Clear Sky Science · nl
Een data‑gerichte benadering voor het detecteren en verminderen van demografische vooringenomenheid in pediatrische geestelijke gezondheidsteksten
Waarom dit onderzoek belangrijk is voor gezinnen
Nu steeds meer artsen kunstmatige intelligentie (AI) gebruiken om vroege signalen van psychische problemen te herkennen, rijst een cruciale vraag: zijn deze hulpmiddelen even nauwkeurig voor alle kinderen? Deze studie bekijkt nauwkeurig hoe AI doktersnotities leest om angst bij kinderen en tieners te voorspellen — en laat zien dat meisjes, vooral adolescenten, vaker gemist worden. De onderzoekers stellen vervolgens een praktische manier voor om deze systemen eerlijker te maken zonder waardevolle medische informatie weg te gooien.
Stijgende zorgen in een gestreste generatie
Angst en depressie bij kinderen en tieners zijn de afgelopen jaren sterk toegenomen, met aantallen klinisch relevante angstsymptomen die tijdens de COVID‑19‑pandemie bijna verdubbelden. Zorgsystemen staan onder druk: grondige beoordelingen kosten tijd, betrekken ouders, leraren en jongeren zelf, en vereisen clinici met gespecialiseerde training. AI biedt één mogelijke hulp — het snel screenen van grote aantallen patiënten door de vrije‑tekstnotities te scannen die clinici al schrijven. Maar als die notities verborgen vooroordelen bevatten en AI‑modellen er gewoon van leren, kan de technologie stilletjes bestaande ongelijkheden verergeren in plaats van verlichten.
Hoe het team vooringenomenheid bestudeerde in echte ziekenhuisdossiers
De onderzoekers maakten gebruik van elektronische patiëntendossiers van meer dan 1,3 miljoen patiënten die tussen 2009 en 2022 in Cincinnati Children’s Hospital zijn gezien. Uit deze groep richtten ze zich op ongeveer 73.000 jonge patiënten van 5 tot 15 jaar die uiteindelijk een angstdiagnose kregen, en paste elk van hen toe aan een vergelijkbaar kind zonder zo’n diagnose (zelfde leeftijd, zelfde geslacht, vergelijkbare klinische geschiedenis). Voor elk kind verzamelden ze tot 25 van de meest recente dokters‑ en verpleegkundigenotities die minstens een maand vóór de eerste angstdiagnose waren geschreven en gebruikten ze een modern taalmodel, Clinical‑BigBird, om patronen te leren die tekst koppelen aan latere angst. Daarna controleerden ze hoe goed het model afzonderlijk werkte voor jongens en meisjes, en voor verschillende raciale groepen, met foutmarges die standaard zijn in eerlijkheidsonderzoek.
Wat er mis ging voor meisjes en andere groepen
Over de leeftijdsgroepen heen was de algehele nauwkeurigheid van het AI‑model beperkt — rond de 61 procent — maar een diepere analyse toonde een consistent en verontrustend patroon. Voor meisjes was het model ongeveer 4 procentpunt minder nauwkeurig en leverde het ongeveer 9 procent meer vals‑negatieven op, wat betekent dat angstige meisjes vaker werden aangemerkt als niet angstig. De voorspellingen voor meisjes waren ook vaker “onzeker” en zweefden in een grijs gebied. Toen het team de onderliggende teksten onderzocht, vonden ze dat notities over jongens gemiddeld zo’n 500 woorden langer waren en dat de woordenset voor jongens en meisjes slechts gedeeltelijk overlapt, vooral in de jongste en oudste leeftijdscategorieën. Deze verschillen weerspiegelen waarschijnlijk waar kinderen worden gezien (bijvoorbeeld neurologie of gastro-enterologie voor jongens versus algemene of ontwikkelingspediatrie voor meisjes) en hoe clinici in die settings symptomen documenteren, in plaats van echte biologische verschillen in angst.
