Clear Sky Science · sv
En datacentrerad metod för att upptäcka och mildra demografisk snedvridning i text om pediatrisk psykisk hälsa
Varför denna forskning är viktig för familjer
När fler läkare använder artificiell intelligens (AI) för att upptäcka tidiga tecken på psykiska problem uppstår en avgörande fråga: är dessa verktyg lika träffsäkra för alla barn? Denna studie granskar noggrant hur AI läser läkares anteckningar för att förutsäga ångest hos barn och tonåringar — och avslöjar att flickor, särskilt tonåringar, i högre grad riskerar att bli förbisedda. Forskarna föreslår sedan ett praktiskt sätt att göra systemen mer rättvisa utan att kasta bort värdefull medicinsk information.
Ökad oro i en stressad generation
Ångest och depression hos barn och ungdomar har ökat kraftigt de senaste åren, där andelen med kliniskt signifikanta ångestsymptom nästan fördubblades under COVID‑19‑pandemin. Vårdsystemen är pressade: noggranna bedömningar tar tid, involverar föräldrar, lärare och unga själva, och kräver kliniker med särskild utbildning. AI erbjuder ett möjligt stöd — att screena stora mängder patienter snabbt genom att skanna den fritext som kliniker redan skriver. Men om dessa anteckningar bär på dolda snedvridningar, och AI‑modellerna lär sig dem, kan tekniken tyst förvärra befintliga ojämlikheter i stället för att mildra dem.
Hur teamet studerade snedvridning i verkliga journaler
Forskarna använde elektroniska journaler från mer än 1,3 miljoner patienter som setts på Cincinnati Children’s Hospital mellan 2009 och 2022. Ur detta urval fokuserade de på ungefär 73 000 unga patienter i åldern 5 till 15 år som så småningom fick en ångestdiagnos, och matchade varje sådan patient med ett liknande barn utan diagnos (samma ålder, samma kön, liknande klinisk historia). För varje barn samlade de upp till 25 av de senaste läkar‑ och sjuksköterskeanteckningarna skrivna minst en månad före den första ångestdiagnosen och använde en modern språkmodell, Clinical‑BigBird, för att lära mönster som kopplar text till senare ångest. De kontrollerade sedan hur väl modellen fungerade separat för pojkar och flickor, och för olika rasgrupper, med felmått som är standard i rättviseforskning.
Vad som gick fel för flickor och andra grupper
Över åldersgrupperna var AI‑modellen i stort sett måttligt träffsäker — runt 61 procent — men en djupare analys visade ett konsekvent och oroande mönster. För flickor var modellens träffsäkerhet ungefär 4 procentenheter lägre och den gav cirka 9 procent fler falskt negativa resultat, vilket betyder att ångestsjuka flickor oftare klassificerades som att inte ha ångest. Modellens förutsägelser för flickor var också oftare "osäkra", i ett gränsland. När teamet undersökte underliggande text fann de att anteckningar om pojkar i genomsnitt var cirka 500 ord längre och att ordmängderna som användes för pojkar och flickor bara delvis överlappade, särskilt i de yngsta och äldsta åldersgrupperna. Dessa skillnader speglar sannolikt var barnen ses (till exempel neurologi eller gastroenterologi för pojkar jämfört med allmän eller utvecklingspediatrik för flickor) och hur kliniker i dessa miljöer dokumenterar symtom, snarare än verkliga biologiska skillnader i ångest.
