Clear Sky Science · ar
نهج مركز على البيانات لاكتشاف وتخفيف التحيز الديموغرافي في نصوص الصحة النفسية للأطفال
لماذا يهم هذا البحث للأسر
مع اعتماد مزيد من الأطباء على الذكاء الاصطناعي لكشف العلامات المبكرة لمشكلات الصحة النفسية، يبرز سؤال مهم: هل هذه الأدوات دقيقة على قدم المساواة لجميع الأطفال؟ تبحث هذه الدراسة عن كثب في كيفية قراءة الذكاء الاصطناعي لملاحظات الأطباء للتنبؤ بالقلق لدى الأطفال والمراهقين—وتكشف أن الفتيات، وبالأخص المراهقات، قد تُفوت تشخيصاتهن بصورة أكبر. ثم يقترح الباحثون طريقة عملية لجعل هذه الأنظمة أكثر عدلاً دون التضحية بمعلومات طبية ثمينة.
قلق متصاعد في جيل مضغوط
ازداد القلق والاكتئاب لدى الأطفال والمراهقين بشكل حاد في السنوات الأخيرة، مع تضاعف معدلات الأعراض القلقة ذات الدلالة السريرية تقريباً خلال جائحة كوفيد-19. تواجه أنظمة الرعاية الصحية ضغطاً: التقييمات الشاملة تستغرق وقتاً، وتشمل الآباء والمعلمين والشباب أنفسهم، وتتطلب اختصاصيين مدربين. يقدم الذكاء الاصطناعي مساعدة محتملة—فحص أعداد كبيرة من المرضى بسرعة من خلال مسح النصوص الحرة التي يكتبها الأطباء بالفعل. لكن إذا كانت تلك الملاحظات تحمل تحيزات خفية وتعلمت منها نماذج الذكاء الاصطناعي ببساطة، فقد تساهم التكنولوجيا بهدوء في تفاقم عدم المساواة القائمة عوضاً عن تخفيفها.
كيف درس الفريق التحيز في سجلات المستشفى الحقيقية
استند الباحثون إلى السجلات الصحية الإلكترونية لأكثر من 1.3 مليون مريض تمت معاينتهم في مستشفى سيسيناتي للأطفال بين 2009 و2022. من هذه العينة، ركزوا على نحو 73,000 مريض شاب تتراوح أعمارهم بين 5 و15 سنة حصلوا لاحقاً على تشخيص بالقلق، وطابقوا كل منهم مع طفل مماثل بدون مثل هذا التشخيص (نفس العمر، نفس الجنس، تاريخ سريري مشابه). لجأوا لكل طفل إلى جمع ما يصل إلى 25 من أحدث ملاحظات الأطباء والممرضين المكتوبة قبل شهر واحد على الأقل من أول تشخيص بالقلق، واستخدموا نموذج لغة حديث، Clinical-BigBird، لتعلُّم الأنماط التي تربط النص بالقلق اللاحق. ثم تحققوا من أداء النموذج بشكل منفصل للفتيان والفتيات، وللمجموعات العرقية المختلفة، باستخدام معدلات الخطأ المعيارية في أبحاث العدالة.
ما الذي أخفق بالنسبة للفتيات ومجموعات أخرى
عبر الفئات العمرية، كانت دقة نموذج الذكاء الاصطناعي الإجمالية متواضعة—نحو 61 بالمئة—لكن نظرة أعمق أظهرت نمطاً متسقاً ومقلقاً. بالنسبة للفتيات، كان أداء النموذج أقل بحوالي 4 نقاط مئوية وأنتج نحو 9 بالمئة مزيداً من النتائج السلبية الكاذبة، ما يعني أن الفتيات القلقات وُصِفن في كثير من الأحيان على أنهن غير قلقات. كما كانت توقعات النموذج للفتيات أكثر تردداً في كثير من الأحيان، متذبذبة في نطاق حدودي. عندما فحص الفريق النصوص الأساسية، وجدوا أن الملاحظات المتعلقة بالفتيان كانت أطول بمتوسط نحو 500 كلمة وأن مجموعات الكلمات المستخدمة للفتيان والفتيات تشترك جزئياً فقط، خاصة في الفئات العمرية الأصغر والأكبر. تعكس هذه الاختلافات على الأرجح أماكن تقديم الرعاية (مثل عيادات الأعصاب أو الجهاز الهضمي للفتيان مقابل طب الأطفال العام أو النمائي للفتيات) وكيفية توثيق الأعراض في تلك البيئات، أكثر مما تعكس اختلافات بيولوجية حقيقية في القلق.
