Clear Sky Science · pt
Explorando transformers de visão para extração profunda de características e classificação na identificação de gênero em vídeo para mídia digital
Por que uma classificação de TV mais inteligente importa
Serviços de streaming e canais de TV lidam hoje com um oceano de séries, filmes e clipes em estilos que vão da ação acelerada ao romance contido. Nos bastidores, alguém — ou algo — precisa decidir o que cada conteúdo é para que ele possa ser encontrado, recomendado e programado. Este artigo explora novas ferramentas de inteligência artificial que podem reconhecer automaticamente o gênero de conteúdos televisivos e de vídeo ao analisar tanto o que aparece na tela quanto o que se ouve na trilha sonora, prometendo formas mais rápidas e precisas de organizar o mundo moderno da mídia. 
De pistas visuais simples a um entendimento rico do vídeo
As primeiras tentativas de reconhecimento automático de gênero apoiavam-se em pistas visuais relativamente cruas: cor geral, texturas básicas ou estimativas simples de movimento. Esses métodos tinham dificuldade com a televisão complexa de hoje, em que iluminação, ritmo e emoção mudam de instante a instante. Os autores enfrentam esse desafio usando um tipo mais novo de modelo de imagem chamado Pyramid Vision Transformer (PvT). Em vez de examinar apenas pequenos blocos da imagem, essa abordagem constrói uma visão em camadas que captura tanto detalhes finos quanto a disposição mais ampla da cena. Aplicado a um conjunto de dados com quase 4.500 imagens de produções televisivas abrangendo quatro gêneros — Ação, Animação, Romance e Terror — o PvT aprende quais combinações de iluminação, enquadramento e composição tendem a sinalizar cada categoria.
Ensinar máquinas a ouvir tão bem quanto ver
Os gêneros televisivos são definidos tanto pelo som quanto pelo visual: música pulsante em um trailer de ação, drones tensos em um thriller, melodias suaves em um romance. Para capturar isso, os autores apresentam um modelo multimodal que chamam de MAiVAR-T, que processa quadros de vídeo e áudio em conjunto. Para cada trailer, eles selecionam quadros-chave que representam momentos visuais importantes e os emparelham com múltiplas visões da trilha sonora: formas de onda brutas, ritmo e intensidade ao longo do tempo e resumos compactos de altura e harmonia. O MAiVAR-T segue duas vias paralelas — uma para imagens, outra para áudio — antes de fundi-las. Uma etapa especializada de fusão aprende a alinhar o que acontece na tela com o que acontece nas caixas de som, de modo que, por exemplo, um corredor escuro combinado com sons agudos súbitos seja tratado de forma diferente de uma imagem similar acompanhada por música suave. 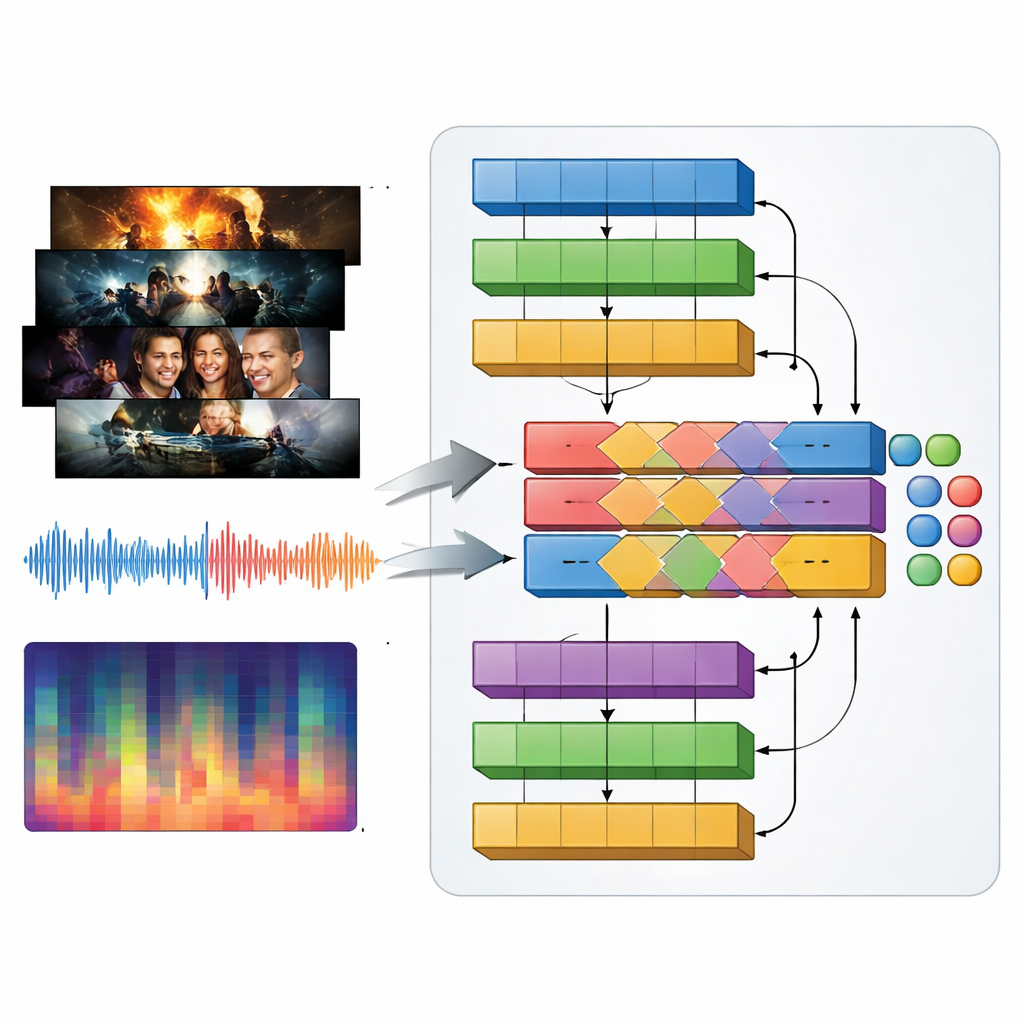
