Clear Sky Science · es
Un enfoque centrado en los datos para detectar y mitigar el sesgo demográfico en textos de salud mental pediátrica
Por qué esta investigación importa para las familias
A medida que más médicos recurren a la inteligencia artificial (IA) para detectar signos tempranos de problemas de salud mental, surge una pregunta crítica: ¿estas herramientas son igual de precisas para todos los niños? Este estudio examina con detalle cómo la IA interpreta las notas de los médicos para predecir la ansiedad en niños y adolescentes y revela que las niñas, en especial las adolescentes, tienen más probabilidades de pasar desapercibidas. Los investigadores proponen luego una forma práctica de hacer estos sistemas más justos sin perder información médica valiosa.
Preocupación creciente en una generación estresada
La ansiedad y la depresión en niños y adolescentes han aumentado drásticamente en los últimos años, con tasas de síntomas de ansiedad clínicamente significativos que casi se duplicaron durante la pandemia de COVID-19. Los sistemas de salud están bajo presión: las evaluaciones exhaustivas requieren tiempo, implican a padres, profesores y a los propios jóvenes, y precisan clínicos con formación especializada. La IA ofrece una posible ayuda: rastrear rápidamente grandes volúmenes de pacientes analizando el texto libre que los clínicos ya registran. Pero si esas notas contienen sesgos ocultos, y los modelos de IA simplemente aprenden de ellas, la tecnología podría empeorar silenciosamente las desigualdades existentes en lugar de aliviarlas.
Cómo el equipo estudió el sesgo en registros hospitalarios reales
Los investigadores utilizaron historias clínicas electrónicas de más de 1,3 millones de pacientes atendidos en el Cincinnati Children’s Hospital entre 2009 y 2022. De ese conjunto se centraron en unos 73.000 pacientes jóvenes de 5 a 15 años que acabaron recibiendo un diagnóstico de ansiedad, y emparejaron a cada uno con un niño similar sin ese diagnóstico (misma edad, mismo sexo, historial clínico parecido). Para cada niño recopilaron hasta 25 de las notas más recientes de médicos y enfermeras escritas al menos un mes antes del primer diagnóstico de ansiedad y usaron un modelo de lenguaje moderno, Clinical‑BigBird, para aprender patrones que vincularan el texto con la ansiedad posterior. Después evaluaron el rendimiento del modelo por separado para niños y niñas y para diferentes grupos raciales, usando tasas de error estándar en investigación sobre equidad.
Qué salió mal para las niñas y otros grupos
En todos los grupos de edad, la precisión global del modelo de IA fue modesta—alrededor del 61 por ciento—pero un análisis más profundo mostró un patrón consistente y preocupante. Para las niñas, el modelo fue aproximadamente 4 puntos porcentuales menos preciso y produjo alrededor de un 9 por ciento más de falsos negativos, es decir, las niñas con ansiedad fueron con mayor frecuencia etiquetadas como no ansiosas. Las predicciones del modelo para las niñas también fueron con más frecuencia “inciertas”, situándose en un rango borderline. Al examinar el texto subyacente, encontraron que las notas sobre niños tenían de media unas 500 palabras más y que los conjuntos de palabras usados para niños y niñas coincidían solo parcialmente, especialmente en las franjas de edad más jóvenes y mayores. Estas diferencias probablemente reflejan dónde son atendidos los niños (por ejemplo, consultas de neurología o gastroenterología para niños frente a pediatría general o del desarrollo para niñas) y cómo documentan los clínicos los síntomas en esos entornos, más que diferencias biológicas reales en la ansiedad.
