Clear Sky Science · de
Datenzentrierter Ansatz zur Erkennung und Minderung demografischer Verzerrungen in pädiatrischen Texten zur psychischen Gesundheit
Warum diese Forschung für Familien wichtig ist
Da immer mehr Ärztinnen und Ärzte auf künstliche Intelligenz (KI) setzen, um frühe Anzeichen psychischer Probleme zu erkennen, stellt sich eine zentrale Frage: Sind diese Werkzeuge für alle Kinder gleichermaßen genau? Diese Studie untersucht genau, wie KI die Notizen von Ärztinnen und Ärzten liest, um Angststörungen bei Kindern und Jugendlichen vorherzusagen — und zeigt auf, dass Mädchen, insbesondere Jugendliche, eher übersehen werden. Die Forschenden schlagen anschließend eine praktikable Methode vor, um diese Systeme gerechter zu machen, ohne wertvolle medizinische Informationen zu verlieren.
Wachsende Sorge in einer gestressten Generation
Angststörungen und Depressionen bei Kindern und Jugendlichen haben in den letzten Jahren stark zugenommen, wobei die Raten klinisch signifikanter Angstsymptome während der COVID-19-Pandemie nahezu sprunghaft anstiegen. Gesundheitssysteme stehen unter Druck: gründliche Bewertungen dauern, binden Eltern, Lehrkräfte und die jungen Menschen selbst ein und erfordern Fachpersonal mit spezieller Ausbildung. KI bietet einen möglichen Helfer — sie kann große Patientenzahlen schnell screenen, indem sie die Freitext-Notizen durchforstet, die Kliniker bereits verfassen. Tragen diese Notizen jedoch verborgene Verzerrungen, und lernen KI-Modelle einfach daraus, könnte die Technologie bestehende Ungleichheiten unbemerkt verschärfen statt sie zu verringern.
Wie das Team Verzerrungen in echten Krankenakten untersuchte
Die Forschenden nutzten elektronische Gesundheitsakten von mehr als 1,3 Millionen Patientinnen und Patienten, die zwischen 2009 und 2022 am Cincinnati Children’s Hospital behandelt wurden. Aus diesem Pool fokussierten sie sich auf rund 73.000 junge Patientinnen und Patienten im Alter von 5 bis 15 Jahren, die schließlich eine Angstdiagnose erhielten, und ordneten jedem von ihnen ein ähnliches Kind ohne solche Diagnose zu (gleiches Alter, gleiches Geschlecht, ähnliche Krankengeschichte). Für jedes Kind sammelten sie bis zu 25 der neuesten Ärztinnen- und Pflegenotizen, die mindestens einen Monat vor der ersten Angstdiagnose verfasst wurden, und verwendeten ein modernes Sprachmodell, Clinical-BigBird, um Muster zu lernen, die Text mit späterer Angst verknüpfen. Anschließend prüften sie, wie gut das Modell getrennt für Jungen und Mädchen sowie für verschiedene Rassengruppen funktionierte, und nutzten dabei Fehlerraten, die in der Fairness-Forschung üblich sind.
Was bei Mädchen und anderen Gruppen schieflief
Über die Altersgruppen hinweg war die Gesamtgenauigkeit des KI-Modells mäßig — etwa 61 Prozent —, doch ein tieferer Blick offenbarte ein konsistentes und beunruhigendes Muster. Bei Mädchen war das Modell etwa 4 Prozentpunkte weniger genau und erzeugte rund 9 Prozent mehr falsch negative Ergebnisse, das heißt ängstliche Mädchen wurden häufiger als nicht ängstlich eingestuft. Die Vorhersagen für Mädchen waren zudem häufiger „unsicher“ und lagen in einer Grenzregion. Bei der Untersuchung der zugrundeliegenden Texte stellten die Forschenden fest, dass Notizen über Jungen im Durchschnitt etwa 500 Wörter länger waren und dass sich die Wortmengen für Jungen und Mädchen nur teilweise überschnitten, besonders in den jüngsten und ältesten Altersgruppen. Diese Unterschiede spiegeln wahrscheinlich wider, wo Kinder behandelt werden (zum Beispiel Neurologie- oder Gastroenterologie-Praxen für Jungen versus Allgemeine oder Entwicklungs-Pädiatrie für Mädchen) und wie Kliniker in diesen Settings Symptome dokumentieren, statt echte biologische Unterschiede in der Angst zu zeigen.
