Clear Sky Science · zh
在视频类型识别中探索视觉变换器用于深度特征提取与分类
更智能的电视分类为何重要
流媒体服务和电视台如今要处理海量节目、电影与短片,风格涵盖从快节奏动作到低调浪漫的所有类型。在幕后,必须有人或某个系统判断每段内容的类别,以便检索、推荐与排期。本文探讨了可自动识别电视与视频内容类型的新型人工智能工具,这些工具同时分析屏幕上看到的画面和声音轨道,承诺以更快、更准确的方式整理现代媒体世界。 
从简单的图像线索到丰富的视频理解
早期自动类型识别依赖比较粗糙的视觉线索:整体色彩、基本纹理或简单的运动估计。这些方法在当今复杂的电视内容面前常常捉襟见肘,因为光线、节奏和情绪会随时刻变换。作者首先使用一种更新的图像模型——金字塔视觉变换器(Pyramid Vision Transformer,PvT)来应对这一挑战。该方法不是只扫描图像的小补丁,而是构建分层视图,既捕捉细节也体现场景的整体布局。应用于近4500张覆盖四种类型(动作、动画、爱情与恐怖)的电视制作图像数据集后,PvT学会了哪些光线、构图与取景组合通常预示着某一类别。
教会机器既听又看
电视类型不仅由视觉定义,声音同样重要:动作预告片中的强烈配乐、惊悚片里的紧张嗡鸣、爱情片中的温柔旋律。为此,作者提出了一种名为MAiVAR-T的多模态模型,它同时处理视频帧与音频。对于每个预告片,他们选取代表关键视觉时刻的帧,并将其与声音轨道的多种视图配对:原始波形、随时间变化的节奏与响度、以及音高与和声的紧凑摘要。MAiVAR-T沿两条并行路径运行——一条处理图像,一条处理音频——然后将二者融合。专门的融合阶段学习将屏幕上发生的事件与扬声器里发生的声音对齐,例如:与突发尖锐声音配合的昏暗走廊,会与伴随轻柔音乐的类似画面被区别对待。 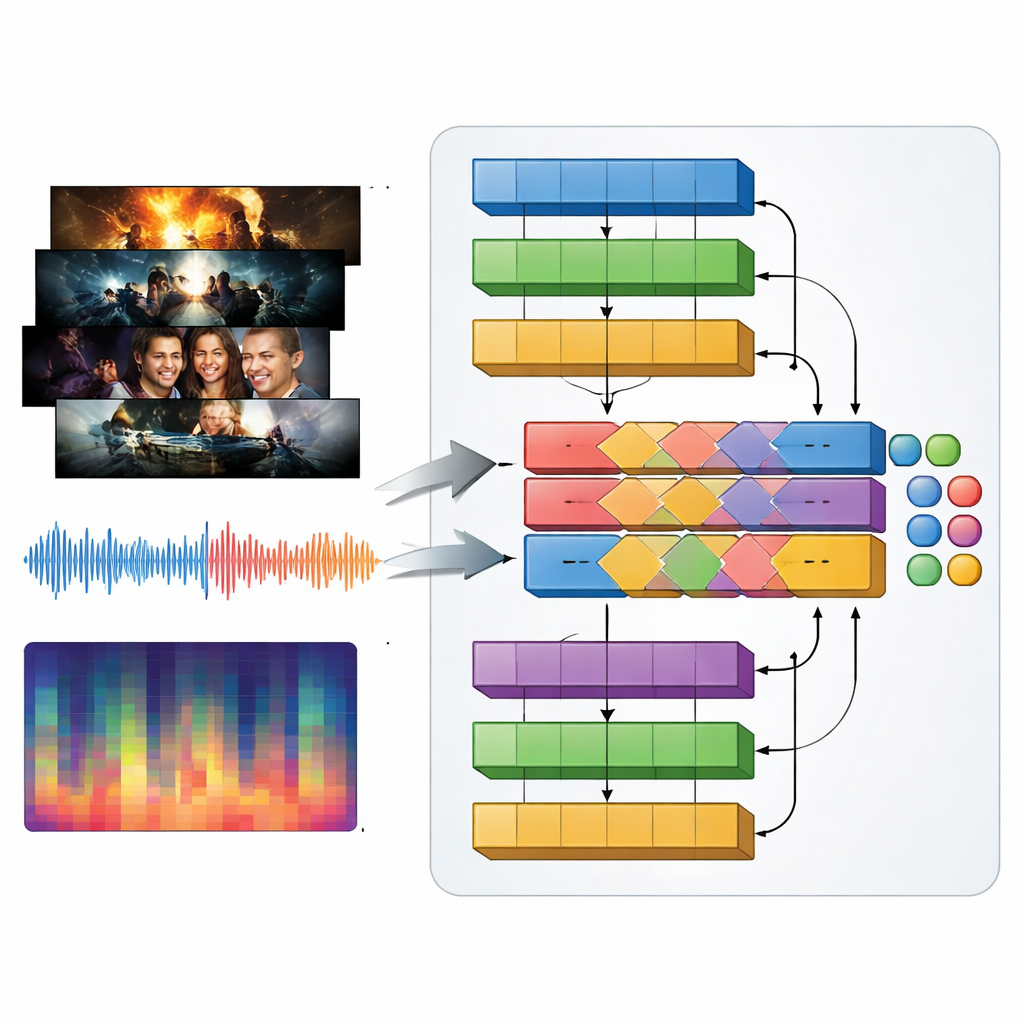
新方法的表现如何
研究者对其模型进行了严格测试,并与多种既有系统比较,包括经典卷积神经网络和更新的基于变换器的设计。在仅图像的数据集上,PvT达到了约95%的总体准确率,超过了NASNet等流行替代方案以及其他视觉变换器。在一个更大且类型更多样、涵盖11种类型的电影与电视预告片集合上,MAiVAR-T取得了约98%的准确率。这一表现优于以更松散方式结合声音与图像的旧多模态设计,也超过了仅看帧或仅看音频的强力单模态模型。细致的统计检验表明这些提升并非偶然,解释性工具如Grad-CAM和LIME也证实模型关注的是合理的线索,如角色运动、光线与音乐强度的变化。
这对观众与创作者意味着什么
高准确率的类型识别看似技术性细节,却支撑着许多日常体验,从流媒体首页的推荐排列到广播公司检索档案片段与精彩片段的方式。通过可靠地将丰富的视听模式与人类对类型的认知联系起来,像PvT和MAiVAR-T这样的系统可以帮助制片方管理庞大的内容库、支持更智能的推荐引擎,甚至为剪辑与预告片设计提供指导。作者指出,更具多样性的数据与更好地处理混合多类型节目将是重要的后续工作,此外还需关注伦理使用问题。尽管如此,他们的结果表明同时“看见”和“听见”的变换器有望成为组织与理解日益增长的数字媒体世界的强大助手。
引用: Alarfaj, F.K., Naz, A. Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media. Sci Rep 16, 14543 (2026). https://doi.org/10.1038/s41598-026-45087-y
关键词: 视频类型识别, 视觉变换器, 多模态人工智能, 电视分析, 视听分析