Clear Sky Science · ja
小児精神衛生テキストにおける人口統計学的バイアスの検出と緩和へのデータ中心アプローチ
なぜこの研究が家族にとって重要なのか
より多くの医師が人工知能(AI)を使って早期の精神健康問題の兆候を検出しようとする中で、重要な疑問が生じます:こうしたツールはすべての子どもに対して同じ精度を持っているのか? 本研究は、医師の記録をAIがどのように読み取って子どもの不安を予測するかを詳細に検証し、特に思春期の女児が見逃されやすいことを明らかにします。研究者らは、そのうえで貴重な医療情報を捨てることなくシステムをより公平にする実用的な方法を提案します。
ストレスの多い世代で高まる不安
子どもや十代の不安や抑うつは近年急増しており、特にCOVID-19パンデミック中には臨床的に有意な不安症状の割合がほぼ倍増しました。医療体制には負担がかかっています:徹底的な評価は時間がかかり、保護者や教師、本人を巻き込み、専門的な訓練を受けた臨床家が必要です。AIは、臨床家が既に記録している自由記述のノートをスキャンして多数の患者を素早くスクリーニングするという一助になり得ます。しかし、もしノート自体に見えにくいバイアスが含まれ、それをAIが学習してしまえば、この技術は不平等を解消するどころか静かに悪化させる可能性があります。
実際の病院記録でチームがバイアスをどのように調べたか
研究者らは、2009年から2022年の間にシンシナティ小児病院で診療を受けた130万人以上の電子健康記録を活用しました。このプールから、最終的に不安の診断を受けた5〜15歳のおよそ7万3000人の若年患者に注目し、年齢・性別・臨床歴が類似する不安診断のない子どもをそれぞれマッチさせました。各子どもについて、初回の不安診断の少なくとも1か月前に書かれた直近の医師・看護師のノートを最大25件収集し、現代的な言語モデルであるClinical‑BigBirdを用いてテキストと後の不安を結びつけるパターンを学習させました。次に、そのモデルが男女別や人種別でどのように機能するかを、フェアネス研究で一般的に用いられる誤り率を使って評価しました。
女児および他のグループで何が問題だったか
年齢層を通じて、AIモデルの全体的な精度は控えめで約61パーセントでしたが、詳しく見ると一貫して憂慮すべきパターンが現れました。女児ではモデルの精度が約4ポイント低く、偽陰性(不安があるのに不安がないとラベル付けされる)が約9パーセント多く発生しており、不安のある女児がより頻繁に見逃されていました。また、女児に対するモデルの予測は「不確実」な中間領域に入りやすいという傾向もありました。元のテキストを調べると、男児についてのノートは平均でおよそ500語長く、男児と女児で使われる語の集合が部分的にしか重なっていないことが分かりました。これは年少および年長の年齢帯で特に顕著でした。こうした差は、おそらく子どもが受診する診療科(例えば、男児が神経科や消化器科で診られる一方、女児は一般小児科や発達小児科で診られるなど)や、そうした場で臨床家が症状を記録する方法を反映しており、不安の生物学的な差異を示すものではない可能性が高いです。
