Clear Sky Science · ru
Данные в центре внимания: выявление и снижение демографического предвзятости в текстах о психическом здоровье детей
Почему это исследование важно для семей
По мере того как всё больше врачей обращаются к искусственному интеллекту (ИИ) для раннего выявления проблем с психическим здоровьем, встает ключевой вопрос: одинаково ли эти инструменты точны для всех детей? В этом исследовании внимательно изучают, как ИИ «читает» врачебные записи, чтобы предсказать тревожные расстройства у детей и подростков, и обнаруживают, что девочек, особенно подростков, чаще пропускают. Авторы затем предлагают практический способ сделать такие системы справедливее, не теряя при этом ценной медицинской информации.
Рост тревожности в поколении под давлением
Тревога и депрессия у детей и подростков резко возросли за последние годы: на период пандемии COVID-19 частота клинически значимых симптомов тревоги почти удвоилась. Системы здравоохранения испытывают нагрузку: полноценные оценки требует времени, участия родителей, учителей и самих детей, а также специалистов с соответствующей подготовкой. ИИ предлагает один из возможных инструментов — быстро скринировать большое количество пациентов, анализируя свободно написанные клиницистами заметки. Но если эти заметки содержат скрытые предубеждения, а модели ИИ просто учатся на них, технология может незаметно усугублять существующие неравенства вместо того, чтобы их уменьшать.
Как команда изучала предвзятость на реальных больничных записях
Исследователи использовали электронные медицинские записи более 1,3 миллиона пациентов, наблюдавшихся в Cincinnati Children’s Hospital с 2009 по 2022 год. Из этой выборки они выделили примерно 73 000 молодых пациентов в возрасте 5–15 лет, у которых впоследствии был установлен диагноз тревожного расстройства, и сопоставили каждого с похожим ребёнком без такого диагноза (того же возраста, того же пола, с похожей клинической историей). Для каждого ребёнка они собрали до 25 последних заметок врачей и медсестёр, написанных не менее чем за месяц до первого диагноза тревоги, и использовали современную языковую модель Clinical‑BigBird, чтобы выявить закономерности, связывающие текст с последующей тревогой. Затем они проверили, насколько хорошо модель работает отдельно для мальчиков и девочек, а также для разных расовых групп, используя показатели ошибок, принятые в исследованиях справедливости.
Что пошло не так для девочек и других групп
В целом по возрастным группам точность модели была умеренной — около 61 процента — но более детальный анализ выявил устойчивую и тревожную закономерность. Для девочек модель была примерно на 4 процентных пункта менее точной и давала примерно на 9 процентов больше ложноотрицательных результатов, то есть тревожных девочек чаще ошибочно помечали как не страдающих тревогой. Предсказания модели для девочек также чаще находились в «неопределённой» пограничной зоне. При изучении самих текстов выяснилось, что заметки о мальчиках в среднем были примерно на 500 слов длиннее, а наборы употребляемых слов для мальчиков и девочек частично совпадали лишь отчасти, особенно в самых младших и старших возрастных группах. Эти различия, вероятно, отражают места, где детей наблюдают (например, неврология или гастроэнтерология для мальчиков против общей или развивающей педиатрии для девочек) и то, как клиницисты в этих отделениях документируют симптомы, а не истинные биологические различия в тревоге.
