Clear Sky Science · tr
Çocuk ruh sağlığı metinlerinde demografik önyargıyı tespit etme ve hafifletmeye veri‑merkezli bir yaklaşım
Bu araştırma aileler için neden önemli
Daha fazla hekim, ruhsal sağlık sorunlarının erken işaretlerini belirlemek için yapay zekâya (YZ) yöneldikçe kritik bir soru ortaya çıkıyor: Bu araçlar tüm çocuklar için eşit derecede doğru mu? Bu çalışma, hekim notlarını YZ’nin çocuk ve ergenlerde anksiyeteyi tahmin etmek için nasıl okuduğunu yakından inceliyor—ve kızların, özellikle ergenlerin, daha sık gözden kaçırılma eğiliminde olduğunu ortaya koyuyor. Araştırmacılar daha sonra bu sistemleri değerli tıbbi bilgileri atmak zorunda kalmadan daha adil hâle getirecek pratik bir yöntem öneriyorlar.
Stresli bir kuşakta artan kaygı
Çocuklar ve ergenlerde anksiyete ile depresyon son yıllarda keskin biçimde arttı; klinik açıdan anlamlı anksiyete belirtilerinin oranları COVID‑19 pandemisi sırasında neredeyse iki katına çıktı. Sağlık sistemleri baskı altında: kapsamlı değerlendirmeler zaman alır, ebeveynleri, öğretmenleri ve gençlerin kendilerini kapsar ve uzman eğitimli klinisyenler gerektirir. YZ, klinisyenlerin zaten yazdığı serbest metin notlarını tarayarak büyük hasta gruplarını hızlıca taramak için bir yardım sunuyor. Ancak bu notlar gizli önyargılar taşıyorsa ve YZ modelleri bunlardan öğreniyorsa, teknoloji var olan eşitsizlikleri hafifletmek yerine sessizce kötüleştirebilir.
Takımın gerçek hastane kayıtlarındaki önyargıyı inceleme biçimi
Araştırmacılar 2009–2022 yılları arasında Cincinnati Children’s Hospital’da görülen 1,3 milyondan fazla hastanın elektronik sağlık kayıtlarını kullandılar. Bu havuzdan, nihayetinde anksiyete tanısı alan yaklaşık 73.000 yaşları 5–15 arasında çocuk üzerine odaklandılar ve her birini benzer bir tanısı olmayan çocukla (aynı yaş, aynı cinsiyet, benzer klinik geçmiş) eşleştirdiler. Her çocuk için ilk anksiyete tanısından en az bir ay önce yazılmış en fazla 25 adet hekim ve hemşire notunu topladılar ve metni daha sonra anksiyeteyle ilişkilendiren örüntüleri öğrenmek için modern bir dil modeli olan Clinical‑BigBird’ı kullandılar. Ardından modeli erkekler ve kızlar ile farklı ırksal gruplar için ayrı ayrı değerlendirdiler ve adalet araştırmalarında standart olan hata oranlarını kullandılar.
Kızlarda ve diğer gruplarda ne yanlış gitti
Yaş grupları genelinde YZ modelinin genel doğruluğu ılımlıydı—yaklaşık yüzde 61—ancak daha derin bir inceleme tutarlı ve endişe verici bir örüntü ortaya koydu. Kızlar için model yaklaşık 4 puan daha az doğruydu ve yaklaşık yüzde 9 daha fazla yanlış negatif üretiyordu; bu da anksiyeteli kızların daha sık anksiyeteleri yokmuş gibi etiketlendiği anlamına geliyor. Modelin kızlara ilişkin tahminleri ayrıca daha sık “belirsiz” aralıkta kaldı. Elde edilen metni incelediklerinde, erkeklere dair notların ortalama olarak yaklaşık 500 kelime daha uzun olduğunu ve erkeklerle kızlar için kullanılan kelime setlerinin özellikle en genç ve en yaşlı yaş bantlarında yalnızca kısmen örtüştüğünü buldular. Bu farklılıklar muhtemelen çocukların hangi ortamlarda görüldüğünü (örneğin erkekler için nöroloji veya gastroenteroloji klinikleri, kızlar için genel veya gelişimsel pediatri gibi) ve bu ortamlardaki klinisyenlerin semptomları nasıl belgelediğini yansıtıyor; gerçek biyolojik anksiyete farklılıklarını değil.
