Clear Sky Science · fr
Exploration des vision transformers pour l'extraction profonde de caractéristiques et la classification dans la reconnaissance de genres vidéo pour les médias numériques
Pourquoi un tri télévisuel plus intelligent compte
Les services de streaming et les chaînes de télévision gèrent aujourd’hui un océan de séries, films et clips couvrant tous les styles, de l’action effrénée à la romance intimiste. En coulisses, quelqu’un — ou quelque chose — doit déterminer ce que représente chaque contenu pour qu’il puisse être retrouvé, recommandé et programmé. Cet article explore de nouveaux outils d’intelligence artificielle capables de reconnaître automatiquement le genre des contenus télévisuels et vidéo en analysant à la fois ce que l’on voit à l’écran et ce que l’on entend dans la bande sonore, offrant des moyens plus rapides et plus précis d’organiser le monde moderne des médias. 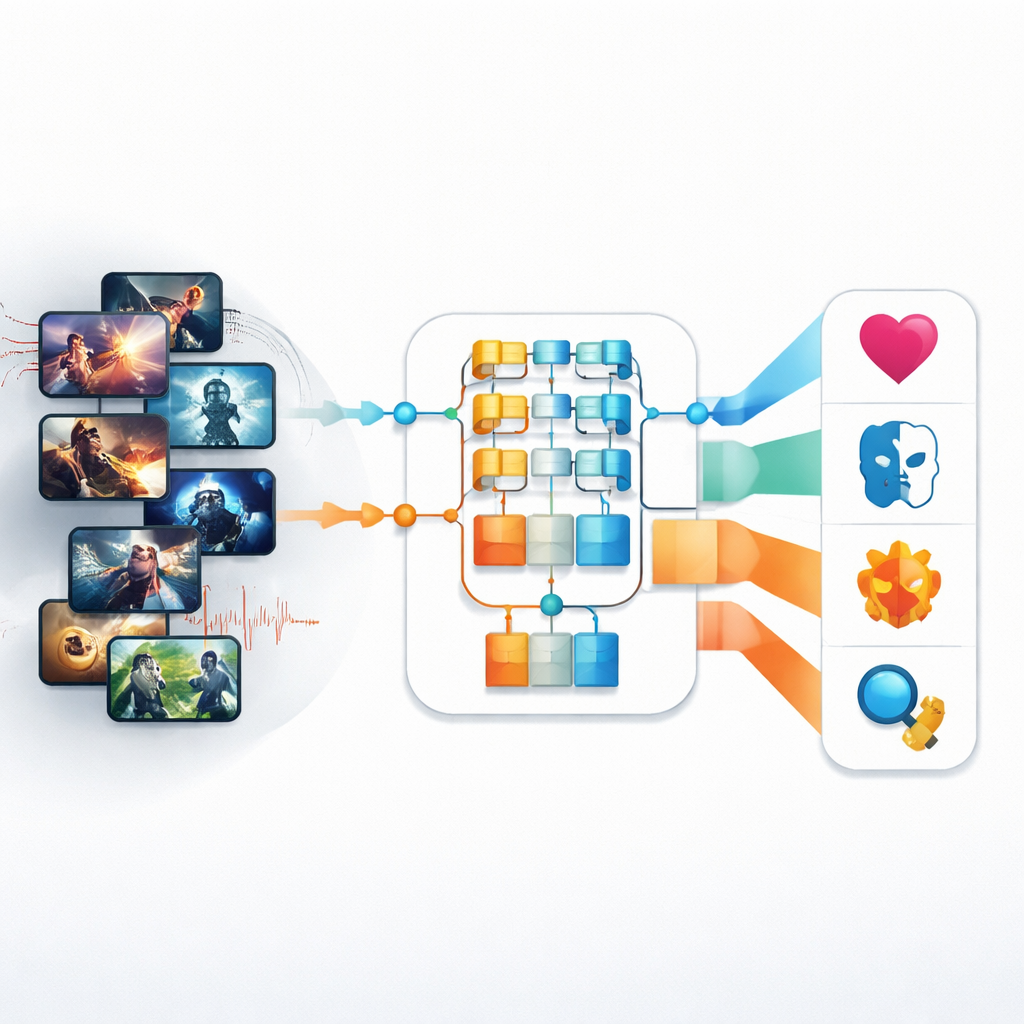
Des indices visuels simples à une compréhension vidéo riche
Les premières tentatives de reconnaissance automatique de genre se fondaient sur des indices visuels assez rudimentaires : couleur globale, textures basiques ou estimations simples du mouvement. Ces méthodes peinaient face à la télévision contemporaine, où l’éclairage, le rythme et l’émotion changent d’un instant à l’autre. Les auteurs abordent d’abord ce défi en utilisant un type plus récent de modèle d’image appelé Pyramid Vision Transformer (PvT). Plutôt que d’analyser uniquement de petits patchs d’image, cette approche construit une vue en couches qui capture à la fois les détails fins et la disposition plus large d’une scène. Appliqué à un jeu de données d’environ 4 500 images de productions télévisuelles réparties en quatre genres — Action, Animation, Romance et Horreur — le PvT apprend quelles combinaisons d’éclairage, de cadrage et de composition tendent à signaler chaque catégorie.
