Clear Sky Science · en
A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text
Why this research matters for families
As more doctors turn to artificial intelligence (AI) to flag early signs of mental health problems, a critical question arises: are these tools equally accurate for all children? This study looks closely at how AI reads doctors’ notes to predict anxiety in kids and teens—and uncovers that girls, especially adolescents, are more likely to be missed. The researchers then propose a practical way to make these systems fairer without throwing away valuable medical information.
Rising worry in a stressed generation
Anxiety and depression in children and teenagers have increased sharply in recent years, with rates of clinically significant anxiety symptoms nearly doubling during the COVID-19 pandemic. Health systems are under pressure: thorough assessments take time, involve parents, teachers, and young people themselves, and require clinicians with specialized training. AI offers one possible aid—screening large numbers of patients quickly by scanning the free‑text notes that clinicians already write. But if those notes carry hidden biases, and AI models simply learn from them, the technology could quietly worsen existing inequalities instead of easing them.
How the team studied bias in real hospital records
The researchers drew on electronic health records from more than 1.3 million patients seen at Cincinnati Children’s Hospital between 2009 and 2022. From this pool, they focused on roughly 73,000 young patients aged 5 to 15 who eventually received an anxiety diagnosis, and matched each one to a similar child without such a diagnosis (same age, same sex, similar clinical history). For every child, they gathered up to 25 of the most recent doctors’ and nurses’ notes written at least a month before the first anxiety diagnosis and used a modern language model, Clinical‑BigBird, to learn patterns linking text to later anxiety. They then checked how well the model worked separately for boys and girls, and for different racial groups, using error rates that are standard in fairness research.
What went wrong for girls and other groups
Across age groups, the AI model’s overall accuracy was modest—around 61 percent—but a deeper look showed a consistent and worrying pattern. For girls, the model was about 4 percentage points less accurate and produced roughly 9 percent more false negatives, meaning anxious girls were more often labeled as not having anxiety. The model’s predictions for girls were also more frequently “uncertain,” hovering in a borderline range. When the team examined the underlying text, they found that notes about boys were on average about 500 words longer and that the sets of words used for boys and girls overlapped only partially, especially in the youngest and oldest age bands. These differences likely reflect where children are seen (for example, neurology or gastroenterology clinics for boys versus general or developmental pediatrics for girls) and how clinicians in those settings document symptoms, rather than genuine biological differences in anxiety.
