità di non essere individuate. I ricercatori propongono quindi un metodo pratico per rendere questi sistemi più equi senza eliminare informazioni mediche preziose.
Una crescente preoccupazione in una generazione sotto stress
L’ansia e la depressione nei bambini e negli adolescenti sono aumentate marcatamente negli ultimi anni, con tassi di sintomi d’ansia clinicamente significativi quasi raddoppiati durante la pandemia di COVID-19. I sistemi sanitari sono sotto pressione: le valutazioni approfondite richiedono tempo, coinvolgono genitori, insegnanti e i giovani stessi, e necessitano di clinici con formazione specializzata. L’IA offre un possibile aiuto—screening rapidi di un gran numero di pazienti scansionando i testi liberi che i clinici già scrivono. Ma se quelle note nascondono bias, e i modelli di IA li apprendono semplicemente, la tecnologia potrebbe peggiorare silenziosamente le disuguaglianze esistenti anziché attenuarle.
Come il team ha studiato il bias in cartelle cliniche reali
I ricercatori hanno utilizzato le cartelle cliniche elettroniche di oltre 1,3 milioni di pazienti visitati al Cincinnati Children’s Hospital tra il 2009 e il 2022. Da questo insieme si sono concentrati su circa 73.000 pazienti giovani, di età compresa tra 5 e 15 anni, che hanno poi ricevuto una diagnosi di ansia, e hanno abbinato ciascuno a un bambino simile senza tale diagnosi (stessa età, stesso sesso, simile storia clinica). Per ogni bambino hanno raccolto fino a 25 delle note più recenti di medici e infermieri scritte almeno un mese prima della prima diagnosi di ansia e hanno usato un moderno modello linguistico, Clinical‑BigBird, per apprendere i pattern che collegano il testo all’ansia successiva. Hanno quindi verificato quanto bene il modello funzionasse separatamente per maschi e femmine e per diversi gruppi razziali, usando tassi di errore standard nella ricerca sull’equità.
Cosa non ha funzionato per le ragazze e altri gruppi
Tra le fasce d’età, l’accuratezza complessiva del modello IA è risultata modesta—intorno al 61 percento—ma un’analisi più approfondita ha mostrato un pattern consistente e preoccupante. Per le ragazze il modello era circa 4 punti percentuali meno accurato e produceva circa il 9 percento in più di falsi negativi, cioè ragazze ansiose venivano più spesso etichettate come non ansiose. Le previsioni del modello per le ragazze risultavano anche più frequentemente “incerte”, aggirandosi in una gamma borderline. Quando il team ha esaminato il testo sottostante, ha trovato che le note sui maschi erano in media circa 500 parole più lunghe e che gli insiemi di parole usati per maschi e femmine si sovrapponevano solo parzialmente, specialmente nelle fasce d’età più giovani e più anziane. Queste differenze probabilmente riflettono dove i bambini vengono visitati (per esempio clinic di neurologia o gastroenterologia per i maschi rispetto alla pediatria generale o dello sviluppo per le femmine) e come i clinici in quei contesti documentano i sintomi, piuttosto che reali differenze biologiche nell’ansia.