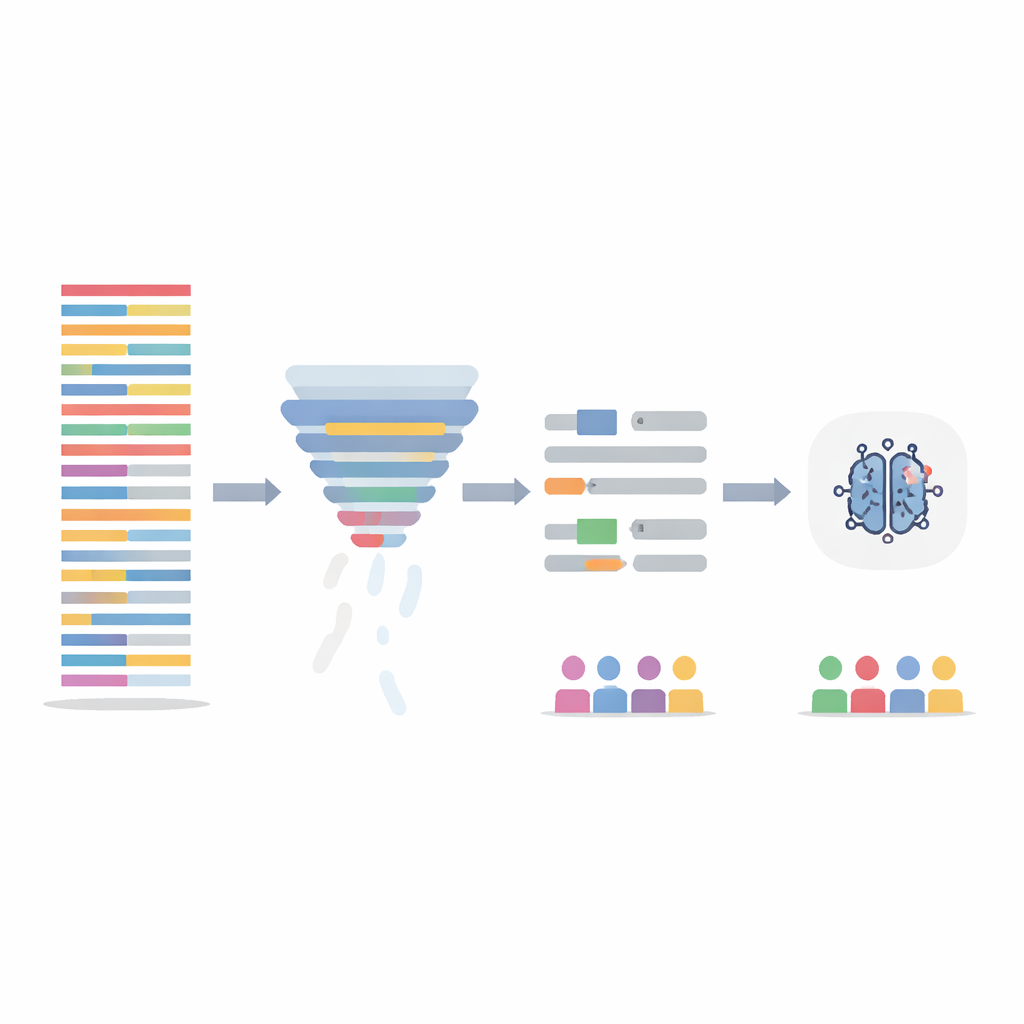
تنقية النص دون فقدان القصة
بدلاً من تعديل نموذج الذكاء الاصطناعي نفسه، ركز الفريق على تنظيف بيانات التدريب بطريقتين. أولاً، استخدموا خطوة ترشيح معلوماتية تقيم كل جملة حسب مقدار المعلومات التي تحملها عبر كامل مجموعة البيانات، ثم تزيل أقل 20 بالمئة من الجمل من حيث القيمة المعلوماتية. هذا يقصر الملاحظات الطويلة والمتكررة ويعادل كثافة المعلومات عبر المرضى. ثانياً، استهدفوا اللغة الواضح التمييز الجنسي—الأسماء والضمائر—مباشرةً واستبدلوها تلقائياً بعناصر نائب محايدة وضمائر محايدة جنسياً حتى لا يتمسّك النموذج بـ"هو" أو "هي" كدلائل. اختُبرت هاتان الخطوتان منفردتين ومعاً، وأُعيد تدريب النماذج على الملاحظات المعدلة بينما قُيّمت على ملاحظات الاختبار الأصلية غير المعدلة.
نتائج أكثر عدلاً دون التضحية بالفائدة
أدى تدريب النماذج على البيانات المنقّحة إلى أداء مماثل أو أفضل قليلاً من النموذج الأصلي في الدقة الإجمالية، لكنه أحرى معاملة المجموعات بمساواة أكبر. خفضت طريقة ترشيح الجمل، على وجه الخصوص، الفجوة في التشخيصات المفقودة للقلق بين الفتيان والفتيات بما يصل إلى نحو ثلث، وقلصت الشك الإضافي الملحوظ لدى الفتيات. عند الجمع بين الطريقتين، ساعدتا أيضاً في تقليل التفاوتات عبر المجموعات العرقية. أظهر فحص إضافي باستخدام أداة تفسير أن النموذج بعد إزالة التحيز اعتمد أقل على كلمات متعلقة بالجنس وأكثر على كلمات سياقية ذات معنى سريري مثل "يقدّم" أو "شكوى"، مما يشير إلى عملية قرار أكثر صحة.
ماذا يعني هذا لمستقبل الذكاء الاصطناعي في رعاية الأطفال
تخلص الدراسة إلى أن أدوات الذكاء الاصطناعي لصحة الأطفال النفسية عرضة لتحيزات متجذرة ليس في البيولوجيا، بل في كيفية ومكان توثيق الرعاية. من خلال ترشيح الجمل قليلة القيمة بشكل منهجي وتحييد اللغة الجنسانية، يبرهن الباحثون أنه من الممكن تقليل هذه الفجوات غير العادلة دون تدهور الأداء. وبينما يظل العمل إثبات مفهوم ويحتاج إلى اختبار مع نماذج ومستشفيات أخرى، فإنه يقدم وصفة عملية ومتمركزة حول البيانات لجعل الفحص المدعوم بالذكاء الاصطناعي أكثر عدلاً للفتيات والمجموعات الأخرى التي قد تُغفل خلاف ذلك.
الاستشهاد: Ive, J., Bondaronek, P., Yadav, V. et al. A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text. Commun Med 6, 221 (2026). https://doi.org/10.1038/s43856-026-01480-2
الكلمات المفتاحية: قلق الأطفال, انحياز نصوص السجل الطبي, العدالة في الذكاء الاصطناعي, السجلات الصحية الإلكترونية, فحص الصحة النفسية