Clear Sky Science · tr
Dijital medyada video türü tanıma için derin özellik çıkarımı ve sınıflandırmada görsel transformerları keşfetmek
Daha akıllı TV sınıflandırmasının önemi
Akış hizmetleri ve televizyon kanalları artık hızlı tempolu aksiyondan sakin romantizme kadar her türde diziler, filmler ve kliplerle dolu bir okyanusu yönetiyor. Perde arkasında, her içerik parçasının ne olduğunu belirleyip bulunmasını, önerilmesini ve programlanmasını sağlayacak birinin—veya bir şeyin—olması gerekiyor. Bu makale, hem ekranda gördüklerinize hem de ses bantlarında duyduklarınıza bakarak TV ve video içeriklerinin türünü otomatik olarak tanıyabilen yeni yapay zeka araçlarını inceliyor; modern medya dünyasını daha hızlı ve daha doğru şekilde düzenlemek için umut vaat ediyor. 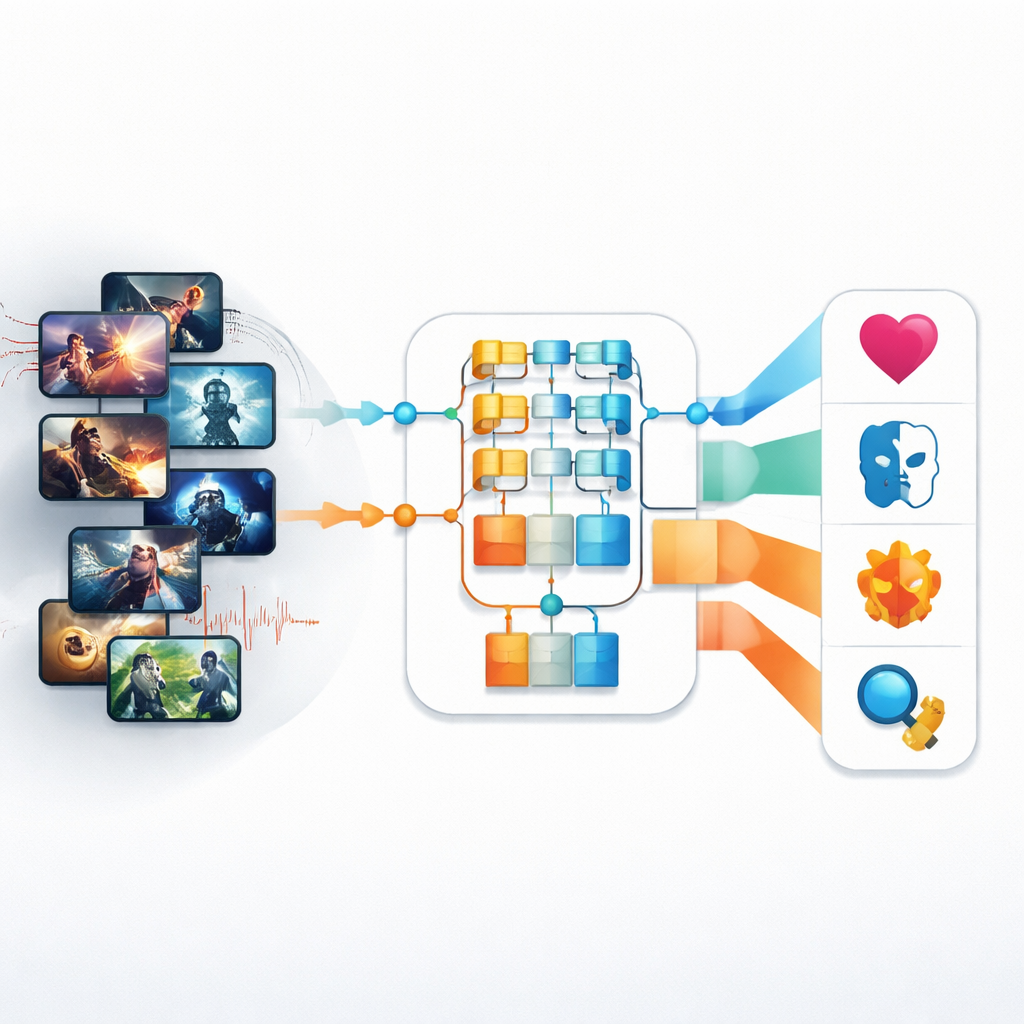
Basit görsel ipuçlarından zengin video anlayışına
Otomatik tür tanımındaki erken denemeler büyük ölçüde kaba görsel ipuçlarına dayanıyordu: genel renk, temel dokular veya basit hareket tahminleri gibi. Bu yöntemler, aydınlatma, tempo ve duygunun anandan ana değiştiği günümüzün karmaşık televizyon içeriğiyle baş etmekte zorlandı. Yazarlar bu zorluğa önce Piramit Görsel Transformer (PvT) adı verilen daha yeni bir görüntü modeli kullanarak yaklaşıyor. Bu yaklaşım sadece küçük görüntü yamalarını taramak yerine bir sahnenin hem ince ayrıntılarını hem de daha geniş düzenini yakalayan katmanlı bir görünüm inşa ediyor. Aksiyon, Animasyon, Romantizm ve Korku olmak üzere dört türü kapsayan yaklaşık 4.500 TV prodüksiyon görüntüsünden oluşan bir veri kümesine uygulandığında PvT, hangi aydınlatma, çerçeveleme ve kompozisyon kombinasyonlarının her kategoriyle ilişkilendiğini öğreniyor.
