Clear Sky Science · nl
Het verkennen van vision transformers voor diepe feature-extractie en classificatie bij videogenreherkenning voor digitale media
Waarom slimmer TV-sorteren ertoe doet
Streamingdiensten en tv-zenders verwerken tegenwoordig een oceaan aan series, films en clips in alle stijlen, van razendsnelle actie tot stille romantiek. Achter de schermen moet iemand — of iets — bepalen wat elk stukje inhoud is zodat het gevonden, aanbevolen en ingepland kan worden. Dit artikel verkent nieuwe middelen uit de kunstmatige intelligentie die automatisch het genre van tv- en videocontent kunnen herkennen door te kijken naar zowel wat er op het scherm te zien is als wat er in de soundtrack te horen is, en belooft snellere, nauwkeurigere manieren om de moderne mediewereld te organiseren. 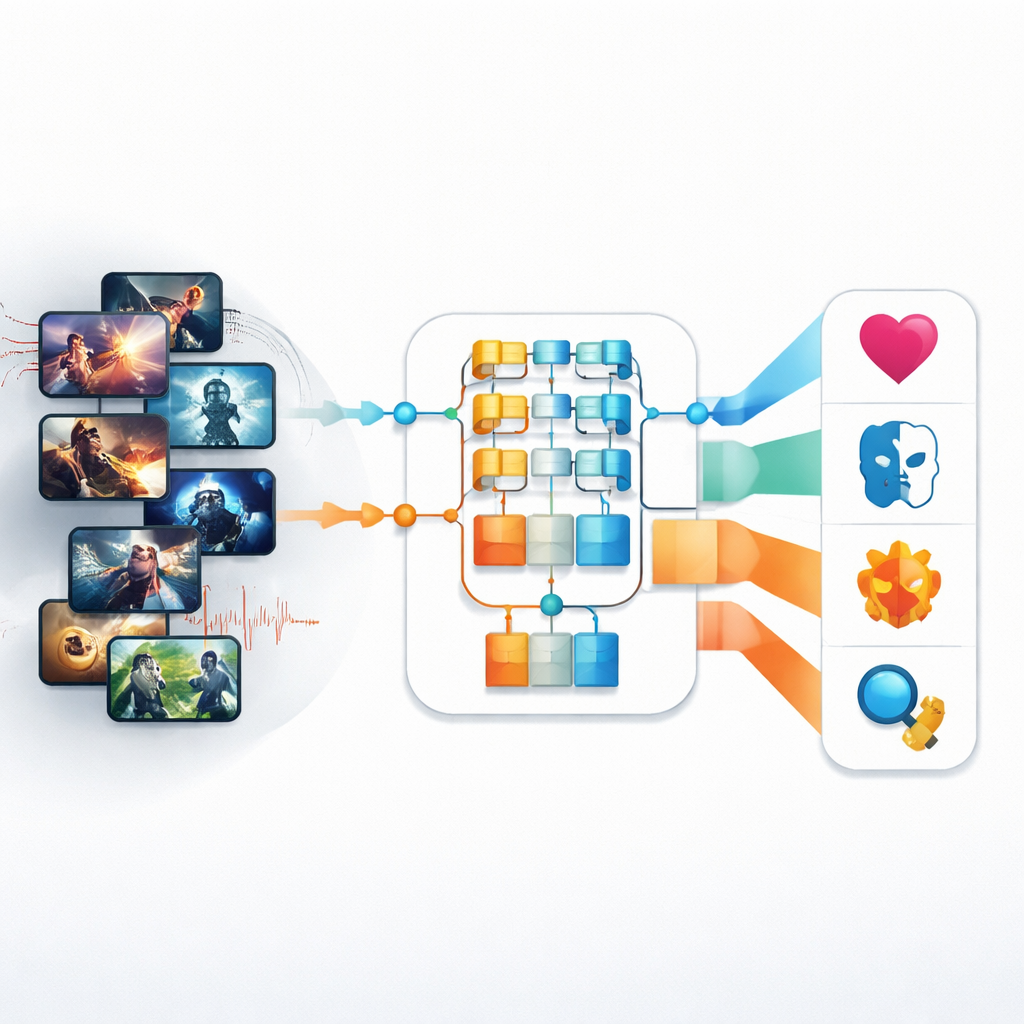
Van eenvoudige beeldsignalen naar rijke videoverwerking
Eerste pogingen tot automatische genreherkenning leunden op betrekkelijk grove visuele aanwijzingen: algemene kleur, basistekstuuren of simpele bewegingenschattingen. Die methoden worstelden met de complexe televisie van vandaag, waar belichting, tempo en emotie van moment tot moment veranderen. De auteurs pakken deze uitdaging eerst aan met een nieuwer soort beeldmodel, de Pyramid Vision Transformer (PvT). In plaats van alleen kleine beeldpatches te scannen, bouwt deze aanpak een gelaagde blik die zowel fijne details als de bredere opzet van een scène vastlegt. Toegepast op een dataset van bijna 4.500 tv-productiebeelden die vier genres beslaan — Actie, Animatie, Romantiek en Horror — leert de PvT welke combinaties van belichting, kadering en compositie vaak op een bepaalde categorie wijzen.
