Clear Sky Science · pl
Data‑centryczne podejście do wykrywania i łagodzenia uprzedzeń demograficznych w tekstach dotyczących zdrowia psychicznego dzieci
Dlaczego to badanie ma znaczenie dla rodzin
W miarę jak coraz więcej lekarzy sięga po sztuczną inteligencję (AI), aby wychwycić wczesne sygnały problemów ze zdrowiem psychicznym, pojawia się kluczowe pytanie: czy narzędzia te działają równiej dla wszystkich dzieci? Badanie to przygląda się, jak AI analizuje notatki lekarzy, by przewidzieć lęk u dzieci i nastolatków — i ujawnia, że dziewczynki, zwłaszcza w okresie dojrzewania, częściej zostają przeoczone. Naukowcy proponują następnie praktyczny sposób na sprawienie, by te systemy były bardziej sprawiedliwe, bez utraty cennych informacji medycznych.
Rosnący niepokój w zestresowanym pokoleniu
Lęk i depresja u dzieci i nastolatków gwałtownie wzrosły w ostatnich latach, a odsetek objawów lękowych o znaczeniu klinicznym niemal się podwoił podczas pandemii COVID-19. Systemy opieki zdrowotnej są pod presją: dokładne oceny zajmują czas, angażują rodziców, nauczycieli i samych młodych ludzi oraz wymagają specjalistycznego przeszkolenia klinicystów. AI oferuje jedną z możliwości — przesiewanie dużej liczby pacjentów szybko poprzez skanowanie notatek pisanych już przez personel. Ale jeśli te notatki zawierają ukryte uprzedzenia, a modele AI uczą się od nich bez korekty, technologia może potajemnie pogłębiać istniejące nierówności zamiast je zmniejszać.
Jak zespół badał uprzedzenia w rzeczywistych dokumentach szpitalnych
Naukowcy wykorzystali elektroniczne rekordy zdrowotne ponad 1,3 miliona pacjentów leczonych w Cincinnati Children’s Hospital w latach 2009–2022. Z tej bazy skupili się na około 73 000 młodych pacjentów w wieku 5–15 lat, którym ostatecznie postawiono diagnozę lęku, i dopasowali każdego z nich do podobnego dziecka bez takiej diagnozy (ten sam wiek, ta sama płeć, zbliżona historia kliniczna). Dla każdego dziecka zgromadzono do 25 najnowszych notatek lekarzy i pielęgniarek napisanych co najmniej miesiąc przed pierwszą diagnozą lęku i użyto nowoczesnego modelu językowego, Clinical‑BigBird, aby nauczyć wzorców łączących tekst z późniejszym wystąpieniem lęku. Następnie sprawdzono, jak model działał oddzielnie dla chłopców i dziewczynek oraz dla różnych grup rasowych, używając wskaźników błędów standardowych w badaniach nad sprawiedliwością.
Co poszło nie tak w przypadku dziewczynek i innych grup
W przekroju grup wiekowych ogólna trafność modelu AI była umiarkowana — około 61 procent — ale głębsza analiza ujawniła konsekwentny i niepokojący wzorzec. Dla dziewczynek model był mniej trafny o około 4 punkty procentowe i generował około 9 procent więcej fałszywych negatywów, co oznacza, że dziewczynki z lękiem były częściej oznaczane jako niemające lęku. Przewidywania modelu dla dziewczynek częściej też mieściły się w strefie „niepewności”, oscylując w granicznym zakresie. Po zbadaniu tekstów okazało się, że notatki dotyczące chłopców były średnio o około 500 słów dłuższe, a zbiory słów używanych dla chłopców i dziewczynek pokrywały się tylko częściowo, szczególnie w najniższych i najwyższych przedziałach wiekowych. Różnice te prawdopodobnie odzwierciedlają miejsca, w których dzieci są leczone (na przykład kliniki neurologii czy gastroenterologii dla chłopców vs ogólna pediatria czy pediatria rozwojowa dla dziewczynek) oraz sposób, w jaki klinicyści w tych placówkach dokumentują objawy, a nie rzeczywiste biologiczne różnice w lęku.
