Clear Sky Science · fr
Une approche centrée sur les données pour détecter et atténuer les biais démographiques dans les textes de santé mentale pédiatrique
Pourquoi cette recherche compte pour les familles
À mesure que davantage de médecins utilisent l’intelligence artificielle (IA) pour repérer les premiers signes de troubles mentaux, une question cruciale se pose : ces outils sont-ils également précis pour tous les enfants ? Cette étude examine de près la manière dont l’IA lit les notes des cliniciens pour prédire l’anxiété chez les enfants et les adolescents — et révèle que les filles, en particulier les adolescentes, sont plus souvent non repérées. Les chercheurs proposent ensuite une méthode pragmatique pour rendre ces systèmes plus équitables sans sacrifier d’informations médicales précieuses.
Une inquiétude croissante dans une génération stressée
L’anxiété et la dépression chez les enfants et les adolescents ont fortement augmenté ces dernières années, les symptômes d’anxiété d’importance clinique ayant presque doublé pendant la pandémie de COVID‑19. Les systèmes de santé sont sous pression : des évaluations complètes prennent du temps, impliquent parents, enseignants et jeunes eux‑mêmes, et nécessitent des cliniciens formés. L’IA offre une aide possible — dépister rapidement de nombreux patients en analysant les notes en texte libre que les cliniciens rédigent déjà. Mais si ces notes contiennent des biais cachés et que les modèles d’IA les apprennent tels quels, la technologie pourrait aggraver silencieusement les inégalités existantes au lieu de les atténuer.
Comment l’équipe a étudié le biais dans de vrais dossiers hospitaliers
Les chercheurs ont exploité les dossiers de santé électroniques de plus de 1,3 million de patients vus au Cincinnati Children’s Hospital entre 2009 et 2022. Parmi eux, ils se sont concentrés sur environ 73 000 jeunes patients âgés de 5 à 15 ans qui ont finalement reçu un diagnostic d’anxiété, et ont apparié chacun d’eux à un enfant similaire sans ce diagnostic (même âge, même sexe, antécédents cliniques proches). Pour chaque enfant, ils ont rassemblé jusqu’à 25 des notes de médecins et d’infirmières les plus récentes, rédigées au moins un mois avant le premier diagnostic d’anxiété, et ont utilisé un modèle de langage moderne, Clinical‑BigBird, pour apprendre les motifs reliant le texte à l’anxiété ultérieure. Ils ont ensuite évalué la performance du modèle séparément pour les garçons et les filles, ainsi que pour différents groupes raciaux, en utilisant des taux d’erreur standards dans la recherche sur l’équité.
Ce qui a mal fonctionné pour les filles et d’autres groupes
Sur l’ensemble des tranches d’âge, la précision globale du modèle d’IA était modeste — environ 61 % — mais un examen plus approfondi a révélé un schéma cohérent et préoccupant. Pour les filles, le modèle était environ 4 points de pourcentage moins précis et produisait environ 9 % de faux négatifs en plus, signifiant que les filles anxieuses étaient plus souvent classées comme ne présentant pas d’anxiété. Les prédictions pour les filles étaient aussi plus fréquemment « incertaines », situées dans une zone frontière. En examinant les textes sous‑jacents, l’équipe a constaté que les notes concernant les garçons faisaient en moyenne environ 500 mots de plus et que les jeux de mots utilisés pour les garçons et les filles se recoupaient seulement partiellement, en particulier dans les tranches d’âge les plus jeunes et les plus âgées. Ces différences reflètent probablement les lieux de prise en charge (par exemple neurologie ou gastro‑entérologie pour les garçons versus pédiatrie générale ou développementale pour les filles) et la façon dont les cliniciens dans ces services documentent les symptômes, plutôt que des différences biologiques réelles de l’anxiété.
