Clear Sky Science · he
חקר ויז'ן טרנספורמרים לחילוץ תכונות עמוקות וסיווג בזיהוי ז'אנרים של וידאו במדיה דיגיטלית
למה מיון חכם יותר של טלוויזיה חשוב
שירותי הזרמה וערוצי טלוויזיה מתמודדים היום עם ים של תוכניות, סרטים וקליפים בכל סגנון — מהאקשן המהיר ועד הרומנטיקה השקטה. מאחורי הקלעים, מישהו — או משהו — צריך להחליט מהו סוג התוכן כדי שאפשר יהיה למצוא, להמליץ ולתזמן אותו. מאמר זה חוקר כלים חדשים של בינה מלאכותית שיכולים לזהות באופן אוטומטי את הז'אנר של תוכן טלוויזיה ווידאו על ידי בחינת מה שרואים על המסך ומה ששומעים בפסקול, ומבטיחים דרכים מהירות ומדויקות יותר לארגון עולם המדיה המודרני. 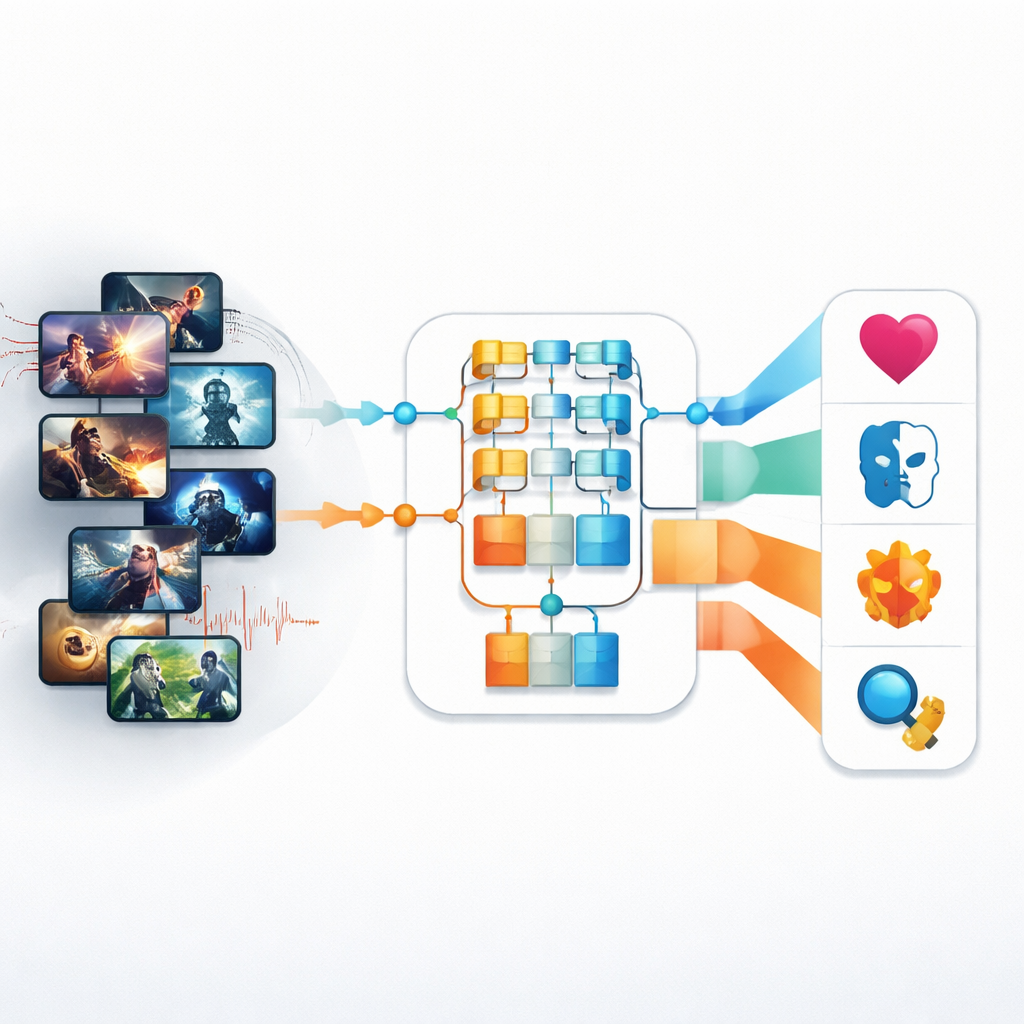
מאותות תמונה פשוטים להבנה עשירה של וידאו
ניסיונות מוקדמים בזיהוי ז'אנרים אוטומטי הסתמכו על רמזים חזותיים גסים יחסית: צבע כולל, טקסטורות בסיסיות או הערכות תנועה פשוטות. שיטות אלה התקשו מול הטלוויזיה המורכבת של היום, שבה תאורה, קצב ורגשות משתנים מרגע לרגע. המחברים מתמודדים עם אתגר זה תחילה באמצעות סוג חדש של מודל תמונה הנקרא Pyramid Vision Transformer (PvT). במקום לסרוק רק חתיכות קטנות של תמונה, גישה זו בונה מבט רב-שכבתי הלוכד גם פרטים עדינים וגם את הפריסה הרחבה של הסצנה. כשמיישמים אותה על מאגר נתונים של כמעט 4,500 תמונות הפקה טלוויזיוניות שמכסות ארבעה ז'אנרים — אקשן, אנימציה, רומנטיקה ואימה — ה-PvT לומד אילו שילובים של תאורה, מסגור והרכבה נוטים לסמן כל קטגוריה.