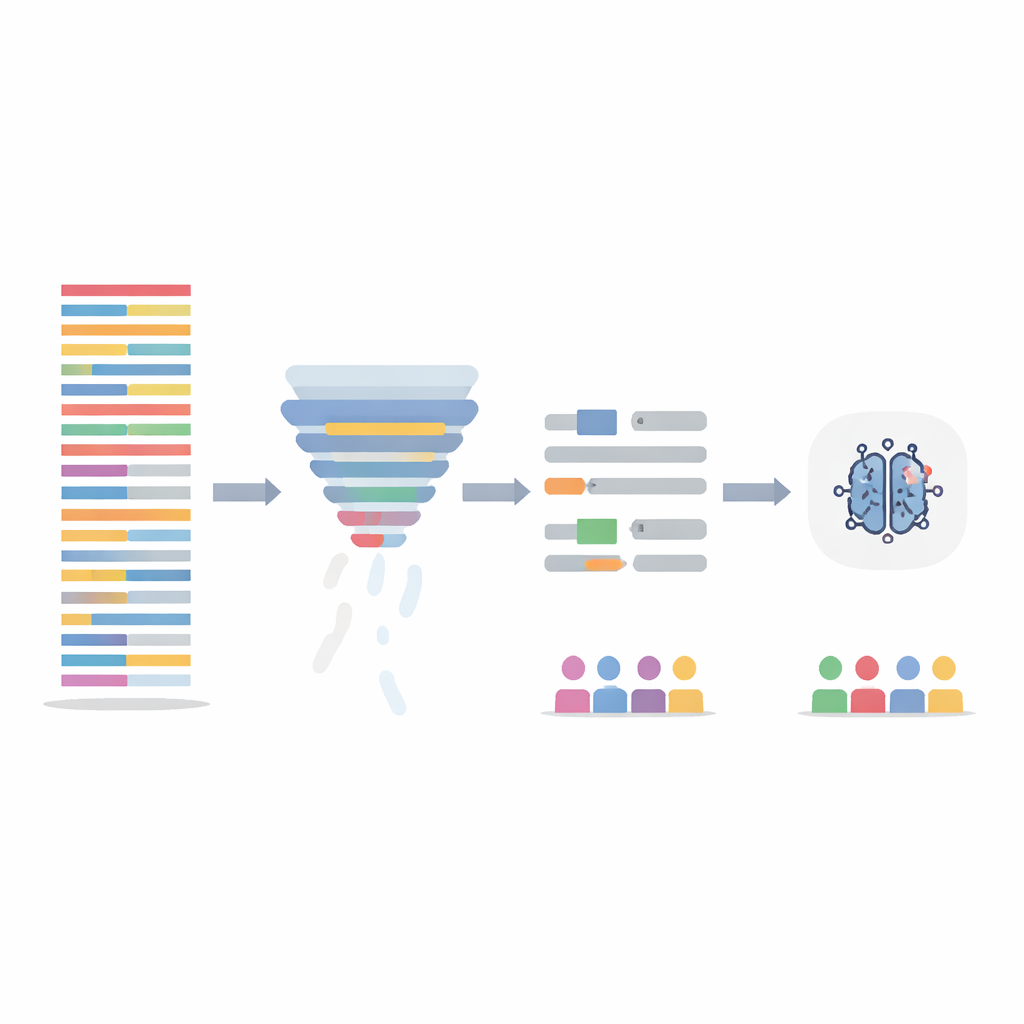
Hikâyeyi kaybetmeden metni temizlemek
Takım YZ modelinin kendisini değiştirmek yerine eğitim verilerini iki şekilde temizlemeye odaklandı. İlk olarak, her cümleyi tüm veri seti üzerinden kelimelerinin ne kadar bilgilendirici olduğuna göre puanlayan bir bilgi‑filtreleme adımı kullandılar ve ardından en az bilgilendirici yüzde 20’yi kaldırdılar. Bu, uzun, tekrar eden notları kısaltıyor ve hastalar arasındaki bilgi yoğunluğunu eşitleyor. İkinci olarak, açıkça cinsiyetlendirilmiş dili—isimler ve zamirler—hedefleyerek bunları otomatik olarak nötr yer tutucularla ve cinsiyetten bağımsız zamirlerle değiştirerek modelin “o (erkek)” veya “o (kız)” gibi ipuçlarına dayanmamasını sağladılar. Bu iki adım ayrı ayrı ve birlikte test edildi ve modeller değiştirilmiş notlar üzerinde yeniden eğitilirken orijinal, dokunulmamış test notları üzerinde değerlendirildi.
Yararlılığından ödün vermeden daha adil sonuçlar
Temizlenmiş verilerle eğitilen modeller genel doğrulukta orijinal modele göre yaklaşık aynı veya biraz daha iyi performans gösterdi, ancak gruplara daha eşit davranmada daha başarılı oldu. Özellikle cümle filtreleme yöntemi, erkeklerle kızlar arasındaki kaçırılan anksiyete tanıları farkını yaklaşık üçte bire kadar azalttı ve kızlarda görülen ekstra belirsizliği düşürdü. İki yöntem birleştirildiğinde, ırksal gruplar arasındaki eşitsizliklerin azalmasına da yardımcı oldu. Bir açıklama aracı ile yapılan ek bir kontrol, önyargı giderildikten sonra modelin cinsiyetle ilişkili kelimelere daha az, “sunuyor” veya “şikâyet” gibi klinik anlamlı bağlam kelimelerine daha fazla dayandığını gösterdi; bu da daha sağlıklı bir karar sürecine işaret ediyor.
Bu, gelecekteki çocuk bakımında YZ için ne anlama geliyor
Çalışma, pediatrik ruh sağlığı için geliştirilen YZ araçlarının biyolojiden değil, bakımın nasıl ve nerede belgelendiğinden kaynaklanan önyargılara açık olduğunu sonucuna varıyor. Düşük değere sahip cümleleri sistematik olarak filtreleyip cinsiyete duyarlı dili nötralize ederek araştırmacılar, performansı düşürmeden bu adaletsiz boşlukları azaltmanın mümkün olduğunu gösteriyor. Çalışma hâlâ bir kavramsal kanıt niteliğinde ve diğer modeller ve hastanelerle test edilmesi gerekiyor, ancak YZ destekli taramayı kızlar ve aksi takdirde göz ardı edilebilecek diğer gruplar için daha eşit hâle getirecek somut, veri‑merkezli bir reçete sunuyor.
Atıf: Ive, J., Bondaronek, P., Yadav, V. et al. A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text. Commun Med 6, 221 (2026). https://doi.org/10.1038/s43856-026-01480-2
Anahtar kelimeler: pediatrik anksiyete, klinik metin önyargısı, Yapay Zekâda adalet, elektronik sağlık kayıtları, ruh sağlığı taraması