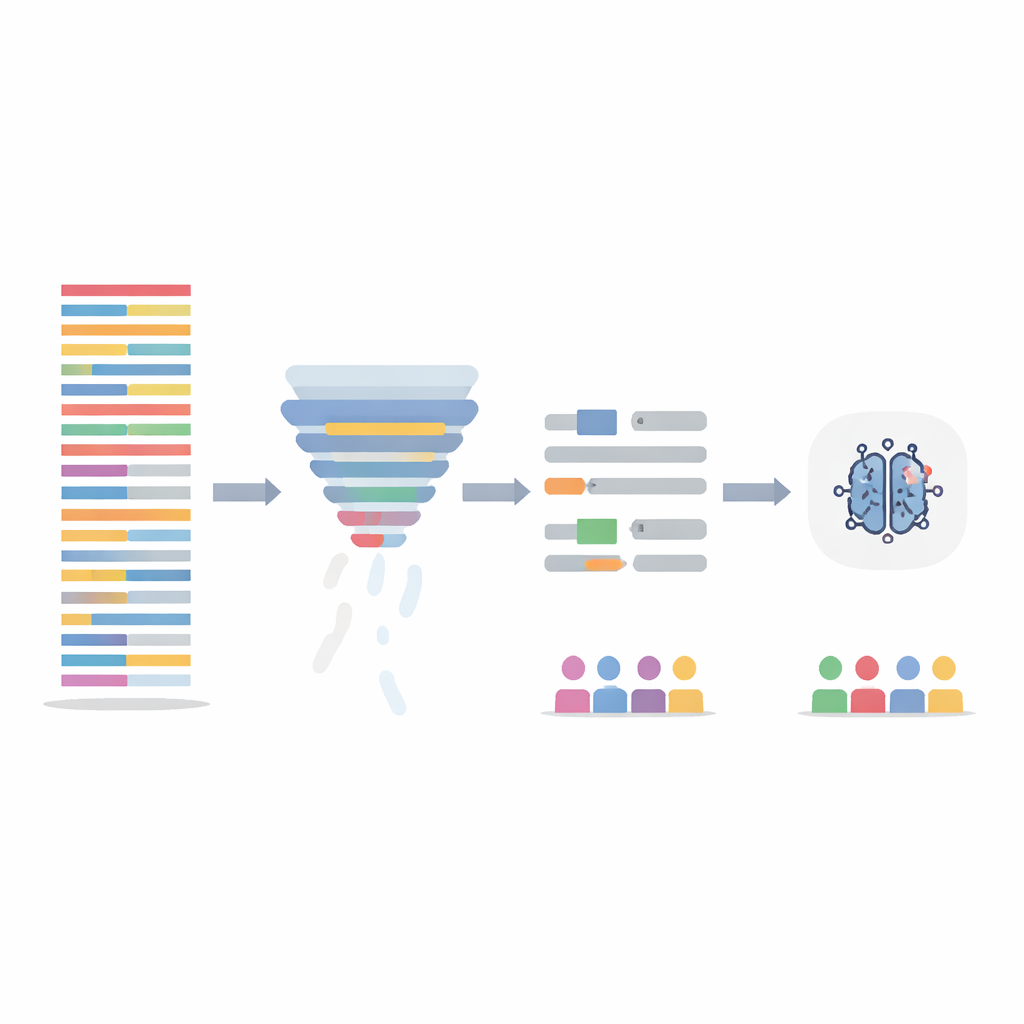
Épurer le texte sans perdre l’essentiel
Plutôt que de modifier le modèle d’IA lui‑même, l’équipe s’est concentrée sur l’assainissement des données d’entraînement de deux manières. D’abord, ils ont appliqué une étape de filtrage d’information qui évalue chaque phrase selon la valeur informative de ses mots sur l’ensemble du jeu de données, puis supprime les 20 % les moins informatifs. Cela raccourcit les notes longues et répétitives et homogénéise la densité d’information entre patients. Ensuite, ils ont ciblé le langage manifestement genré — noms et pronoms — en les remplaçant automatiquement par des marqueurs neutres et des pronoms non genrés afin que le modèle ne s’accroche pas à « il » ou « elle » comme indices. Ces deux étapes ont été testées séparément et combinées, et les modèles ont été réentraînés sur les notes modifiées tout en étant évalués sur des notes de test originales et intactes.
Des résultats plus équitables sans sacrifier l’utilité
Les modèles entraînés sur les données nettoyées ont eu des performances globales comparables, voire légèrement supérieures, au modèle initial, tout en traitant mieux les groupes de manière équitable. La méthode de filtrage des phrases, en particulier, a réduit l’écart des diagnostics d’anxiété manqués entre garçons et filles d’environ un tiers, et diminué l’incertitude supplémentaire observée pour les filles. Lorsqu’elles étaient combinées, les deux méthodes ont aussi contribué à atténuer les disparités entre groupes raciaux. Un contrôle additionnel avec un outil d’explicabilité a montré qu’après la dé‑biaisation, le modèle s’appuyait moins sur des mots liés au genre et davantage sur des mots de contexte cliniquement pertinents comme « présente » ou « plainte », suggérant un processus décisionnel plus sain.
Ce que cela signifie pour l’avenir de l’IA en pédiatrie
L’étude conclut que les outils d’IA pour la santé mentale pédiatrique sont vulnérables à des biais qui ne proviennent pas de la biologie, mais de la manière et du lieu où les soins sont documentés. En filtrant systématiquement les phrases à faible valeur et en neutralisant le langage genré, les chercheurs montrent qu’il est possible de réduire ces écarts injustes sans dégrader les performances. Bien que ce travail reste une preuve de concept et doive être testé avec d’autres modèles et dans d’autres hôpitaux, il offre une recette concrète, centrée sur les données, pour rendre le dépistage assisté par l’IA plus équitable pour les filles et d’autres groupes qui pourraient autrement être négligés.
Citation: Ive, J., Bondaronek, P., Yadav, V. et al. A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text. Commun Med 6, 221 (2026). https://doi.org/10.1038/s43856-026-01480-2
Mots-clés: anxiété pédiatrique, biais dans les textes cliniques, équité dans l'IA, dossiers de santé électroniques, dépistage en santé mentale