Clear Sky Science · pt
Uma abordagem centrada em dados para detectar e mitigar viés demográfico em textos de saúde mental pediátrica
Por que esta pesquisa importa para as famílias
À medida que mais médicos recorrem à inteligência artificial (IA) para sinalizar sinais precoces de problemas de saúde mental, surge uma pergunta crucial: essas ferramentas são igualmente precisas para todas as crianças? Este estudo examina atentamente como a IA lê as anotações dos médicos para prever ansiedade em crianças e adolescentes — e revela que meninas, especialmente adolescentes, têm maior probabilidade de serem não identificadas. Os pesquisadores então propõem uma forma prática de tornar esses sistemas mais justos sem eliminar informações médicas valiosas.
Preocupação crescente em uma geração estressada
A ansiedade e a depressão em crianças e adolescentes aumentaram acentuadamente nos últimos anos, com taxas de sintomas de ansiedade clinicamente significativos quase dobrando durante a pandemia de COVID-19. Os sistemas de saúde estão sob pressão: avaliações completas demandam tempo, envolvem pais, professores e os próprios jovens, e exigem clínicos com treinamento especializado. A IA oferece uma possível ajuda — triagem de grandes números de pacientes rapidamente ao vasculhar as anotações em texto livre que os clínicos já escrevem. Mas se essas anotações contêm vieses ocultos, e os modelos de IA simplesmente aprendem a partir delas, a tecnologia pode, silenciosamente, piorar desigualdades existentes em vez de aliviá-las.
Como a equipe estudou o viés em prontuários reais
Os pesquisadores usaram prontuários eletrônicos de mais de 1,3 milhão de pacientes atendidos no Cincinnati Children’s Hospital entre 2009 e 2022. Deste conjunto, concentraram-se em cerca de 73.000 pacientes jovens com idades entre 5 e 15 anos que acabaram recebendo um diagnóstico de ansiedade, e emparelhou cada um a uma criança similar sem esse diagnóstico (mesma idade, mesmo sexo, histórico clínico semelhante). Para cada criança, reuniram até 25 das anotações mais recentes de médicos e enfermeiros escritas pelo menos um mês antes do primeiro diagnóstico de ansiedade e usaram um modelo de linguagem moderno, o Clinical-BigBird, para aprender padrões que ligam o texto à ansiedade posterior. Em seguida, avaliaram como o modelo funcionou separadamente para meninos e meninas, e para diferentes grupos raciais, usando taxas de erro que são padrão em pesquisas sobre justiça algorítmica.
O que deu errado para meninas e outros grupos
Em todas as faixas etárias, a acurácia geral do modelo de IA foi modesta — cerca de 61% —, mas uma análise mais profunda mostrou um padrão consistente e preocupante. Para as meninas, o modelo foi cerca de 4 pontos percentuais menos preciso e produziu aproximadamente 9% a mais de falsos negativos, significando que meninas ansiosas foram com mais frequência rotuladas como não ansiosas. As previsões do modelo para meninas também foram mais frequentemente “incertas”, pairando em uma faixa limítrofe. Quando a equipe examinou o texto subjacente, constatou que as anotações sobre meninos tinham, em média, cerca de 500 palavras a mais e que os conjuntos de palavras usados para meninos e meninas se sobrepunham apenas parcialmente, especialmente nas faixas etárias mais jovem e mais velha. Essas diferenças provavelmente refletem onde as crianças são atendidas (por exemplo, clínicas de neurologia ou gastroenterologia para meninos versus pediatria geral ou do desenvolvimento para meninas) e como os clínicos nesses locais documentam sintomas, em vez de diferenças biológicas genuínas na ansiedade.