להנחות מכונות להקשיב כפי שהן רואות
ז'אנרים טלוויזיוניים מוגדרים לא פחות על ידי קול מאשר על ידי חזות: מוזיקה מחאבת במקדמה של אקשן, דרונים מתוחים בסרט מתח, מלודיות עדינות ברומנטיקה. כדי ללכוד זאת, המחברים מציגים מודל מולטימודלי שהם קוראים לו MAiVAR-T, שמעבד מסגרות וידאו ואודיו יחד. עבור כל קדימון הם בוחרים מסגרות מפתח המייצגות רגעים חזותיים חשובים, ואז מצמדים אותם למספר מבטים של הפסקול: גלציית גולמית, קצב ונפח לאורך זמן וסיכומים קומפקטיים של גובה צליל והרמוניה. MAiVAR-T פועל בשתי מסלולים מקבילים — אחד לתמונות ואחד לאודיו — לפני מיזוגם. שלב מיזוג מיוחד לומד ליישר מה שקורה על המסך עם מה שקורה ברמקולים, כך שלמשל מסדרון חשוך בצירוף צלילים חדים פתאומיים יטופל אחרת מתמונה דומה הנתמכת במוזיקה עדינה. 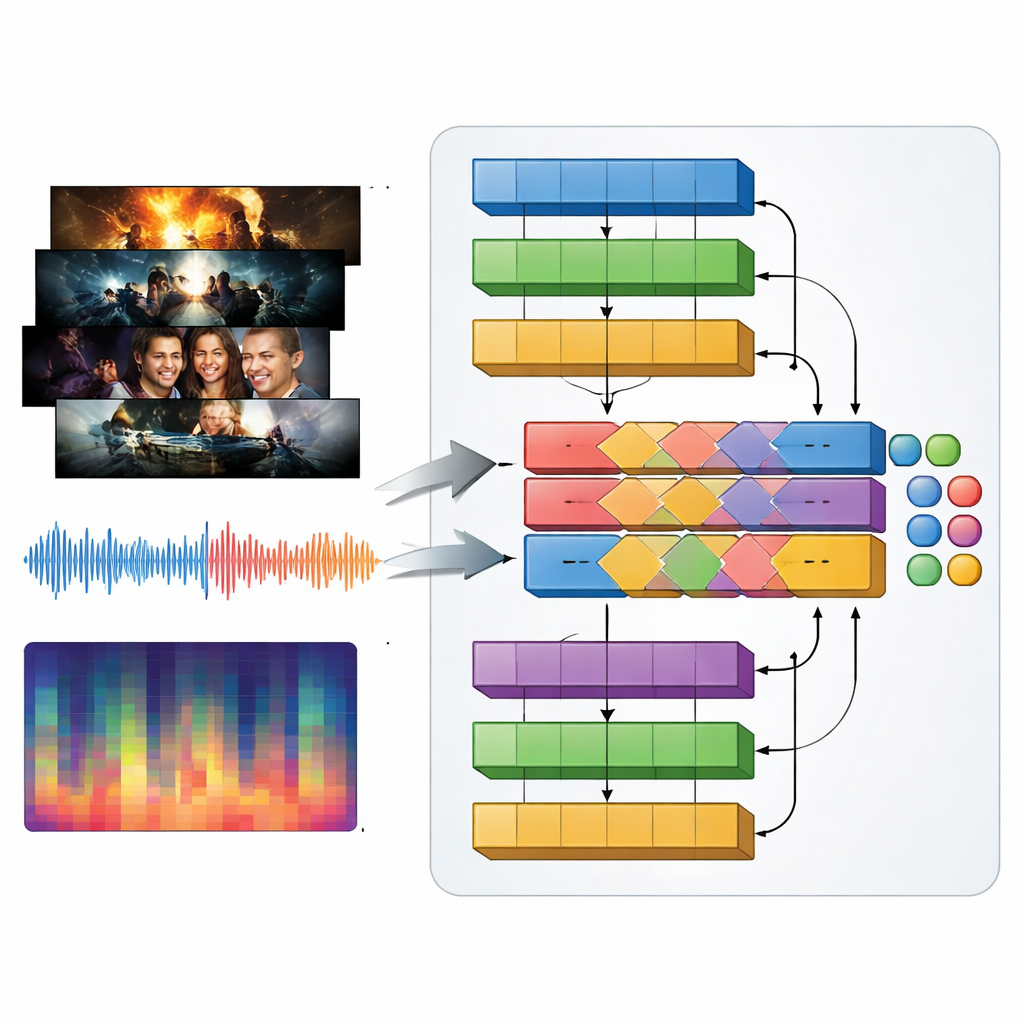
כמה טוב השיטה החדשה מופיעה
החוקרים בחנו את המודלים שלהם בבדיקות קפדניות אל מול מערכות מבוססות רבות, כולל רשתות עצביות קונבולוציוניות קלאסיות ועיצובים מבוססי טרנספורמרים עדכניים יותר. על מאגר התמונות בלבד, ה-PvT הגיע לדייקנות כוללת של כ-95%, תוך שהוא עוקף חלופות פופולריות כמו NASNet וטרנספורמרים חזותיים אחרים. על אוסף גדול ומגוון בהרבה של טריילרים לסרטים ולטלוויזיה המכסה אחד עשר ז'אנרים, MAiVAR-T השיג כ-98% דיוק. ביצועים אלה עלו על עיצובים מולטימודליים ישנים ששילבו קול ותמונה באופן רופף יותר, וכן