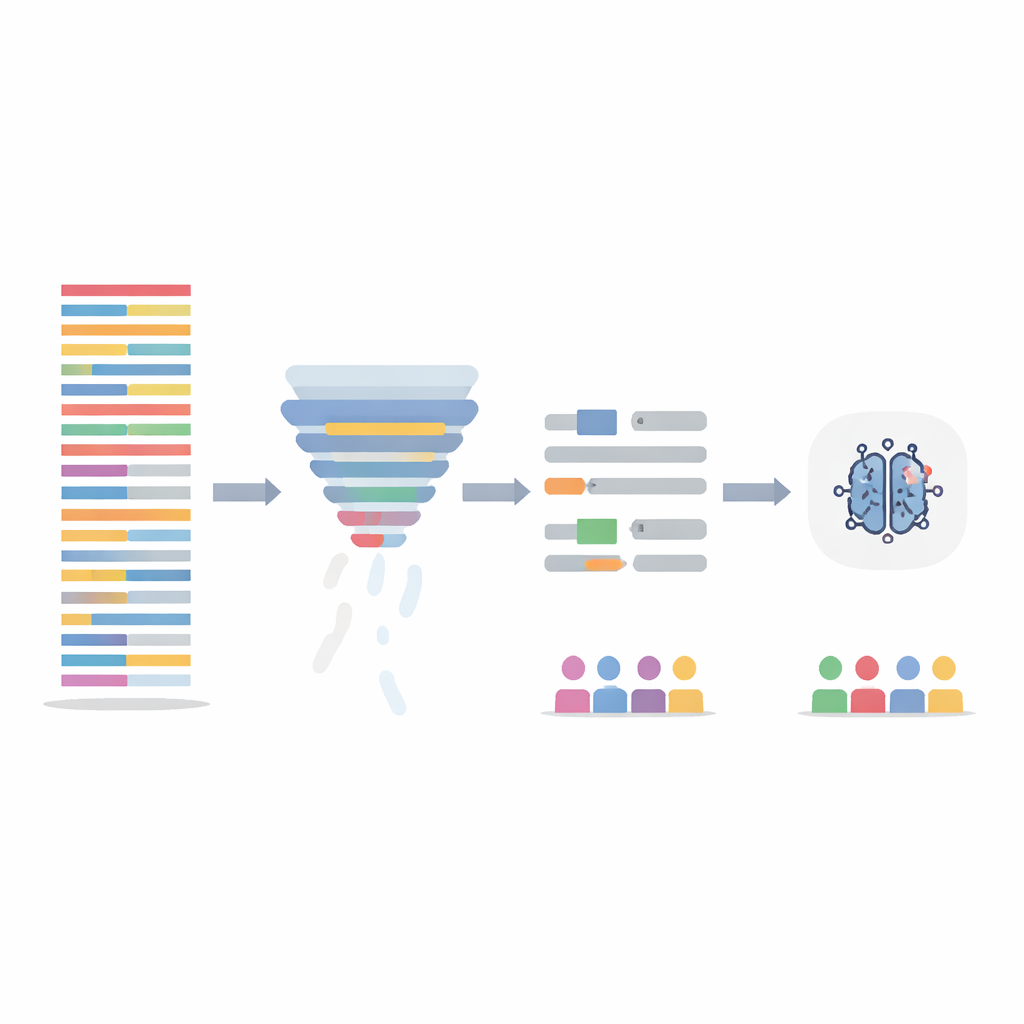
Limpiar el texto sin perder la historia
En lugar de cambiar el propio modelo de IA, el equipo se centró en depurar los datos de entrenamiento de dos maneras. Primero, aplicaron un paso de filtrado de información que puntúa cada frase según lo informativas que son sus palabras en todo el conjunto de datos y elimina el 20 por ciento menos informativo. Esto acorta notas largas y repetitivas y iguala la densidad de información entre pacientes. Segundo, abordaron el lenguaje obviamente marcado por el género—nombres y pronombres—reemplazándolos automáticamente por marcadores neutros y pronombres de género neutro para que el modelo no se ancle en “él” o “ella” como pistas. Estos dos pasos se probaron por separado y en combinación, y los modelos se reentrenaron con las notas alteradas mientras se evaluaban con las notas de prueba originales e intactas.
Resultados más equitativos sin sacrificar utilidad
Los modelos entrenados con los datos limpiados rindieron igual o ligeramente mejor que el modelo original en precisión global, pero hicieron un mejor trabajo tratando a los grupos de forma más equitativa. El método de filtrado de frases, en particular, redujo la brecha en diagnósticos de ansiedad perdidos entre niños y niñas hasta en aproximadamente un tercio y disminuyó la mayor incertidumbre observada para las niñas. Cuando se combinaron los dos métodos, también ayudaron a reducir las disparidades entre grupos raciales. Una comprobación adicional con una herramienta de explicación mostró que, tras la despolarización, el modelo dependía menos de palabras relacionadas con el género y más de palabras de contexto clínicamente significativas como “se presenta” o “motivo de consulta”, lo que sugiere un proceso de decisión más saludable.
Qué significa esto para la futura IA en la atención infantil
El estudio concluye que las herramientas de IA para la salud mental pediátrica son susceptibles a sesgos que no tienen raíz biológica, sino que provienen de cómo y dónde se documenta la atención. Filtrando sistemáticamente frases de bajo valor y neutralizando el lenguaje marcado por el género, los investigadores muestran que es posible reducir estas brechas injustas sin degradar el rendimiento. Aunque el trabajo sigue siendo una prueba de concepto y debe probarse con otros modelos y hospitales, ofrece una receta concreta, centrada en los datos, para hacer que el cribado asistido por IA sea más equitativo para las niñas y otros grupos que podrían pasar desapercibidos.
Cita: Ive, J., Bondaronek, P., Yadav, V. et al. A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text. Commun Med 6, 221 (2026). https://doi.org/10.1038/s43856-026-01480-2
Palabras clave: ansiedad pediátrica, sesgo en textos clínicos, equidad en IA, historias clínicas electrónicas, cribado de salud mental