Clear Sky Science · en
Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media
Why smarter TV sorting matters
Streaming services and TV channels now handle an ocean of shows, movies, and clips in every style from fast-paced action to quiet romance. Behind the scenes, someone—or something—has to decide what each piece of content is so it can be found, recommended, and scheduled. This paper explores new artificial intelligence tools that can automatically recognize the genre of TV and video content by looking at both what you see on the screen and what you hear in the soundtrack, promising faster, more accurate ways to organize the modern media world. 
From simple picture clues to rich video understanding
Early attempts at automatic genre recognition leaned on fairly crude visual cues: overall color, basic textures, or simple motion estimates. Those methods struggled with today’s complex television, where lighting, pacing, and emotion shift from moment to moment. The authors first tackle this challenge using a newer kind of image model called a Pyramid Vision Transformer (PvT). Instead of scanning only small patches of an image, this approach builds a layered view that captures both fine details and the broader layout of a scene. Applied to a dataset of nearly 4,500 TV production images spanning four genres—Action, Animation, Romance, and Horror—the PvT learns which combinations of lighting, framing, and composition tend to signal each category.
Teaching machines to listen as well as look
Television genres are defined as much by sound as by visuals: pounding music in an action trailer, tense drones in a thriller, gentle melodies in a romance. To capture this, the authors introduce a multimodal model they call MAiVAR-T, which processes video frames and audio together. For each trailer, they select key frames that represent important visual moments, then pair them with multiple views of the soundtrack: raw waveforms, rhythm and loudness over time, and compact summaries of pitch and harmony. MAiVAR-T follows two parallel pathways—one for images, one for audio—before merging them. A specialized fusion stage learns to align what is happening on screen with what is happening in the speakers, so that, for example, a dark corridor paired with sudden sharp sounds is treated differently from a similar image backed by gentle music. 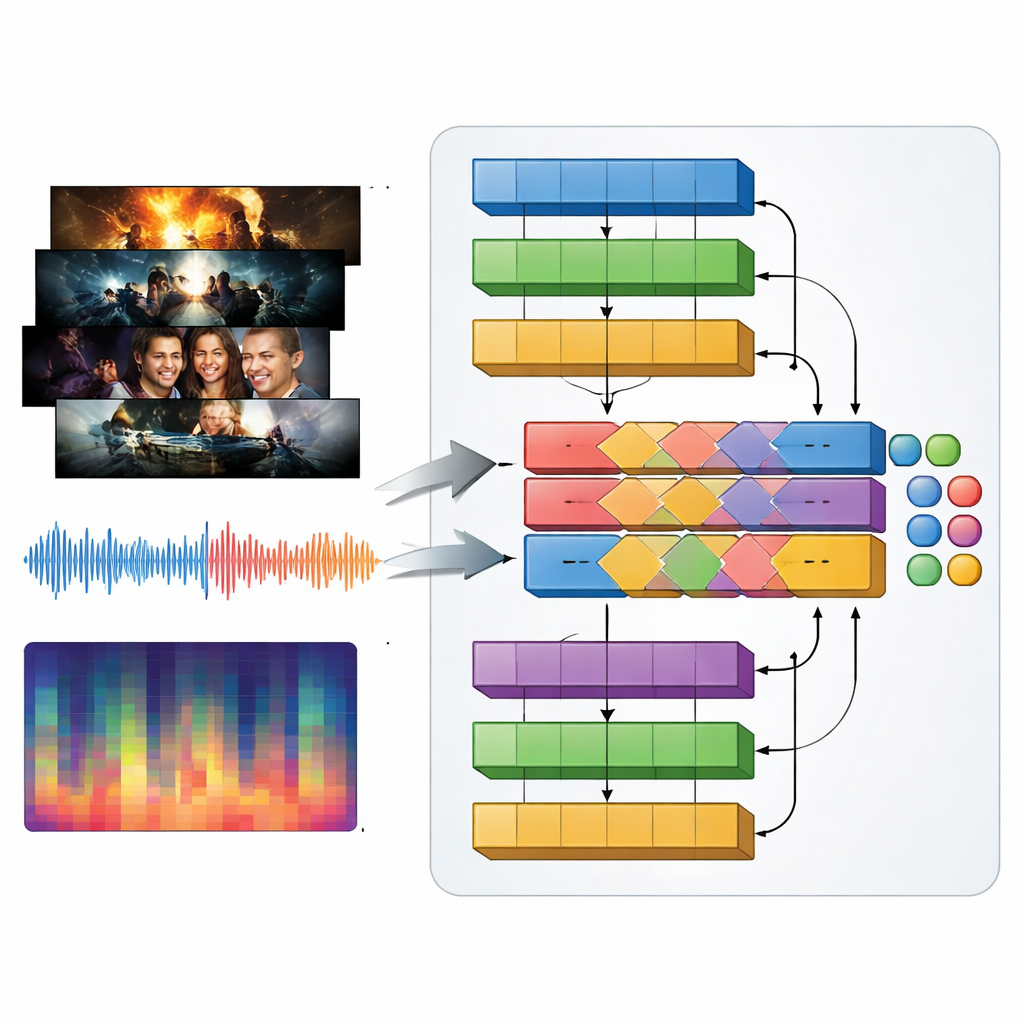
How well the new approach performs
The researchers put their models through rigorous tests against a wide range of established systems, including classic convolutional neural networks and more recent transformer-based designs. On the image-only dataset, the PvT reached about 95% overall accuracy, surpassing popular alternatives such as NASNet and other vision transformers. On a much larger and more varied collection of movie and TV trailers covering eleven genres, MAiVAR-T achieved around 98% accuracy. That performance outstripped older multimodal designs that combined sound and picture more loosely, as well as strong single-modality models that looked only at frames or only at audio. Careful statistical checks showed that these gains were not due to chance, and interpretability tools such as Grad-CAM and LIME confirmed that the models focus on sensible cues like character motion, lighting, and changes in musical intensity.
What this could mean for viewers and creators
High-accuracy genre recognition may sound like a technical detail, but it underpins many everyday experiences, from the rows of recommendations on your streaming home screen to the way broadcasters search their archives for clips and highlights. By reliably connecting rich patterns of sight and sound to human notions of genre, systems like PvT and MAiVAR-T could help producers manage vast libraries of content, support smarter recommendation engines, and even guide editing and trailer design. The authors note that more diverse data and better handling of shows that blend multiple genres will be important next steps, as will keeping an eye on ethical use. Still, their results show that transformers that both see and hear are poised to become powerful assistants in organizing and understanding the ever-growing universe of digital media.
Citation: Alarfaj, F.K., Naz, A. Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media. Sci Rep 16, 14543 (2026). https://doi.org/10.1038/s41598-026-45087-y
Keywords: video genre recognition, vision transformers, multimodal AI, television analytics, audio visual analysis