Apprendre aux machines à écouter autant qu’à regarder
Les genres télévisuels se définissent autant par le son que par l’image : musique percutante dans une bande-annonce d’action, drones tendus dans un thriller, mélodies délicates dans une romance. Pour rendre cela capturable, les auteurs présentent un modèle multimodal qu’ils appellent MAiVAR-T, qui traite simultanément les images vidéo et l’audio. Pour chaque bande-annonce, ils sélectionnent des images-clés représentant des moments visuels importants, puis les associent à plusieurs représentations de la bande sonore : formes d’onde brutes, rythme et sonie au fil du temps, et résumés compacts de hauteur et d’harmonie. MAiVAR-T suit deux voies parallèles — l’une pour les images, l’autre pour l’audio — avant de les fusionner. Une étape de fusion spécialisée apprend à aligner ce qui se passe à l’écran avec ce qui se passe dans les haut-parleurs, de sorte que, par exemple, un couloir sombre accompagné de sons soudains et aigus soit traité différemment d’une image similaire soutenue par une musique douce. 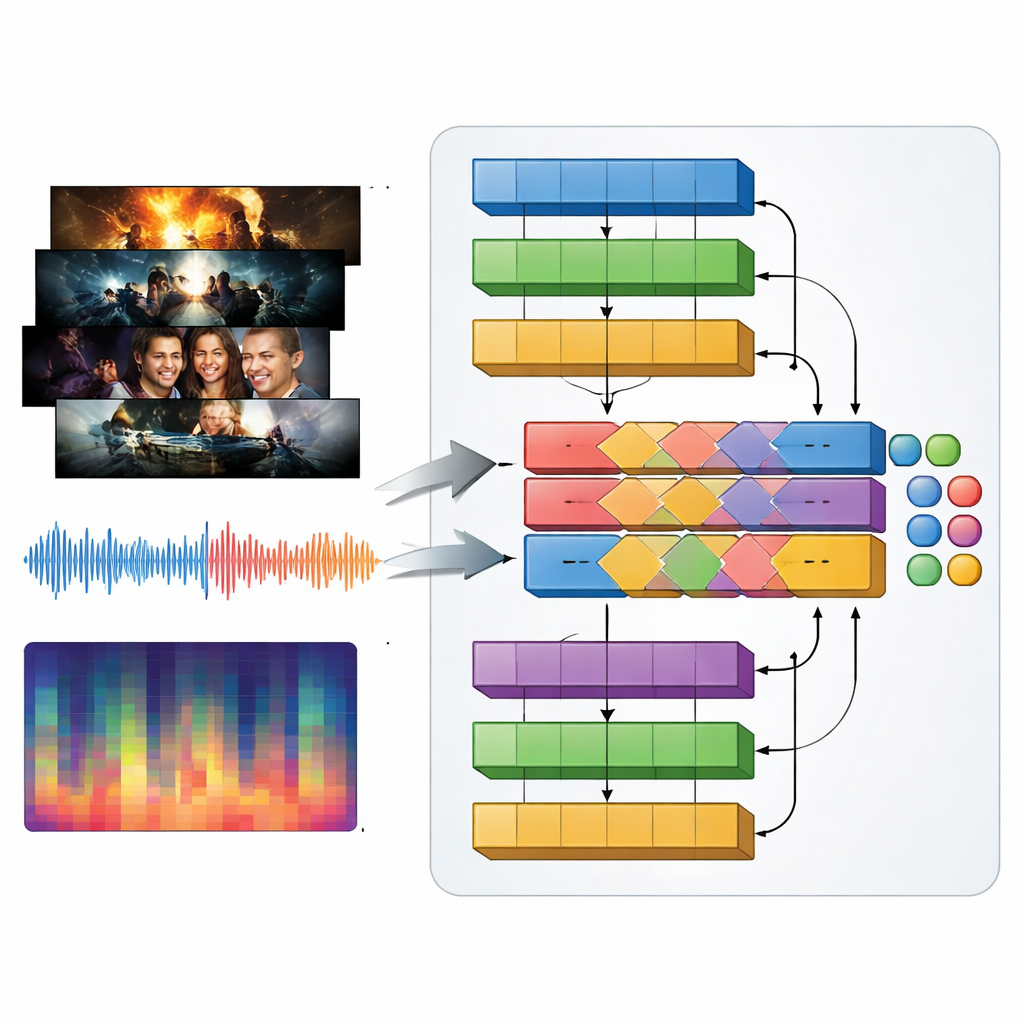
Quelle est la performance de la nouvelle approche
Les chercheurs ont soumis leurs modèles à des tests rigoureux face à un large éventail de systèmes établis, incluant des réseaux de neurones convolutionnels classiques et des architectures récentes basées sur des transformers. Sur le jeu de données d’images seules, le PvT a atteint environ 95 % de précision globale, surpassant des alternatives populaires telles que NASNet et d’autres vision transformers. Sur une collection beaucoup plus vaste et variée de bandes-annonces de films et de séries couvrant onze genres, MAiVAR-T a obtenu près de 98 % de précision. Cette performance a dépassé celle des conceptions multimodales plus anciennes qui combinaient son et image