Quão bem a nova abordagem se sai
Os pesquisadores submeteram seus modelos a testes rigorosos contra uma ampla gama de sistemas estabelecidos, incluindo redes neurais convolucionais clássicas e desenhos mais recentes baseados em transformers. No conjunto de dados somente com imagens, o PvT atingiu cerca de 95% de acurácia geral, superando alternativas populares como NASNet e outros transformers de visão. Em uma coleção muito maior e mais variada de trailers de filmes e TV cobrindo onze gêneros, o MAiVAR-T alcançou aproximadamente 98% de acurácia. Esse desempenho superou designs multimodais anteriores que combinavam som e imagem de forma mais frouxa, assim como fortes modelos de modalidade única que consideravam apenas quadros ou apenas áudio. Verificações estatísticas cuidadosas mostraram que esses ganhos não se deviam ao acaso, e ferramentas de interpretabilidade como Grad-CAM e LIME confirmaram que os modelos se concentram em pistas sensatas, como movimento de personagens, iluminação e mudanças na intensidade musical.
O que isso pode significar para espectadores e criadores
Reconhecimento de gênero de alta precisão pode parecer um detalhe técnico, mas sustenta muitas experiências do dia a dia, desde as fileiras de recomendações na tela inicial do seu serviço de streaming até a forma como emissoras procuram em seus arquivos por clipes e destaques. Ao conectar de forma confiável padrões ricos de imagem e som às noções humanas de gênero, sistemas como PvT e MAiVAR-T podem ajudar produtores a gerenciar vastas bibliotecas de conteúdo, apoiar mecanismos de recomendação mais inteligentes e até orientar edição e design de trailers. Os autores observam que dados mais diversos e um melhor tratamento de programas que mesclam vários gêneros serão passos importantes a seguir, assim como manter a atenção sobre o uso ético. Ainda assim, seus resultados mostram que transformers que tanto veem quanto ouvem estão prontos para se tornar assistentes poderosos na organização e compreensão do universo cada vez maior da mídia digital.
Citação: Alarfaj, F.K., Naz, A. Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media. Sci Rep 16, 14543 (2026). https://doi.org/10.1038/s41598-026-45087-y
Palavras-chave: reconhecimento de gênero de vídeo, transformers de visão, IA multimodal, análise televisiva, análise áudio-visual