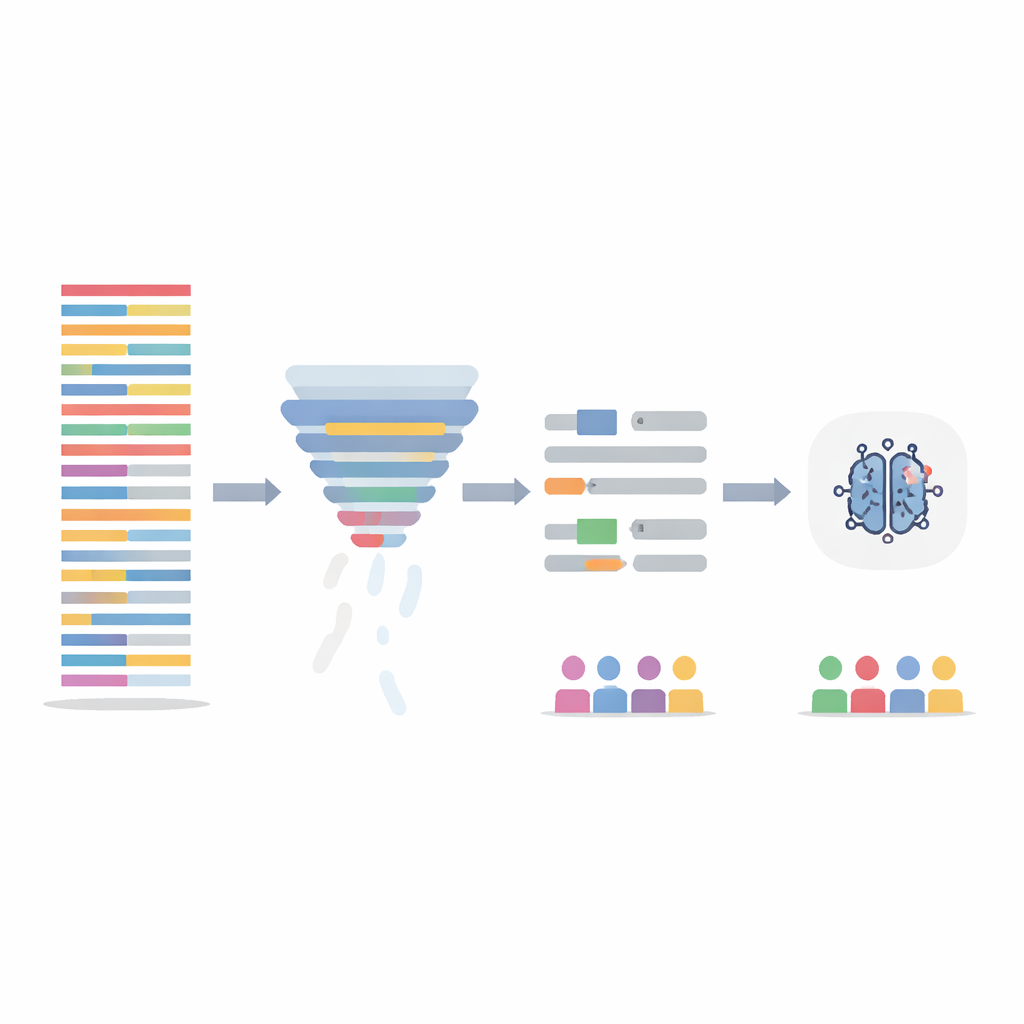
Очистка текста без потери содержания
Вместо изменения самой модели ИИ команда сосредоточилась на очистке обучающих данных двумя способами. Сначала они применили шаг фильтрации информации, который оценивает каждое предложение по тому, насколько информативны содержащиеся в нём слова в пределах всего набора данных, и удаляет наименее информативные 20 процентов. Это укорачивает длинные, повторяющиеся заметки и выравнивает плотность информации между пациентами. Затем они нацелились на очевидно гендерно окрашенный язык — имена и местоимения — автоматически заменяя их нейтральными заполнителями и гендерно-нейтральными местоимениями, чтобы модель не делала выводы по «он» или «она». Эти два шага тестировались по отдельности и в комбинации, а модели переобучали на изменённых заметках при оценке на оригинальных, нетронутых тестовых записях.
Более справедливые результаты без потери пользы
Модели, обученные на очищенных данных, показали примерно такой же или слегка лучше общий уровень точности по сравнению с исходной моделью, но при этом лучше справлялись с равным обращением к группам. Метод фильтрации предложений, в частности, сократил разрыв в пропущенных диагнозах тревоги между мальчиками и девочками примерно на одну треть и уменьшил повышенную неопределённость, наблюдаемую у девочек. При комбинировании двух методов также снизились различия между расовыми группами. Дополнительная проверка с использованием инструмента объяснения показала, что после дебайсинга модель меньше опиралась на гендерно-зависимые слова и больше — на клинически значимые контекстные слова, такие как «появляется» или «жалоба», что указывает на более здравый процесс принятия решений.
Что это означает для будущего ИИ в лечении детей
Исследование делает вывод, что инструменты ИИ для детского психического здоровья уязвимы к предвзятостям, коренящимся не в биологии, а в том, как и где ведётся документация ухода. Систематически фильтруя малоценные предложения и нейтрализуя гендерно окрашенный язык, авторы показывают, что можно уменьшить эти несправедливые разрывы, не ухудшая качество работы. Хотя это пока доказательство концепции, требующее проверки на других моделях и в других больницах, подход даёт конкретный, ориентированный на данные рецепт для того, чтобы скрининг с помощью ИИ был более справедливым для девочек и других групп, которые иначе могли бы оказаться в тени.
Цитирование: Ive, J., Bondaronek, P., Yadav, V. et al. A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text. Commun Med 6, 221 (2026). https://doi.org/10.1038/s43856-026-01480-2
Ключевые слова: тревожность у детей, предвзятость в клинических текстах, справедливость в ИИ, электронные медицинские записи, скрининг психического здоровья