Makinelere bakmanın yanı sıra dinlemeyi öğretmek
Televizyon türleri görseller kadar sesle de tanımlanır: bir aksiyon fragmanındaki vurucu müzik, bir gerilimdeki gergin drone’lar, bir romantikteki naif melodiler. Bunu yakalamak için yazarlar, video karelerini ve sesi birlikte işleyen MAiVAR-T adını verdikleri çokmodlu bir model tanıtıyor. Her fragman için önemli görsel anları temsil eden anahtar kareler seçiliyor ve bunlar ses parçasının çeşitli görünümleriyle eşleştiriliyor: ham dalga formları, zaman içindeki ritim ve ses yüksekliği ile perde ve armoninin kompakt özetleri. MAiVAR-T, bir görüntü yolu ve bir ses yolu olmak üzere iki paralel yol izliyor ve ardından bunları birleştiriyor. Özel bir füzyon aşaması, ekrandaki olayları hoparlörlerden gelen sesle hizalamayı öğreniyor; böylece örneğin ani keskin seslerle eşlenen karanlık bir koridor, benzer bir görüntünün hafif bir müzikle desteklendiği durumdan farklı muamele görüyor. 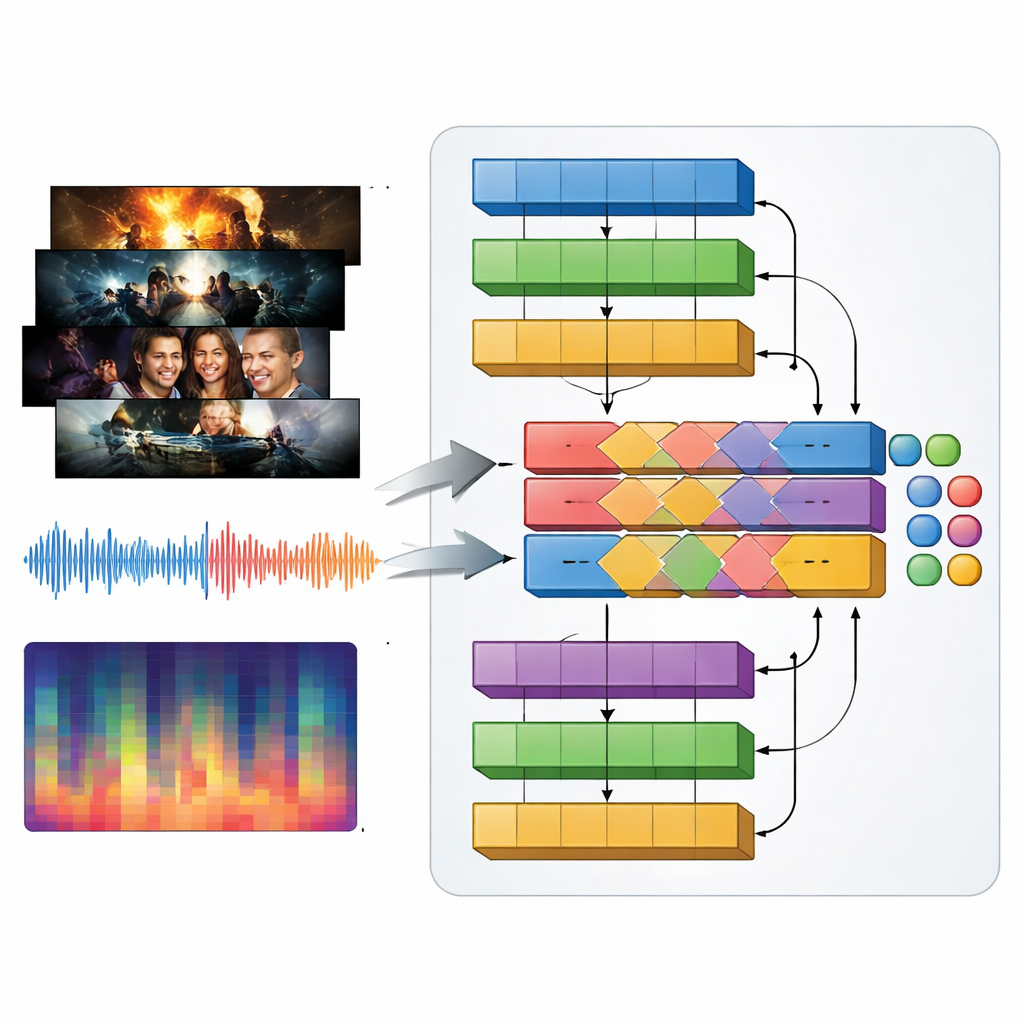
Yeni yaklaşımın performansı nasıl
Araştırmacılar modellerini klasik konvolüsyonel sinir ağları ve daha yeni transformer tabanlı tasarımlar dahil olmak üzere geniş bir yelpazede yerleşik sistemlere karşı titiz testlerden geçirdi. Yalnızca görüntü içeren veri kümesinde PvT yaklaşık %95 genel doğruluğa ulaşarak NASNet ve diğer görsel transformerlar gibi popüler alternatifleri geride bıraktı. On bir türü kapsayan çok daha büyük ve çeşitli bir film ve TV fragmanı koleksiyonunda MAiVAR-T yaklaşık %98 doğruluk elde etti. Bu performans, ses ve görüntüyü daha gevşek bir şekilde birleştiren eski çokmodlu tasarımları