de manière moins étroite, ainsi que des modèles mono-modaux performants qui ne regardaient que les images ou que l’audio. Des contrôles statistiques rigoureux ont montré que ces gains n’étaient pas dus au hasard, et des outils d’interprétabilité tels que Grad-CAM et LIME ont confirmé que les modèles se focalisent sur des indices cohérents comme le mouvement des personnages, l’éclairage et les variations d’intensité musicale.
Ce que cela pourrait signifier pour les spectateurs et les créateurs
La reconnaissance de genre à haute précision peut sembler un détail technique, mais elle sous-tend de nombreuses expériences quotidiennes, des rangées de recommandations sur l’écran d’accueil de votre service de streaming à la manière dont les diffuseurs recherchent des extraits et des moments forts dans leurs archives. En reliant de façon fiable des motifs riches de vue et de son aux notions humaines de genre, des systèmes comme PvT et MAiVAR-T pourraient aider les producteurs à gérer d’immenses bibliothèques de contenu, soutenir des moteurs de recommandation plus intelligents et même guider le montage et la conception de bandes-annonces. Les auteurs notent que des données plus diverses et une meilleure prise en compte des œuvres mêlant plusieurs genres seront des étapes importantes, tout comme la vigilance sur l’usage éthique. Néanmoins, leurs résultats montrent que des transformers qui voient et écoutent sont prêts à devenir des assistants puissants pour organiser et comprendre l’univers toujours croissant des médias numériques.
Citation: Alarfaj, F.K., Naz, A. Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media. Sci Rep 16, 14543 (2026). https://doi.org/10.1038/s41598-026-45087-y
Mots-clés: reconnaissance de genre vidéo, vision transformers, IA multimodale, analyse télévisuelle, analyse audio-visuelle