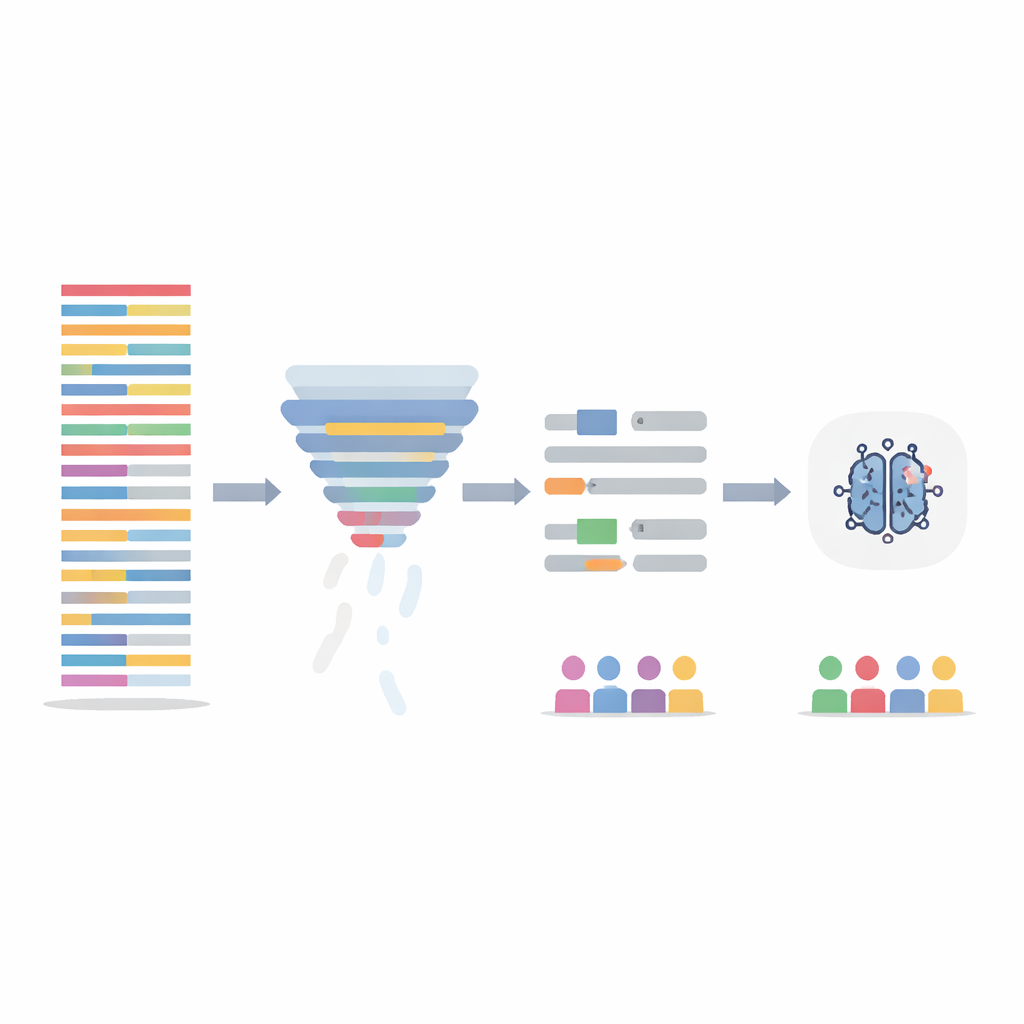
Pulire il testo senza perdere il contenuto clinico
Invece di modificare il modello di IA stesso, il team si è concentrato sulla pulizia dei dati di addestramento in due modi. Primo, hanno usato una fase di filtraggio informativo che assegna a ogni frase un punteggio in base a quanto le sue parole sono informative sull’intero dataset, quindi rimuove il 20 percento meno informativo. Questo accorcia note lunghe e ripetitive e livella la densità informativa tra i pazienti. Secondo, hanno mirato al linguaggio palesemente connotato per genere—nomi e pronomi—sostituendoli automaticamente con segnaposti neutrali e pronomi di genere neutro in modo che il modello non si aggrappi a “lui” o “lei” come indizi. Questi due passaggi sono stati testati singolarmente e in combinazione, e i modelli sono stati riaddestrati sulle note modificate mentre venivano valutati sulle note di test originali e intatte.
Risultati più equi senza sacrificare l’utilità
I modelli addestrati sui dati ripuliti hanno avuto prestazioni complessive simili o leggermente migliori rispetto al modello originale, ma hanno trattato i gruppi in modo più equo. Il metodo di filtraggio delle frasi, in particolare, ha ridotto il divario nelle diagnosi d’ansia mancate tra maschi e femmine fino a circa un terzo e ha diminuito l’incertezza aggiuntiva osservata per le ragazze. Quando i due metodi sono stati combinati, hanno anche contribuito a ridurre le disparità tra gruppi razziali. Un controllo aggiuntivo con uno strumento di spiegazione ha mostrato che, dopo la de‑biasing, il modello si basava meno su parole legate al genere e più su parole di contesto clinicamente significative come “si presenta” o “lamenta”, suggerendo un processo decisionale più sano.
Cosa significa per il futuro dell’IA nella cura dei bambini
Lo studio conclude che gli strumenti di IA per la salute mentale pediatrica sono vulnerabili a bias radicati non nella biologia, ma nel modo e nel luogo in cui le cure sono documentate. Filtrando sistematicamente le frasi a basso valore informativo e neutralizzando il linguaggio connotato per genere, i ricercatori dimostrano che è possibile ridurre queste ingiuste disparità senza degradare le prestazioni. Pur essendo ancora un proof of concept e necessitando di test con altri modelli e ospedali, offre una ricetta concreta, incentrata sui dati, per rendere lo screening assistito dall’IA più equo per le ragazze e altri gruppi che altrimenti potrebbero essere trascurati.
Citazione: Ive, J., Bondaronek, P., Yadav, V. et al. A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text. Commun Med 6, 221 (2026). https://doi.org/10.1038/s43856-026-01480-2
Parole chiave: ansia pediatrica, pregiudizio nei testi clinici, equità nell'IA, cartelle cliniche elettroniche, screening della salute mentale