Clear Sky Science · sv
Utforska vision-transformers för djup funktionsutvinning och klassificering vid videogenreigenkänning för digitala medier
Varför smartare TV-sortering spelar roll
Streamingtjänster och TV-kanaler hanterar nu ett hav av program, filmer och klipp i alla stilar — från snabb action till stillsam romantik. Bakom kulisserna måste någon — eller något — bestämma vad varje innehållsbit är så att den kan hittas, rekommenderas och schemaläggas. Denna artikel undersöker nya artificiella intelligensverktyg som automatiskt kan känna igen genren för TV- och videoinnehåll genom att analysera både vad du ser på skärmen och vad du hör i ljudspåret, vilket lovar snabbare och mer precisa sätt att organisera den moderna medievärlden. 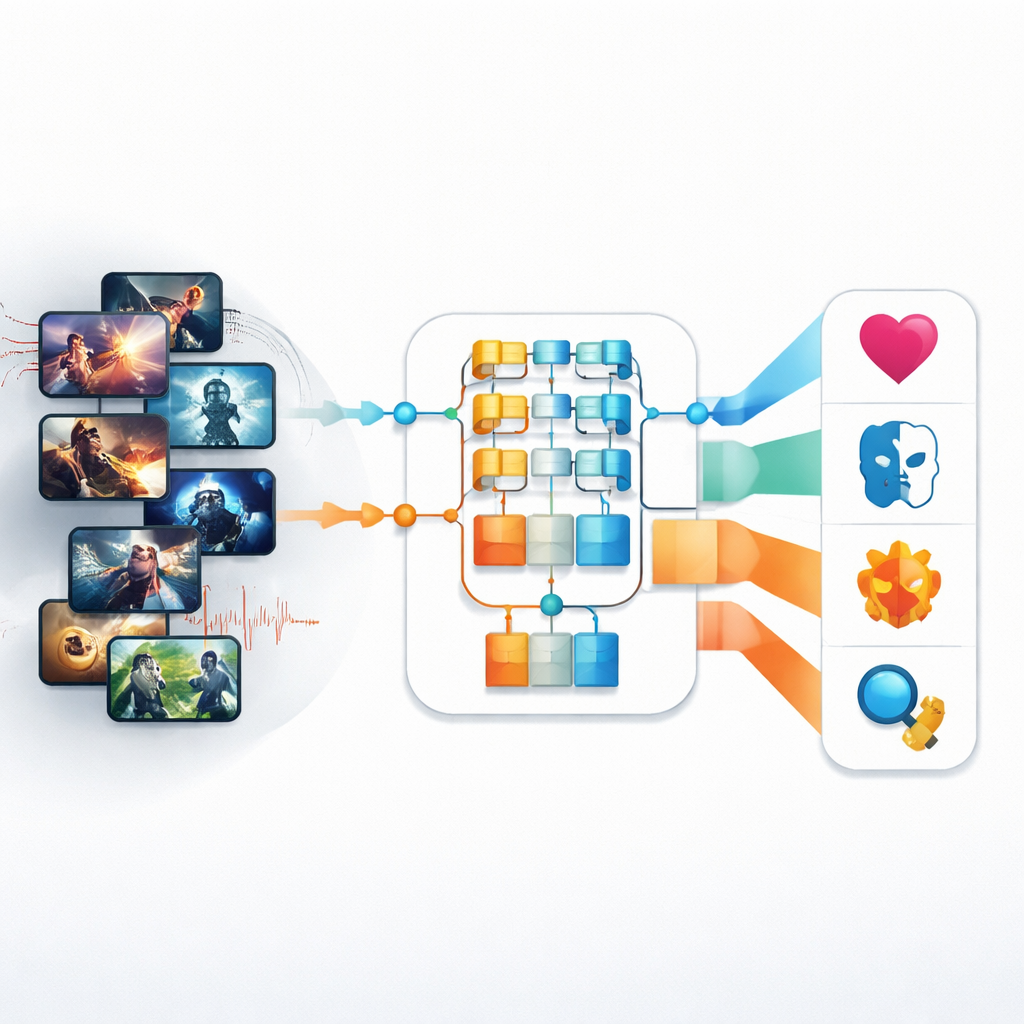
Från enkla bildledtrådar till rik videoförståelse
Tidiga försök att automatiskt känna igen genrer förlitade sig på ganska grova visuella ledtrådar: övergripande färg, grundläggande texturer eller enkla rörelseuppskattningar. Dessa metoder hade svårt med dagens komplexa television, där ljussättning, takt och känslouttryck skiftar från ögonblick till ögonblick. Författarna tar sig först an denna utmaning med en nyare typ av bildmodell kallad Pyramid Vision Transformer (PvT). Istället för att bara skanna små bildpatchar bygger denna metod en flerskiktsvy som fångar både fina detaljer och den bredare scenens uppbyggnad. Tillämpad på en datamängd med nästan 4 500 TV-produktionsbilder som täcker fyra genrer — Action, Animation, Romantik och Skräck — lär sig PvT vilka kombinationer av ljussättning, inramning och komposition som tenderar att signalera varje kategori.
