Clear Sky Science · ar
استكشاف محولات الرؤية لاستخراج الميزات العميقة والتصنيف في التعرف على نوع الفيديو للوسائط الرقمية
لماذا يهم فرز التلفزيون بشكل أذكى
تتعامل خدمات البث والقنوات التلفزيونية اليوم مع بحر من العروض والأفلام والمقاطع بمختلف الأساليب، من الحركة السريعة إلى الرومانسية الهادئة. خلف الكواليس، يجب على شخص أو نظام أن يقرر نوع كل قطعة محتوى ليُتاح العثور عليها والتوصية بها وجدولتها. يستكشف هذا البحث أدوات ذكاء اصطناعي جديدة يمكنها التعرف تلقائياً على نوع محتوى التلفزيون والفيديو من خلال النظر إلى ما يظهر على الشاشة وما يُسمع في المسار الصوتي، واعدة بطرق أسرع وأكثر دقة لتنظيم عالم الوسائط الحديث. 
من دلائل الصورة البسيطة إلى فهم الفيديو الغني
اعتمدت المحاولات الأولى للتعرف التلقائي على النوع على دلائل بصرية بسيطة إلى حد ما: اللون العام، القوام الأساسية، أو تقديرات حركة بسيطة. واجهت تلك الطرق صعوبات مع التلفزيون المعقد اليوم، حيث يتغير الإضاءة والإيقاع والعاطفة من لحظة لأخرى. يتعامل المؤلفون أولاً مع هذا التحدي باستخدام نوع أحدث من نماذج الصور يُسمى محول الرؤية الهرمي (Pyramid Vision Transformer - PvT). بدلاً من مسح رقع صغيرة فقط من الصورة، يبني هذا النهج عرضاً متعدد الطبقات يلتقط التفاصيل الدقيقة والتكوين العام للمشهد. عند تطبيقه على مجموعة بيانات تضم ما يقرب من 4500 صورة إنتاج تلفزيوني تغطي أربعة أنواع—حركة، رسوم متحركة، رومانسية، ورعب—يتعلم PvT أي تراكيب من الإضاءة والتأطير والتكوين تشير عادة إلى كل فئة.
تعليم الآلات الاستماع بقدر ما تنظر
تُعرّف أنواع التلفزيون بقدر ما تُعرّف بالصوت كما بالصور: موسيقى مدوية في إعلان لفيلم حركة، أصوات مشحونة بالتوتر في إثارة، وألحان ناعمة في الرومانسية. لالتقاط هذا، يقدم المؤلفون نموذجاً متعدد الوسائط يسمونه MAiVAR-T، يعالج إطارات الفيديو والصوت معًا. لكل إعلان، يختارون إطارات مفتاحية تمثل لحظات بصرية مهمة، ثم يقرنونها بعدة تمثيلات للمسار الصوتي: الموجات الخام، والإيقاع والحدة عبر الزمن، وملخصات مضغوطة للنغمة والتناغم. يتبع MAiVAR-T مسارين متوازيين—أحدهما للصور والآخر للصوت—قبل دمجهما. يتعلم مرحلة اندماج متخصصة مطابقة ما يحدث على الشاشة مع ما يحدث في الصوت، بحيث يُعامل، على سبيل المثال، ممر مظلم مصحوب بأصوات حادة مفاجئة بشكل مختلف عن صورة مماثلة مدعومة بموسيقى رقيقة. 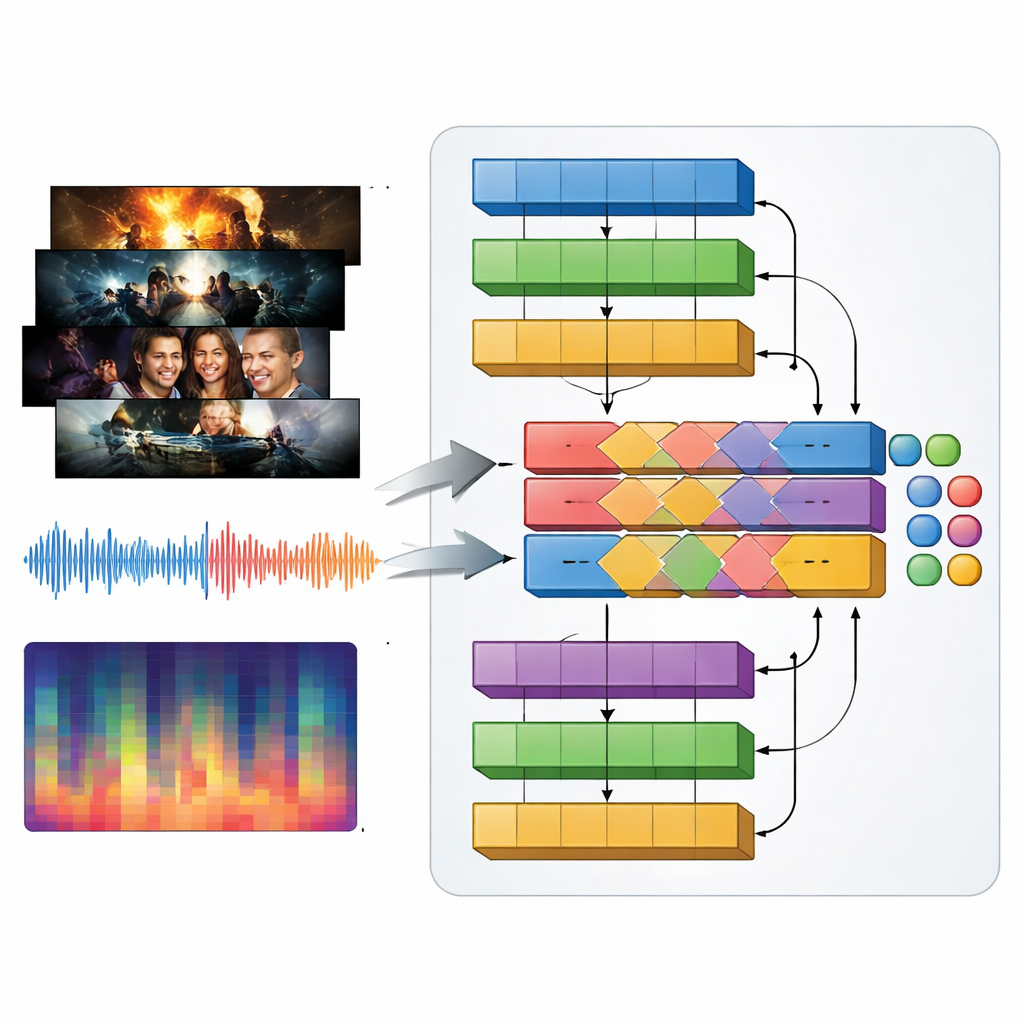