על מודלים חזקים במודאליות יחידה שהתבססו רק על מסגרות או רק על אודיו. בדיקות סטטיסטיות קפדניות הראו שהשיפורים אינם מקריים, וכלי פרשנות כגון Grad-CAM ו-LIME אישרו שהמודלים מתמקדים ברמזים הגיוניים כמו תנועת דמויות, תאורה ושינויים בעצימות המוזיקה.
מה זה יכול לעולל לצופים וליוצרים
זיהוי ז'אנרים ברמת דיוק גבוהה עשוי להישמע פרט טכני, אבל הוא מהווה את הבסיס להרבה חוויות יומיומיות — משורות ההמלצות במסך הבית של שירות ההזרמה שלך ועד לאופן שבו שדרנים מחפשים בארכיוניהם קטעים והבלטים. על ידי חיבור אמין של דפוסים עשירים של ראייה ושמע למושגי הז'אנר האנושיים, מערכות כמו PvT ו-MAiVAR-T יכולות לסייע למפיקים לנהל ספריות תוכן עצומות, לתמוך במנגנוני המלצה חכמים ואפילו להנחות בעריכה ובעיצוב קדימונים. המחברים מציינים ששלבים הבאים החשובים יהיו נתונים מגוונים יותר וטיפול משופר בתוכניות שמשלבות מספר ז'אנרים, וכן תשומת לב לשימוש אתי. עם זאת, התוצאות שלהם מראות שטרנספורמרים שיראו וישמעו גם יחד עומדים להפוך לעוזרים רבי עוצמה בארגון ובהבנה של היקום המתפתח ללא הרף של המדיה הדיגיטלית.
ציטוט: Alarfaj, F.K., Naz, A. Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media. Sci Rep 16, 14543 (2026). https://doi.org/10.1038/s41598-026-45087-y
מילות מפתח: זיהוי ז'אנר וידאו, ויז'ן טרנספורמרים, בינה מלאכותית מולטימודלית, אנליטיקה טלוויזיונית, ניתוח אודיו-ויזואלי