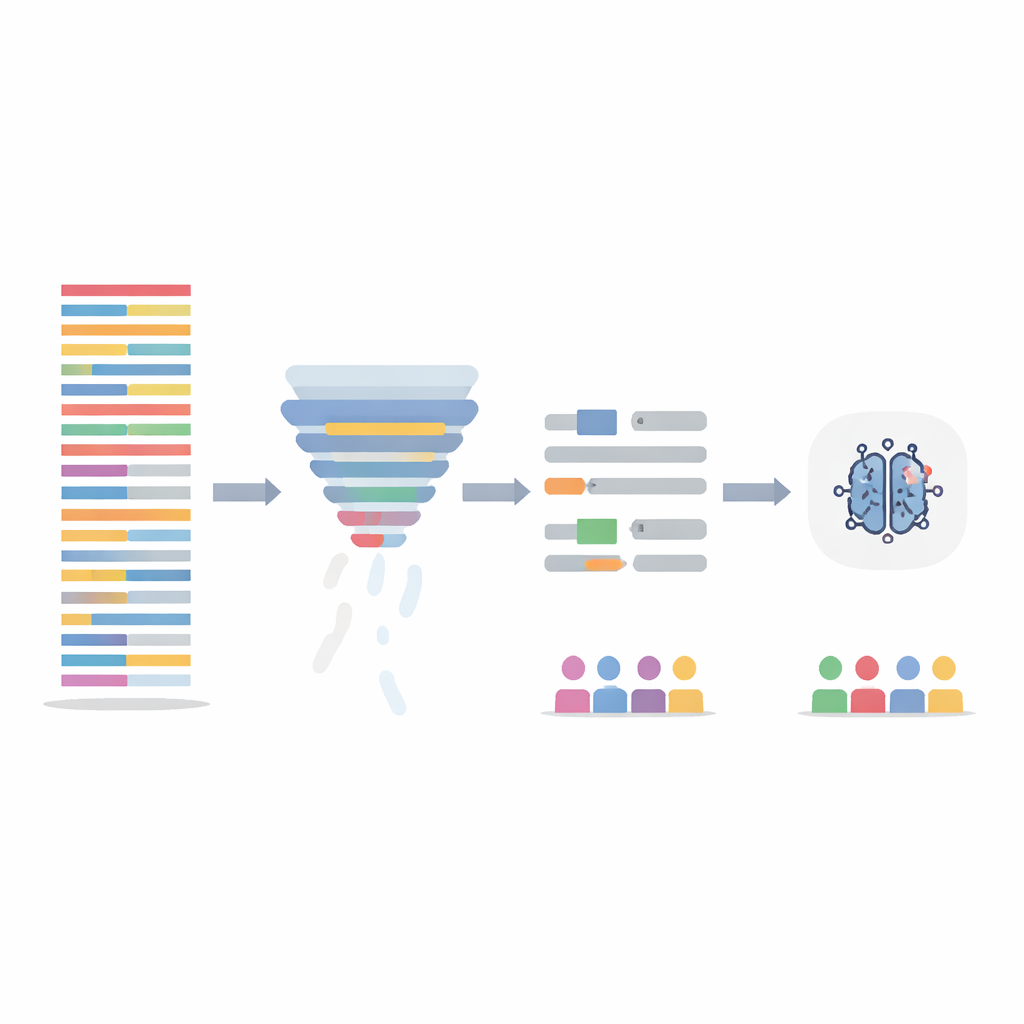
Die Texte bereinigen, ohne die Geschichte zu verlieren
Anstatt das KI-Modell selbst zu verändern, konzentrierte sich das Team auf die Bereinigung der Trainingsdaten auf zwei Arten. Erstens verwendeten sie einen Informationsfilter-Schritt, der jeden Satz danach bewertet, wie informativ seine Wörter über den gesamten Datensatz hinweg sind, und dann die am wenigsten informativen 20 Prozent entfernt. Das kürzt lange, repetitive Notizen und gleicht die Informationsdichte über Patientinnen und Patienten an. Zweitens zielten sie auf offensichtlich geschlechtsspezifische Sprache — Namen und Pronomen — und ersetzten diese automatisch durch neutrale Platzhalter und geschlechtsneutrale Pronomen, damit das Modell nicht an „er“ oder „sie“ als Hinweis anknüpft. Diese beiden Schritte wurden einzeln und in Kombination getestet, und die Modelle wurden auf den veränderten Notizen neu trainiert, während sie auf den ursprünglichen, unveränderten Testnotizen evaluiert wurden.
Fairere Ergebnisse ohne Einbußen bei der Nützlichkeit
Die Modelle mit bereinigten Daten erzielten eine etwa gleich gute oder leicht bessere Gesamtgenauigkeit als das Originalmodell, behandelten Gruppen jedoch gerechter. Insbesondere schnitt die Satzfilter-Methode die Lücke bei übersehenen Angstdiagnosen zwischen Jungen und Mädchen um bis zu etwa ein Drittel kleiner und verringerte die zusätzliche Unsicherheit, die bei Mädchen beobachtet wurde. Als beide Methoden kombiniert wurden, trugen sie außerdem zur Abschwächung von Unterschieden zwischen Rassengruppen bei. Eine zusätzliche Überprüfung mit einem Erklärungswerkzeug zeigte, dass das Modell nach der Entzerrung weniger auf geschlechtsbezogene Wörter und mehr auf klinisch sinnvolle Kontextwörter wie „stellt vor“ oder „Beschwerde“ abstellte, was auf einen gesünderen Entscheidungsprozess hindeutet.
Was das für die zukünftige KI in der Kinderbetreuung bedeutet
Die Studie kommt zu dem Schluss, dass KI-Werkzeuge für die pädiatrische psychische Gesundheit anfällig sind für Verzerrungen, die nicht in der Biologie, sondern in der Dokumentation von Versorgung verankert sind. Durch systematisches Herausfiltern von wenig wertvollen Sätzen und Neutralisieren geschlechtsspezifischer Sprache zeigen die Forschenden, dass sich diese unfairen Lücken verringern lassen, ohne die Leistung zu verschlechtern. Zwar ist die Arbeit noch ein Konzeptnachweis und muss mit anderen Modellen und in anderen Kliniken getestet werden, doch sie bietet ein konkretes, datenorientiertes Rezept, um KI-gestütztes Screening für Mädchen und andere sonst übersehene Gruppen gerechter zu machen.
Zitation: Ive, J., Bondaronek, P., Yadav, V. et al. A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text. Commun Med 6, 221 (2026). https://doi.org/10.1038/s43856-026-01480-2
Schlüsselwörter: pädiatrische Angst, Verzerrung in klinischen Texten, Fairness in KI, elektronische Gesundheitsakten, Screening der psychischen Gesundheit