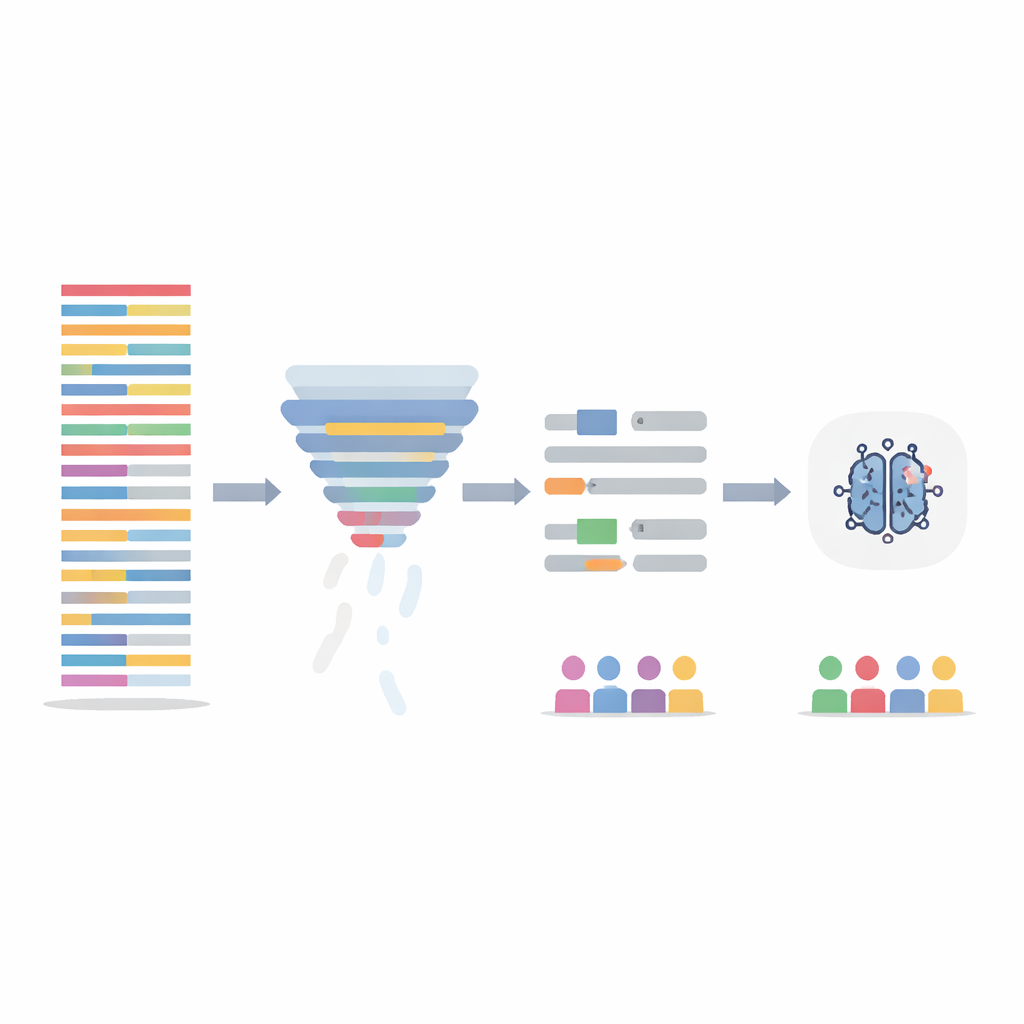
Limpar o texto sem perder a história
Em vez de mudar o próprio modelo de IA, a equipe concentrou-se em limpar os dados de treinamento de duas maneiras. Primeiro, usaram uma etapa de filtragem de informação que pontua cada frase pela quantidade informativa das palavras ao longo de todo o conjunto de dados, removendo depois os 20% menos informativos. Isso reduz notas longas e repetitivas e equaliza o quanto de informação há por paciente. Segundo, direcionaram linguagem obviamente ligada a gênero — nomes e pronomes — substituindo-os automaticamente por marcadores neutros e pronomes de gênero neutro, para que o modelo não se apegasse a “ele” ou “ela” como pistas. Esses dois passos foram testados isoladamente e em combinação, e os modelos foram re-treinados nas anotações alteradas enquanto eram avaliados nas notas de teste originais, intactas.
Resultados mais justos sem sacrificar a utilidade
Os modelos treinados com dados limpos apresentaram desempenho semelhante, ou ligeiramente superior, ao modelo original em acurácia geral, mas fizeram um trabalho melhor em tratar os grupos de forma mais equitativa. O método de filtragem de frases, em particular, reduziu a diferença em diagnósticos de ansiedade perdidos entre meninos e meninas em até cerca de um terço, e diminuiu a incerteza extra observada para meninas. Quando os dois métodos foram combinados, também ajudaram a reduzir disparidades entre grupos raciais. Uma verificação adicional usando uma ferramenta de explicação mostrou que, após a desagregação de vieses, o modelo passou a depender menos de palavras relacionadas ao gênero e mais de termos contextuais clinicamente relevantes como “apresenta” ou “queixa”, sugerindo um processo decisório mais saudável.
O que isso significa para a IA no cuidado infantil
O estudo conclui que ferramentas de IA para saúde mental pediátrica são vulneráveis a vieses enraizados não na biologia, mas em como e onde o cuidado é documentado. Ao filtrar sistematicamente frases de baixo valor e neutralizar linguagem ligada ao gênero, os pesquisadores mostram que é possível reduzir essas lacunas injustas sem degradar o desempenho. Embora o trabalho ainda seja uma prova de conceito e precise ser testado com outros modelos e em outros hospitais, oferece uma receita concreta, centrada em dados, para tornar a triagem assistida por IA mais equitativa para meninas e outros grupos que, de outra forma, poderiam ser negligenciados.
Citação: Ive, J., Bondaronek, P., Yadav, V. et al. A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text. Commun Med 6, 221 (2026). https://doi.org/10.1038/s43856-026-01480-2
Palavras-chave: ansiedade pediátrica, viés em texto clínico, justiça em IA, prontuários eletrônicos, triagem de saúde mental