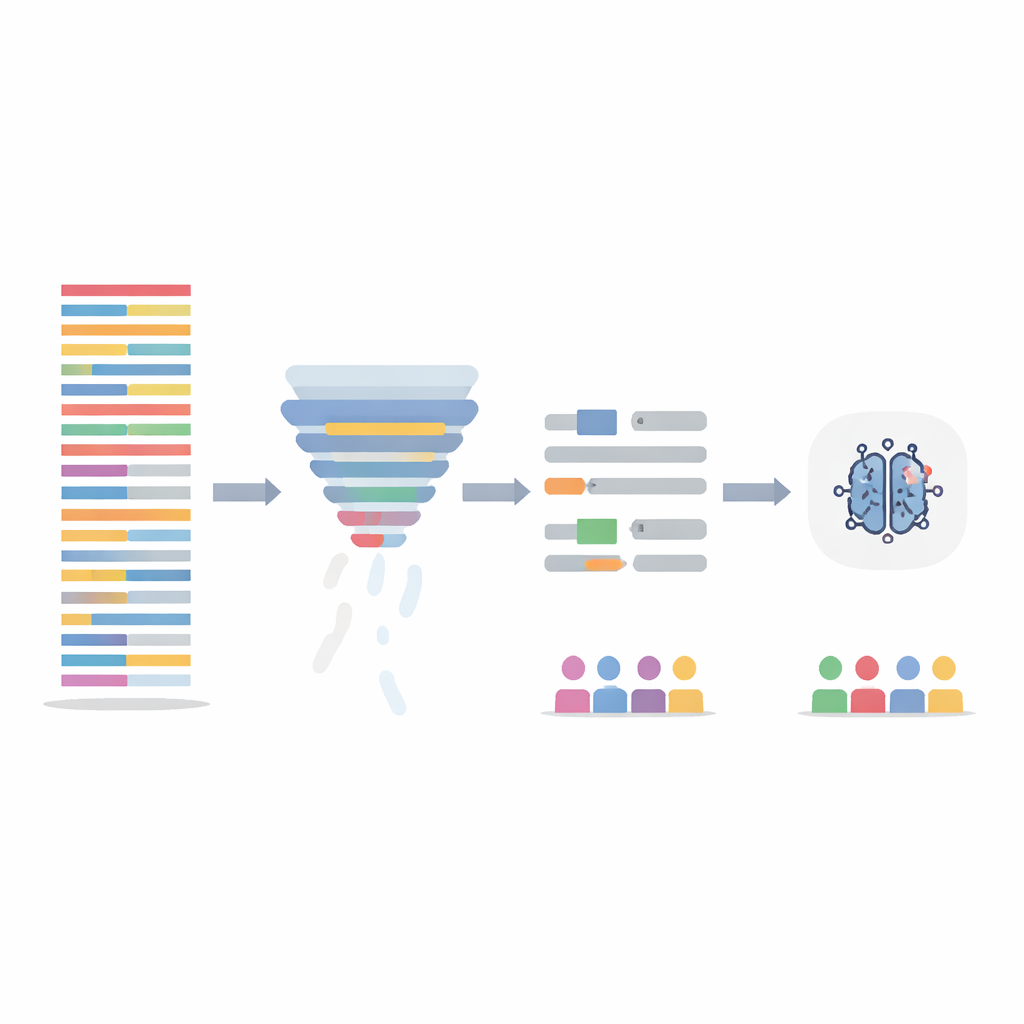
Oczyszczanie tekstu bez utraty istoty
Zamiast modyfikować sam model AI, zespół skupił się na oczyszczaniu danych treningowych na dwa sposoby. Po pierwsze zastosowano etap filtrowania informacji, który ocenia każdą zdanie pod kątem tego, jak informacyjne są jego słowa w całym zbiorze danych, a następnie usuwa najmniej informatywne 20 procent. To skraca długie, powtarzalne notatki i wyrównuje gęstość informacji między pacjentami. Po drugie celowano w oczywiste, zróżnicowane płciowo elementy językowe — imiona i zaimki — automatycznie zamieniając je na neutralne symbole zastępcze i zaimki neutralne płciowo, aby model nie przywiązywał wagi do „on” czy „ona” jako wskazówek. Oba kroki testowano osobno i łącznie, a modele były ponownie trenowane na zmodyfikowanych notatkach, przy jednoczesnej ewaluacji na oryginalnych, niezmienionych notatkach testowych.
Sprawiedliwsze wyniki bez utraty przydatności
Modele trenowane na oczyszczonych danych działały porównywalnie lub nieco lepiej niż model oryginalny pod względem ogólnej trafności, ale lepiej radziły sobie z równym traktowaniem grup. Metoda filtrowania zdań w szczególności zmniejszyła różnicę w przeoczonych diagnozach lęku między chłopcami a dziewczynkami nawet o około jedną trzecią i zredukowała dodatkową niepewność obserwowaną dla dziewczynek. Gdy obie metody połączono, pomogły też zmniejszyć dysproporcje między grupami rasowymi. Dodatkowa weryfikacja przy użyciu narzędzia wyjaśniającego wykazała, że po de‑biasingu model mniej polegał na słowach związanych z płcią, a bardziej na klinicznie istotnych słowach kontekstowych, takich jak „zgłasza” czy „skarga”, co sugeruje zdrowszy proces decyzyjny.
Co to oznacza dla przyszłości AI w opiece nad dziećmi
Badanie wnioskuje, że narzędzia AI do oceny zdrowia psychicznego dzieci są podatne na uprzedzenia zakorzenione nie w biologii, lecz w tym, jak i gdzie dokumentuje się opiekę. Systematycznie filtrując zdania o niskiej wartości informacyjnej i neutralizując język związany z płcią, badacze pokazują, że można zmniejszyć te niesprawiedliwe luki bez pogorszenia wydajności. Choć praca jest na razie dowodem koncepcji i wymaga przetestowania z innymi modelami i w innych szpitalach, oferuje konkretne, data‑centryczne rozwiązanie, które może uczynić wspomagane przez AI przesiewy bardziej równe dla dziewczynek i innych grup, które w przeciwnym razie mogłyby zostać pominięte.
Cytowanie: Ive, J., Bondaronek, P., Yadav, V. et al. A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text. Commun Med 6, 221 (2026). https://doi.org/10.1038/s43856-026-01480-2
Słowa kluczowe: lęk pediatryczny, stronniczość w tekstach klinicznych, sprawiedliwość w AI, elektroniczne rekordy zdrowotne, screening zdrowia psychicznego