Machines leren luisteren en kijken
Televisiegenres worden evenzeer door geluid als door beeld gedefinieerd: daverende muziek in een actiontrailer, gespannen drones in een thriller, zachte melodieën in een romance. Om dit vast te leggen introduceren de auteurs een multimodaal model dat ze MAiVAR-T noemen, dat videoframes en audio samen verwerkt. Voor elke trailer selecteren ze sleutelbeelden die belangrijke visuele momenten representeren, en koppelen die aan meerdere weergaven van de soundtrack: ruwe golfvormen, ritme en luidheid in de tijd, en compacte samenvattingen van toonhoogte en harmonie. MAiVAR-T volgt twee parallelle paden — één voor beelden, één voor audio — voordat ze samengevoegd worden. Een gespecialiseerde fusiefase leert wat er op het scherm gebeurt af te stemmen op wat er in de luidsprekers gebeurt, zodat bijvoorbeeld een donkere gang gekoppeld aan plotselinge scherpe geluiden anders wordt behandeld dan een vergelijkbaar beeld ondersteund door zachte muziek. 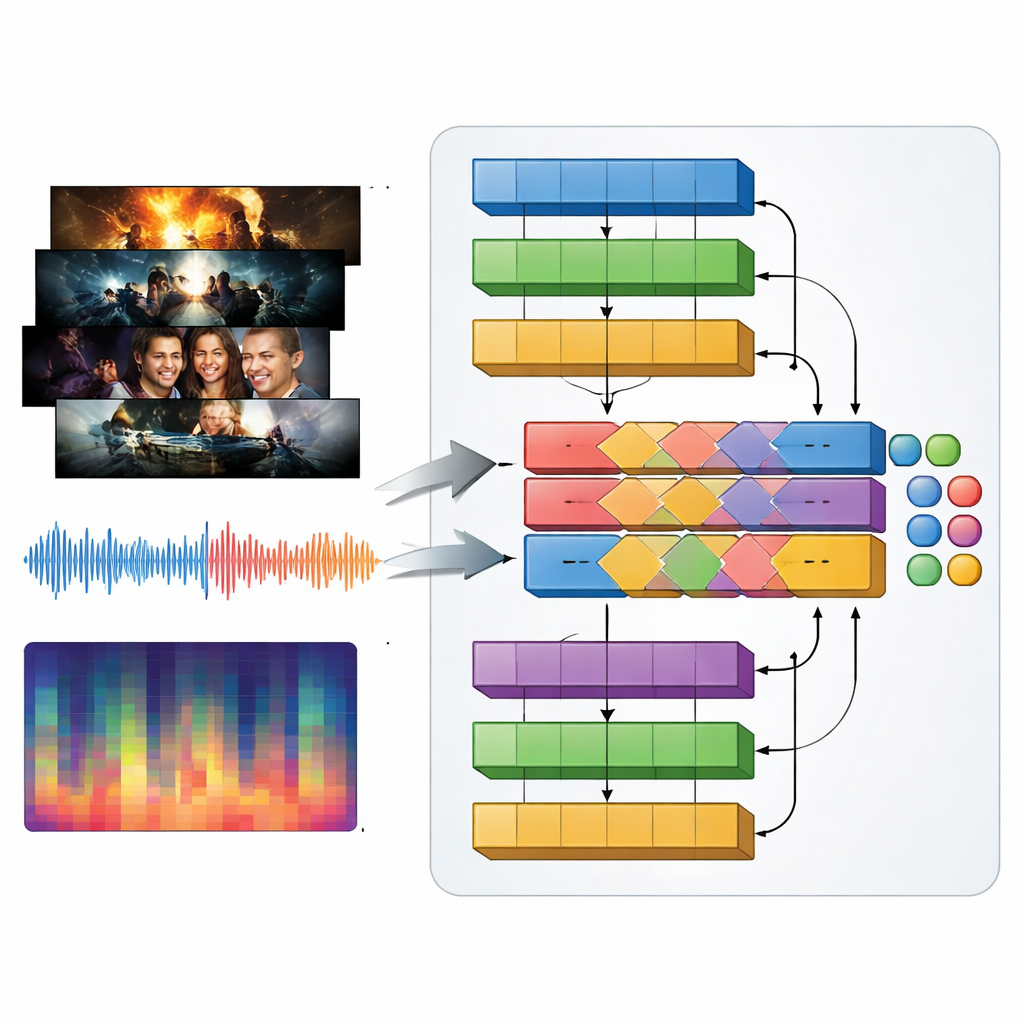
Hoe goed de nieuwe aanpak presteert
De onderzoekers hebben hun modellen aan strenge tests onderworpen tegenover een breed scala aan gevestigde systemen, waaronder klassieke convolutionele neurale netwerken en recentere transformer-gebaseerde ontwerpen. Op de beeld-only dataset behaalde de PvT ongeveer 95% algemene nauwkeurigheid en overtrof daarmee populaire alternatieven zoals NASNet en andere vision transformers. Op een veel grotere en gevarieerdere verzameling film- en tv-trailers die elf genres beslaat, bereikte MAiVAR-T rond de 98% nauwkeurigheid. Die prestaties waren beter dan oudere multimodale ontwerpen die geluid en beeld