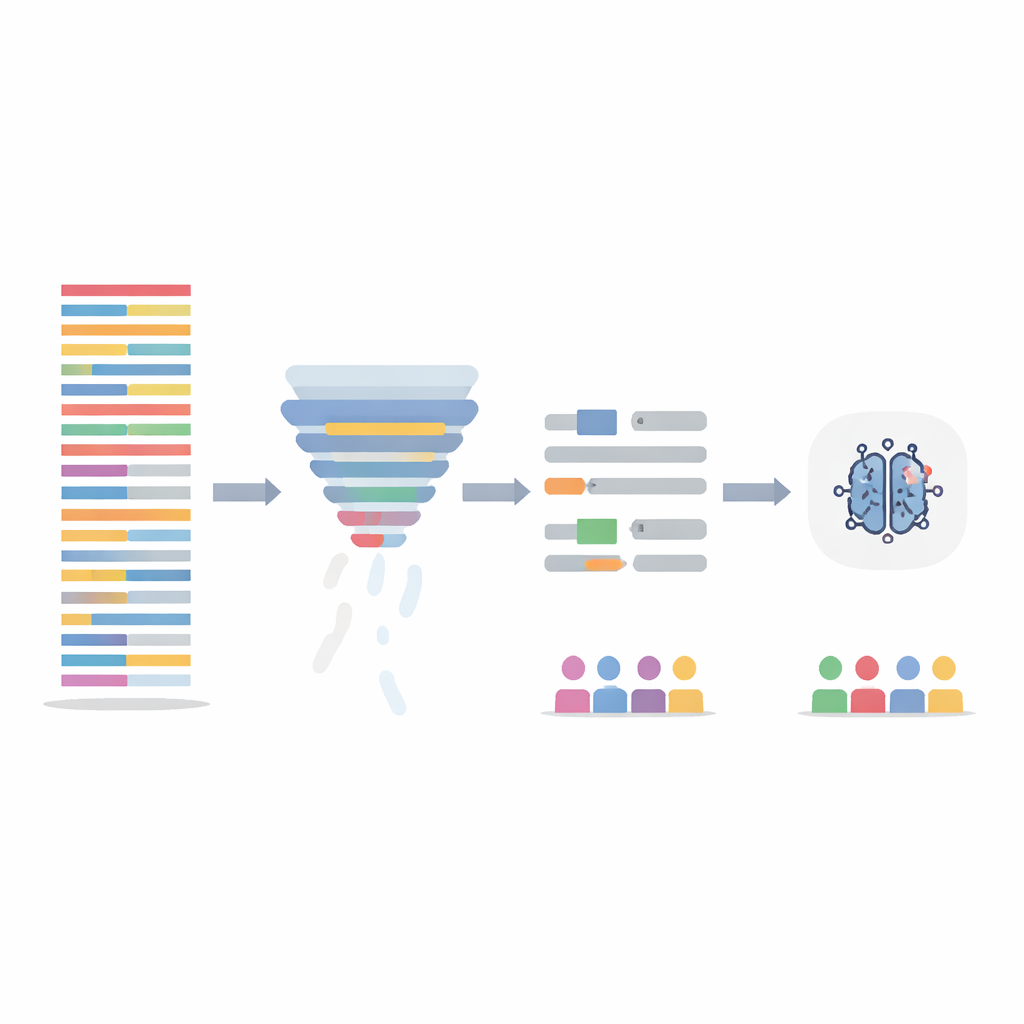
De tekst opschonen zonder het verhaal te verliezen
In plaats van het AI‑model zelf aan te passen, richtte het team zich op het opschonen van de trainingsdata op twee manieren. Ten eerste gebruikten ze een informatie‑filterstap die elke zin een score geeft op basis van hoe informatief de woorden zijn over de hele dataset, en vervolgens de minst informatieve 20 procent verwijdert. Dit verkort lange, repetitieve notities en egaliseert hoe dicht de informatie verdeeld is over patiënten. Ten tweede richtten ze zich op duidelijk gendergebonden taal — namen en voornaamwoorden — en vervingen deze automatisch door neutrale plaatsaanduidingen en genderneutrale voornaamwoorden zodat het model niet op “hij” of “zij” zou gaan leunen als aanwijzing. Deze twee stappen werden afzonderlijk en in combinatie getest, en de modellen werden opnieuw getraind op de aangepaste notities terwijl ze werden geëvalueerd op de originele, onaangetaste testnotities.
Eerlijkere uitkomsten zonder verlies van bruikbaarheid
De modellen met opgeschoonde data presteerden ongeveer even goed als, of iets beter dan, het oorspronkelijke model qua algemene nauwkeurigheid, maar deden het beter in het eerlijk behandelen van groepen. De zin‑filtermethode verkleinde met name de kloof in gemiste angstdiagnoses tussen jongens en meisjes met tot ongeveer een derde, en verminderde de extra onzekerheid die bij meisjes werd waargenomen. Wanneer de twee methoden werden gecombineerd, hielpen ze ook ongelijkheden tussen raciale groepen verminderen. Een aanvullende controle met een verklaringsinstrument toonde aan dat het model na het verwijderen van vooringenomenheid minder op gendergerelateerde woorden leunde en meer op klinisch zinvolle contextwoorden zoals "presenteert" of "klacht", wat wijst op een gezondere besluitvorming.
Wat dit betekent voor toekomstige AI in kindzorg
De studie concludeert dat AI‑hulpmiddelen voor pediatrische geestelijke gezondheid kwetsbaar zijn voor vooroordelen die niet in de biologie geworteld zijn, maar in hoe en waar zorg wordt gedocumenteerd. Door systematisch laagwaardige zinnen te filteren en gendergebonden taal te neutraliseren, tonen de onderzoekers aan dat het mogelijk is deze oneerlijke verschillen te verminderen zonder prestaties te verslechteren. Hoewel het werk nog een proof of concept is en getest moet worden met andere modellen en ziekenhuizen, biedt het een concreet, data‑gericht recept om AI‑ondersteunde screening eerlijker te maken voor meisjes en andere groepen die anders over het hoofd gezien kunnen worden.
Bronvermelding: Ive, J., Bondaronek, P., Yadav, V. et al. A data-centric approach to detecting and mitigating demographic bias in pediatric mental health text. Commun Med 6, 221 (2026). https://doi.org/10.1038/s43856-026-01480-2
Trefwoorden: pediatrische angst, vooringenomenheid in klinische teksten, eerlijkheid in AI, elektronische patiëntendossiers, screening geestelijke gezondheid