Att lära maskiner att lyssna lika bra som att se
TV-genrer definieras lika mycket av ljud som av visuella element: dundrande musik i en actiontrailer, spända droner i en thriller, milda melodier i en romantik. För att fånga detta introducerar författarna en multimodal modell de kallar MAiVAR-T, som bearbetar videoramar och ljud tillsammans. För varje trailer väljer de ut nyckelramar som representerar viktiga visuella ögonblick, och parar dem med flera vyer av ljudspåret: råa vågformer, rytm och ljudstyrka över tid, samt kompakta sammanfattningar av tonhöjd och harmoni. MAiVAR-T följer två parallella vägar — en för bilder, en för ljud — innan de slås ihop. En specialiserad sammanslagningsfas lär sig att alignera vad som händer på skärmen med vad som händer i ljudspåret, så att till exempel en mörk korridor ihop med plötsliga skarpa ljud behandlas annorlunda än en liknande bild understödd av mild musik. 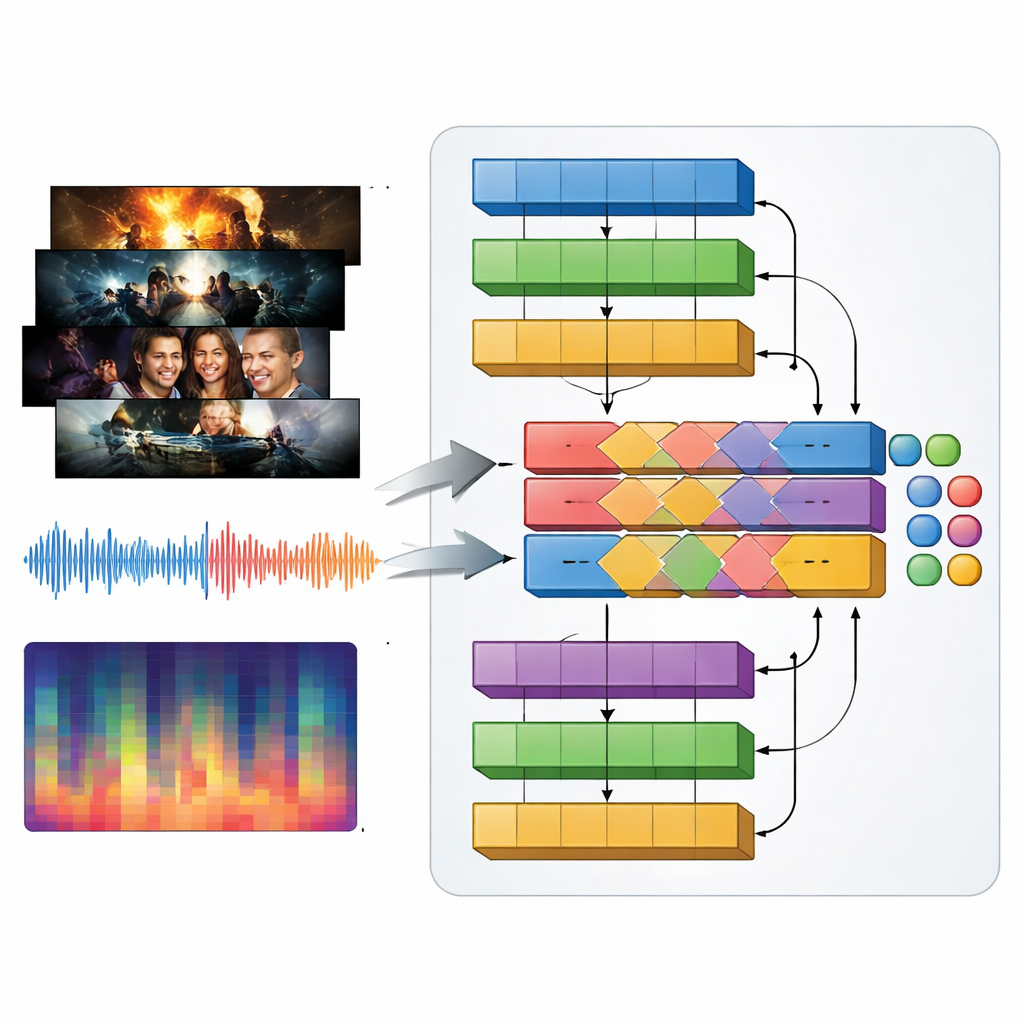
Hur bra den nya metoden presterar
Forskarna utsatte sina modeller för rigorösa tester mot ett brett spektrum etablerade system, inklusive klassiska konvolutionella neurala nätverk och nyare transformerbaserade konstruktioner. På bildendatasetet nådde PvT cirka 95 % total noggrannhet, och överträffade populära alternativ såsom NASNet och andra vision-transformers. På en mycket större och mer varierad samling av film- och TV-trailers som täcker elva genrer uppnådde MAiVAR-T omkring 98 % noggrannhet. Denna prestanda överträffade äldre multimodala konstruktioner som