losser combineerden, evenals sterke single-modality modellen die alleen naar frames of alleen naar audio keken. Zorgvuldige statistische controles toonden aan dat deze winst niet door toeval kwam, en interpretatiehulpmiddelen zoals Grad-CAM en LIME bevestigden dat de modellen zich richten op zinvolle aanwijzingen zoals beweging van personages, belichting en veranderingen in muzikale intensiteit.
Wat dit kan betekenen voor kijkers en makers
Hoge-accuratesse genreherkenning klinkt misschien als een technisch detail, maar het ligt ten grondslag aan veel alledaagse ervaringen, van de rijen aanbevelingen op je streamingstartpagina tot de manier waarop omroepen hun archieven doorzoeken op clips en hoogtepunten. Door betrouwbaar rijke patronen van zicht en geluid te koppelen aan menselijke noties van genre, kunnen systemen als PvT en MAiVAR-T producenten helpen enorme contentbibliotheken te beheren, slimmere aanbevelingsmachines ondersteunen en zelfs montage- en trailerontwerp sturen. De auteurs merken op dat meer diverse data en betere verwerking van programma’s die meerdere genres mengen belangrijke volgende stappen zullen zijn, evenals aandacht voor ethisch gebruik. Toch laten hun resultaten zien dat transformers die zowel zien als horen klaarstaan om krachtige assistenten te worden in het organiseren en begrijpen van het steeds groter wordende universum van digitale media.
Bronvermelding: Alarfaj, F.K., Naz, A. Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media. Sci Rep 16, 14543 (2026). https://doi.org/10.1038/s41598-026-45087-y
Trefwoorden: videogenreherkenning, vision transformers, multimodale AI, televisie-analyse, audio-visuele analyse