مدى أداء النهج الجديد
اختبر الباحثون نماذجهم بشدة مقابل مجموعة واسعة من الأنظمة المعروفة، بما في ذلك الشبكات العصبية الالتفافية الكلاسيكية وتصميمات المحولات الأحدث. على مجموعة البيانات المعتمدة على الصور فقط، بلغ دقة PvT نحو 95% إجمالاً، متجاوزاً بدائل شائعة مثل NASNet ومحولات رؤية أخرى. على مجموعة أكبر وأكثر تنوعاً من مقاطع أفلام وإعلانات تلفزيونية تغطي أحد عشر نوعًا، حقق MAiVAR-T حوالي 98% دقة. تفوّق هذا الأداء على تصاميم متعددة الوسائط الأقدم التي جمعت الصوت والصورة بشكل أكثر تساهلاً، وكذلك على نماذج أحادية الوضع القوية التي نظرت فقط إلى الإطارات أو فقط إلى الصوت. أظهرت الاختبارات الإحصائية الدقيقة أن هذه المكاسب لم تكن نتيجة صدفة، وأكدت أدوات قابلية التفسير مثل Grad-CAM وLIME أن النماذج تركز على دلائل منطقية مثل حركة الشخصيات والإضاءة وتغيرات شدة الموسيقى.
ما الذي قد يعنيه هذا للمشاهدين والمبدعين
قد تبدو دقة التعرف على النوع العالية تفصيلاً تقنياً، لكنها تدعم تجارب يومية كثيرة، من صفوف التوصيات على شاشة البث المنزلية إلى طريقة بحث المحطات في أرشيفاتها عن لقطات وملخصات. من خلال ربط أنماط غنية من الرؤية والصوت بمفاهيم بشرية للنوع بشكل موثوق، يمكن لأنظمة مثل PvT وMAiVAR-T مساعدة المنتجين على إدارة مكتبات ضخمة من المحتوى، ودعم محركات توصية أذكى، وحتى توجيه عمليات التحرير وتصميم الإعلانات. يشير المؤلفون إلى أن بيانات أكثر تنوعاً ومعالجة أفضل للعروض التي تمزج عدة أنواع ستكون خطوات مهمة تالية، وكذلك الانتباه إلى الاستخدام الأخلاقي. مع ذلك، تُظهر نتائجهم أن المحولات التي ترى وتسمع على حد سواء مرشحة لتصبح مساعدين أقوياء في تنظيم وفهم الكون المتنامي من الوسائط الرقمية.
الاستشهاد: Alarfaj, F.K., Naz, A. Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media. Sci Rep 16, 14543 (2026). https://doi.org/10.1038/s41598-026-45087-y
الكلمات المفتاحية: التعرف على نوع الفيديو, محولات الرؤية, الذكاء الاصطناعي متعدد الوسائط, تحليلات التلفزيون, التحليل السمعي البصري