Clear Sky Science · es
Explorando transformadores de visión para extracción profunda de características y clasificación en el reconocimiento de géneros de video para medios digitales
Por qué importa una clasificación más inteligente de la TV
Los servicios de streaming y los canales de televisión gestionan hoy un océano de series, películas y clips en estilos que van desde la acción trepidante hasta el romance tranquilo. Detrás de escena, alguien —o algo— debe decidir de qué trata cada contenido para que pueda ser encontrado, recomendado y programado. Este artículo explora nuevas herramientas de inteligencia artificial que pueden reconocer automáticamente el género de contenidos televisivos y de video observando tanto lo que se ve en pantalla como lo que se oye en la banda sonora, prometiendo formas más rápidas y precisas de organizar el mundo mediático moderno. 
De pistas visuales simples a una comprensión rica del video
Los primeros intentos de reconocimiento automático de géneros se apoyaban en pistas visuales bastante burdas: color general, texturas básicas o estimaciones simples de movimiento. Esos métodos tenían dificultades con la televisión actual, donde la iluminación, el ritmo y la emoción cambian de un momento a otro. Los autores abordan primero este desafío utilizando un tipo más reciente de modelo de imagen llamado Pyramid Vision Transformer (PvT). En lugar de escanear solo pequeños parches de una imagen, este enfoque construye una visión en capas que captura tanto los detalles finos como la disposición global de la escena. Aplicado a un conjunto de datos de casi 4.500 imágenes de producciones televisivas que cubren cuatro géneros —Acción, Animación, Romance y Terror—, el PvT aprende qué combinaciones de iluminación, encuadre y composición suelen señalar cada categoría.
Enseñar a las máquinas a escuchar además de ver
Los géneros televisivos se definen tanto por el sonido como por lo visual: música contundente en un tráiler de acción, zumbidos tensos en un thriller, melodías suaves en un romance. Para capturar esto, los autores presentan un modelo multimodal al que llaman MAiVAR-T, que procesa fotogramas de video y audio conjuntamente. Para cada tráiler, seleccionan fotogramas clave que representan momentos visuales importantes y los emparejan con múltiples vistas de la banda sonora: formas de onda crudas, ritmo y sonoridad a lo largo del tiempo, y resúmenes compactos de tono y armonía. MAiVAR-T sigue dos vías paralelas —una para imágenes y otra para audio— antes de fusionarlas. Una etapa de fusión especializada aprende a alinear lo que ocurre en pantalla con lo que suena en los altavoces, de modo que, por ejemplo, un pasillo oscuro acompañado de sonidos agudos repentinos se trate de manera distinta a una imagen similar respaldada por música suave. 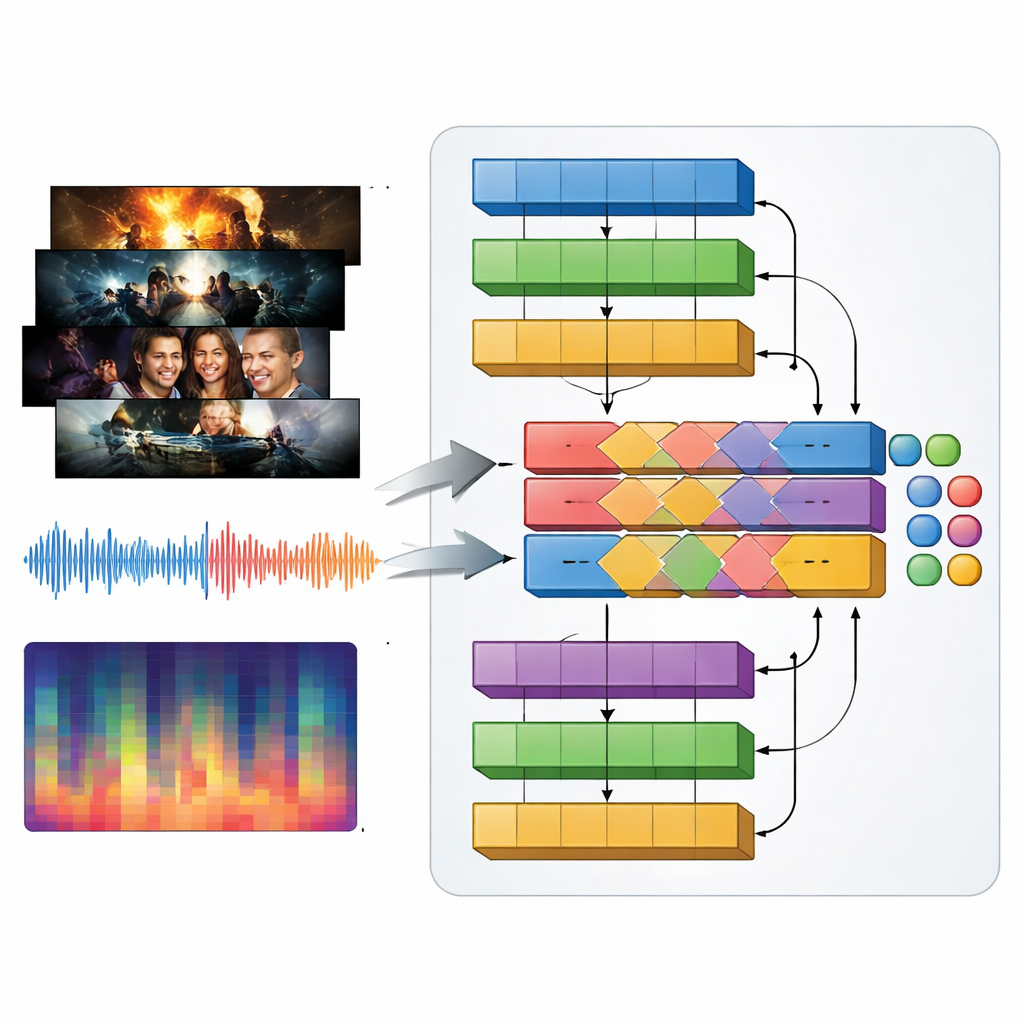