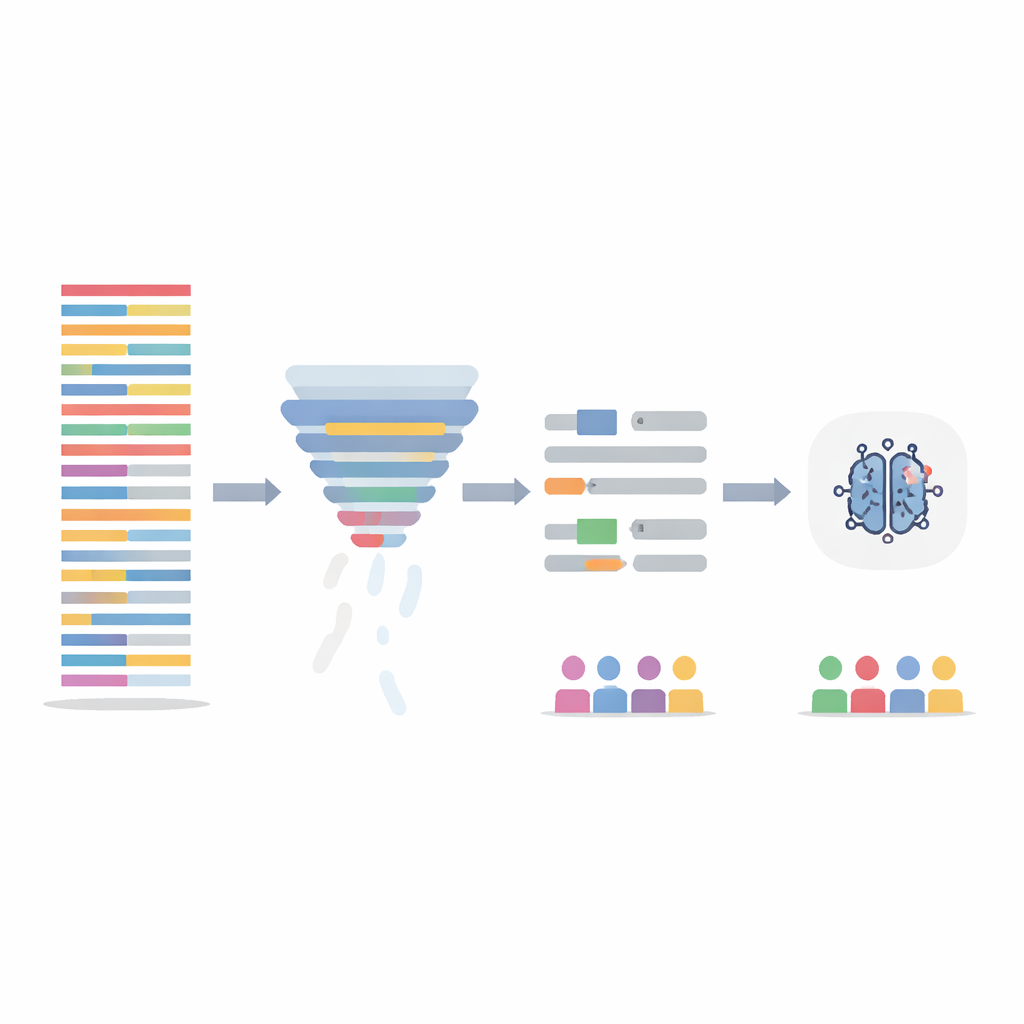
Rensa texten utan att tappa berättelsen
I stället för att ändra själva AI‑modellen fokuserade teamet på att rensa träningsdata på två sätt. Först använde de ett informationsfiltrerande steg som poängsätter varje mening efter hur informativa dess ord är över hela datasetet, och tar sedan bort de minst informativa 20 procenten. Det förkortar långa, repetitiva anteckningar och jämnar ut hur tät informationen är över patienter. För det andra riktade de in sig på uppenbart könade uttryck — namn och pronomen — och ersatte dem automatiskt med neutrala platshållare och könsneutrala pronomen så att modellen inte skulle låsa sig vid "han" eller "hon" som ledtrådar. Dessa två steg testades var för sig och i kombination, och modellerna tränades om på de ändrade anteckningarna medan de utvärderades på de ursprungliga, orörda testanteckningarna.
Rättvisare resultat utan att offra användbarhet
Modellerna som tränades på rensad data presterade ungefär lika bra som, eller något bättre än, originalmodellen i total träffsäkerhet, men klarade sig bättre när det gällde att behandla grupper mer jämlikt. Särskilt meningsfiltreringsmetoden minskade klyftan i missade ångestdiagnoser mellan pojkar och flickor med upp till omkring en tredjedel och reducerade den extra osäkerheten som sågs för flickor. När de två metoderna kombinerades bidrog de även till att minska skillnader mellan rasgrupper. En extra kontroll med ett förklaringsverktyg visade att modellen, efter av‑biasning, förlitade sig mindre på könsrelaterade ord och mer på kliniskt meningsfulla kontextord som "presenterar" eller "klagomål", vilket tyder på ett sundare beslutsunderlag.
Vad detta betyder för framtida AI i barnhälsovård
Studien drar slutsatsen att AI‑verktyg för pediatrisk mental hälsa är sårbara för snedvridningar som inte grundar sig i biologi utan i hur och var vård dokumenteras. Genom att systematiskt filtrera bort låg‑värdesmeningar och neutralisera könade uttryck visar forskarna att det är möjligt att minska dessa orättvisa klyftor utan att försämra prestandan. Arbetsmetoden är fortfarande ett proof of concept och behöver testas med andra modeller och på andra sjukhus, men den erbjuder ett konkret, datacentrerat recept för att göra AI‑stödd screening mer rättvis för flickor och andra grupper som annars riskerar att förbises.
Citering: Ive, J., Bondaronek, P., Yadav, V. et al. A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text. Commun Med 6, 221 (2026). https://doi.org/10.1038/s43856-026-01480-2
Nyckelord: pediatrisk ångest, snedvridning i klinisk text, rättvisa i AI, elektroniska journaler, screening av mental hälsa