kombinerade ljud och bild mer löst, liksom starka endomodalitetsmodeller som endast tittade på ramar eller endast på ljud. Noggranna statistiska kontroller visade att dessa vinster inte berodde på slump, och tolkbarhetsverktyg som Grad-CAM och LIME bekräftade att modellerna fokuserar på rimliga ledtrådar såsom karaktärrörelse, ljussättning och förändringar i musikalisk intensitet.
Vad detta kan innebära för tittare och skapare
Högnoggrann genreigenkänning låter som en teknisk detalj, men den ligger till grund för många vardagliga upplevelser, från raderna med rekommendationer på din streamingstartsida till hur sändningsföretag söker i sina arkiv efter klipp och höjdpunkter. Genom att pålitligt koppla samman rika mönster av syn och ljud med mänskliga genrebegrepp kan system som PvT och MAiVAR-T hjälpa producenter att hantera enorma innehållsbibliotek, stödja smartare rekommendationsmotorer och till och med vägleda redigering och trailerdesign. Författarna noterar att mer diversifierade data och bättre hantering av program som blandar flera genrer kommer att vara viktiga nästa steg, liksom att hålla ett öga på etisk användning. Ändå visar deras resultat att transformers som både ser och hör är redo att bli kraftfulla assistenter för att organisera och förstå det ständigt växande universumet av digitala medier.
Citering: Alarfaj, F.K., Naz, A. Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media. Sci Rep 16, 14543 (2026). https://doi.org/10.1038/s41598-026-45087-y
Nyckelord: videogenreigenkänning, vision-transformers, multimodal AI, tv-analys, ljud- och bildanalys