ve yalnızca karelere veya yalnızca sese bakan güçlü tek modlu modelleri aştı. Dikkatli istatistiksel kontroller bu kazanımların şansa bağlı olmadığını gösterdi ve Grad-CAM ile LIME gibi yorumlanabilirlik araçları, modellerin karakter hareketi, aydınlatma ve müzikal yoğunluktaki değişimler gibi mantıklı ipuçlarına odaklandığını doğruladı.
Bu izleyiciler ve içerik üreticiler için ne anlama gelebilir
Yüksek doğruluklu tür tanıma teknik bir ayrıntı gibi görünse de akış ana ekranınızdaki öneri satırlarından yayıncıların arşivlerinde klip ve önemli anları arama biçimine kadar günlük deneyimlerin çoğunu ayakta tutar. Görüntü ve sesin zengin desenlerini insan algısındaki tür kavramlarıyla güvenilir şekilde ilişkilendirerek PvT ve MAiVAR-T gibi sistemler, yapımcıların geniş içerik kütüphanelerini yönetmesine, daha akıllı öneri motorlarını desteklemesine ve hatta kurgulama ile fragman tasarımına rehberlik etmesine yardımcı olabilir. Yazarlar, daha çeşitli veriler ve birden çok türü harmanlayan gösterilerin daha iyi ele alınmasının önemli bir sonraki adım olacağını ve etik kullanıma dikkat etmenin de gerekli olduğunu belirtiyor. Yine de sonuçları, hem görüp hem duyan transformerların dijital medyanın giderek büyüyen evrenini düzenlemede ve anlamada güçlü yardımcılar olmaya aday olduğunu gösteriyor.
Atıf: Alarfaj, F.K., Naz, A. Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media. Sci Rep 16, 14543 (2026). https://doi.org/10.1038/s41598-026-45087-y
Anahtar kelimeler: video türü tanıma, görsel transformerlar, çokmodlu yapay zeka, televizyon analitiği, görüntü ve ses analizi