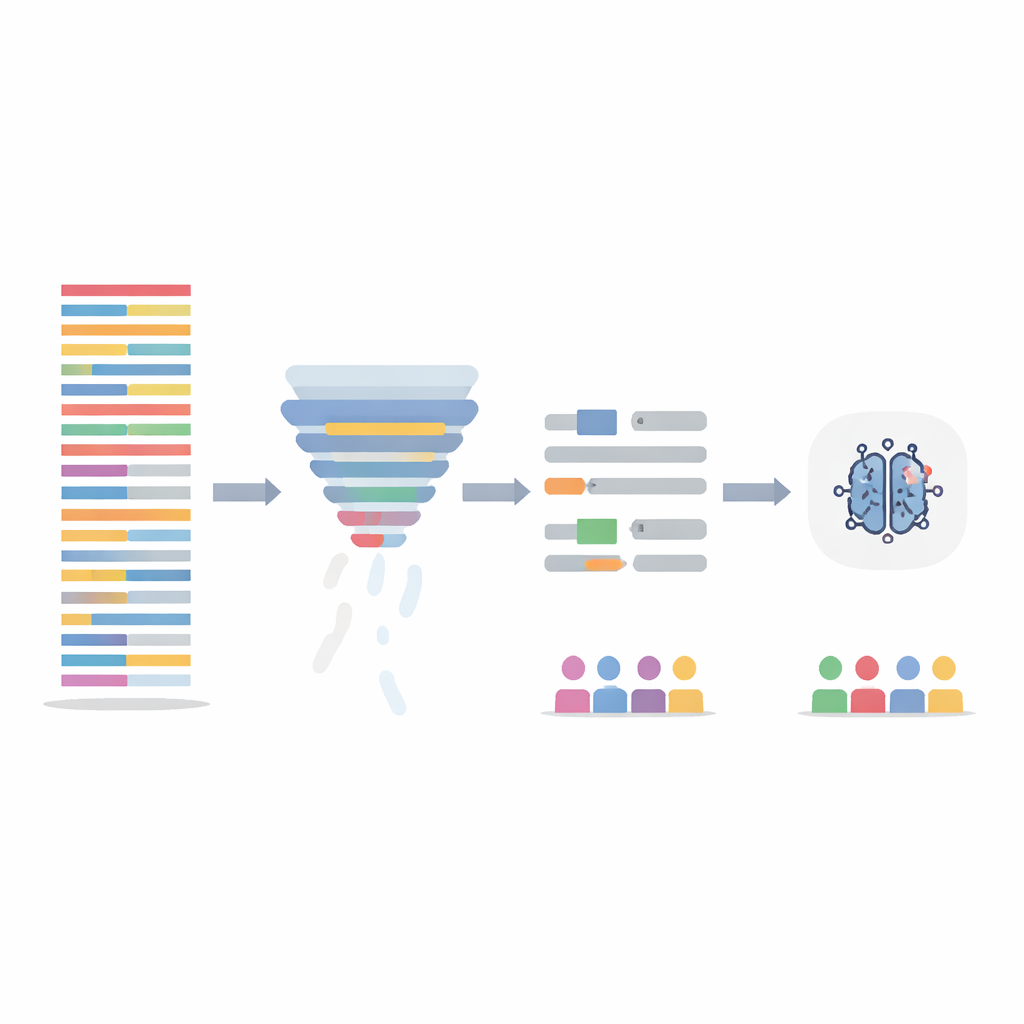
物語を失わずにテキストを整える
チームはAIモデル自体を変える代わりに、トレーニングデータの洗練に着目しました。まず、情報フィルタリングの工程を用い、データセット全体で各文の語がどれだけ情報を与えるかをスコア化し、情報量が最も低い20パーセントの文を削除しました。これにより長く冗長なノートが短くなり、患者間で情報密度の差が緩和されます。次に、明らかに性別に結びついた言語―名前や代名詞―を対象に、自動的に中立的なプレースホルダーや性別中立の代名詞に置き換え、モデルが「彼」や「彼女」を手がかりにしないようにしました。これら二つの手法は単独および組み合わせてテストされ、変更後のノートで再学習させつつ、評価は元の手つかずのテストノートで行われました。
有用性を損なわずにより公平な結果
データを洗練したモデルは、全体の精度では元のモデルと同等かやや良好でありながら、グループ間の扱いをより公平にする点で改善しました。特に文フィルタリング手法は、男児と女児の間の見逃しの差を最大で約3分の1まで縮め、女児に見られた余分な不確実性も減少させました。二つの手法を組み合わせると、人種グループ間の格差の緩和にも寄与しました。説明ツールによる追加の確認では、バイアス除去後のモデルは性別関連語に依存する度合いが低くなり、「呈する(presents)」や「訴え(complaint)」のような臨床的に意味のある文脈語により依存するようになっており、意思決定過程が健全になったことを示唆しています。
小児医療における将来のAIにとっての意義
研究は、小児の精神衛生向けAIツールは生物学ではなく記録のされ方や受診場所に根差したバイアスに脆弱であると結論づけます。低価値な文を体系的に除き、性別に結びついた言語を中立化することで、性能を損なうことなくこうした不公平な差を減らすことが可能であることを研究者らは示しています。本研究は概念実証の段階であり、他のモデルや病院での検証が必要ですが、女児やそれ以外の見落とされがちなグループに対するAI支援スクリーニングをより公平にするための具体的でデータ中心の手法を提示しています。
引用: Ive, J., Bondaronek, P., Yadav, V. et al. A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text. Commun Med 6, 221 (2026). https://doi.org/10.1038/s43856-026-01480-2
キーワード: 小児期不安, 臨床文書のバイアス, AIの公平性, 電子カルテ, メンタルヘルススクリーニング