Qué tan bien funciona el nuevo enfoque
Los investigadores sometieron sus modelos a pruebas rigurosas frente a una amplia gama de sistemas consolidados, incluidos redes neuronales convolucionales clásicas y diseños más recientes basados en transformadores. En el conjunto de datos solo de imágenes, el PvT alcanzó aproximadamente un 95% de precisión global, superando alternativas populares como NASNet y otros transformadores de visión. En una colección mucho mayor y más variada de tráilers de películas y televisión que abarcaba once géneros, MAiVAR-T consiguió alrededor de un 98% de precisión. Ese rendimiento superó a diseños multimodales más antiguos que combinaban sonido e imagen de forma más laxa, así como a potentes modelos de una sola modalidad que solo analizaban fotogramas o solo audio. Controles estadísticos cuidadosos mostraron que estas mejoras no se debieron al azar, y herramientas de interpretabilidad como Grad-CAM y LIME confirmaron que los modelos se centran en pistas razonables como el movimiento de los personajes, la iluminación y los cambios en la intensidad musical.
Qué podría significar esto para espectadores y creadores
El reconocimiento de géneros con alta precisión puede parecer un detalle técnico, pero sustenta muchas experiencias cotidianas, desde las filas de recomendaciones en la pantalla principal de tu servicio de streaming hasta la forma en que las emisoras buscan en sus archivos clips y destacados. Al conectar de forma fiable patrones ricos de vista y sonido con nociones humanas de género, sistemas como PvT y MAiVAR-T podrían ayudar a los productores a gestionar vastas bibliotecas de contenido, respaldar motores de recomendación más inteligentes e incluso orientar la edición y el diseño de tráilers. Los autores señalan que disponer de datos más diversos y manejar mejor los programas que mezclan varios géneros serán pasos importantes siguientes, al igual que vigilar el uso ético. Aun así, sus resultados muestran que los transformadores que ven y oyen están preparados para convertirse en asistentes potentes en la organización y comprensión del universo cada vez mayor de medios digitales.
Cita: Alarfaj, F.K., Naz, A. Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media. Sci Rep 16, 14543 (2026). https://doi.org/10.1038/s41598-026-45087-y
Palabras clave: reconocimiento de géneros de video, transformadores de visión, IA multimodal, analítica televisiva, análisis audiovisual