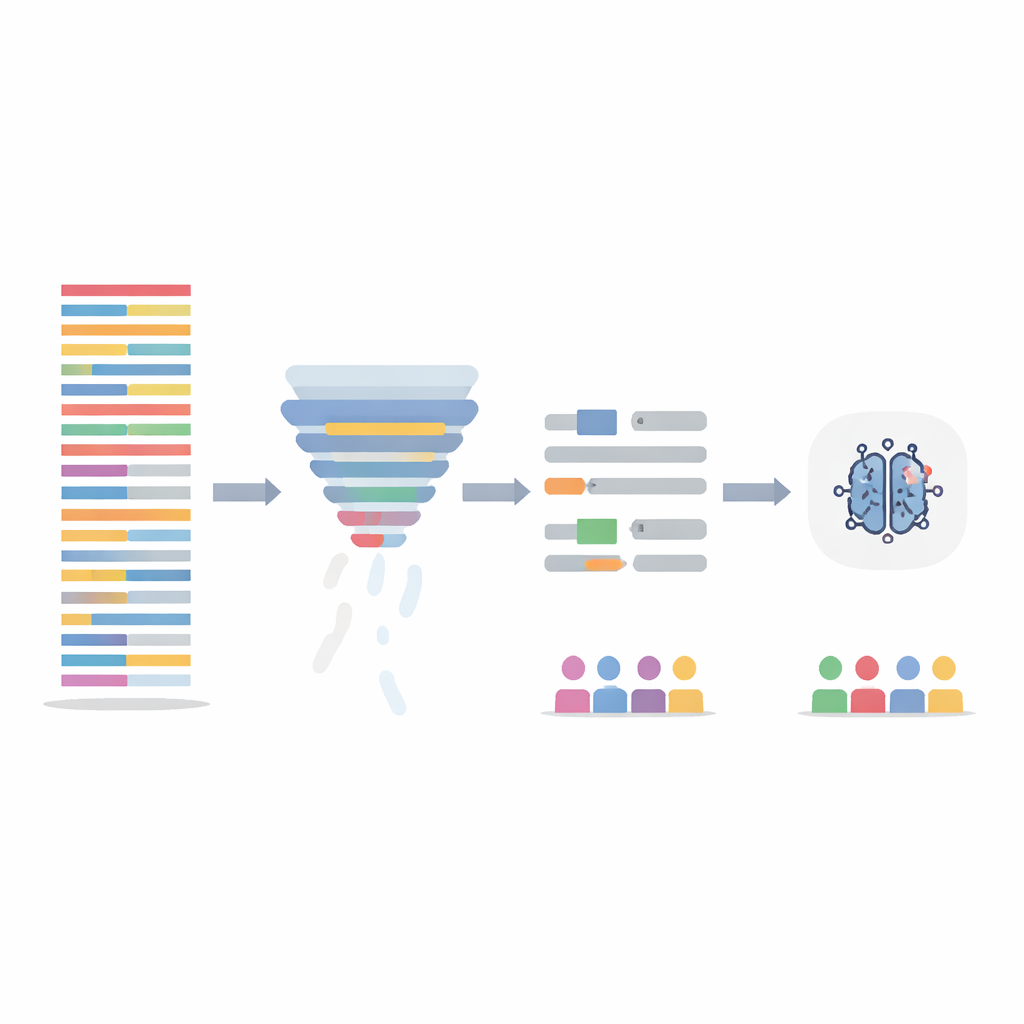
Cleaning up the text without losing the story
Instead of changing the AI model itself, the team focused on cleaning the training data in two ways. First, they used an information‑filtering step that scores each sentence by how informative its words are across the entire dataset, then removes the least informative 20 percent. This shortens long, repetitive notes and evens out how dense the information is across patients. Second, they targeted obviously gendered language—names and pronouns—automatically swapping them for neutral placeholders and gender‑neutral pronouns so that the model would not latch onto “he” or “she” as clues. These two steps were tested alone and in combination, and the models were retrained on the altered notes while being evaluated on the original, untouched test notes.
Fairer results without sacrificing usefulness
The cleaned‑data models performed about as well as, or slightly better than, the original model in overall accuracy, but did a better job at treating groups more equally. The sentence‑filtering method, in particular, cut the gap in missed anxiety diagnoses between boys and girls by up to about one‑third, and reduced the extra uncertainty seen for girls. When the two methods were combined, they also helped lessen disparities across racial groups. An additional check using an explanation tool showed that, after de‑biasing, the model relied less on gender‑related words and more on clinically meaningful context words like “presents” or “complaint,” suggesting a healthier decision process.
What this means for future AI in children’s care
The study concludes that AI tools for pediatric mental health are vulnerable to biases rooted not in biology, but in how and where care is documented. By systematically filtering out low‑value sentences and neutralizing gendered language, the researchers show that it is possible to reduce these unfair gaps without degrading performance. While the work is still a proof of concept and needs to be tested with other models and hospitals, it offers a concrete, data‑centric recipe for making AI‑assisted screening more equitable for girls and other groups who might otherwise be overlooked.
Citation: Ive, J., Bondaronek, P., Yadav, V. et al. A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text. Commun Med 6, 221 (2026). https://doi.org/10.1038/s43856-026-01480-2
Keywords: pediatric anxiety, clinical text bias, fairness in AI, electronic health records, mental health screening