Clear Sky Science · de
Untersuchung von Vision Transformers zur tiefen Merkmalsextraktion und Klassifikation bei der Genreserkennung von Videos für digitale Medien
Warum eine intelligentere TV-Kategorisierung wichtig ist
Streaming-Dienste und Fernsehsender verwalten heute ein Meer von Serien, Filmen und Clips in allen Stilrichtungen – von temporeicher Action bis hin zu ruhiger Romanze. Hinter den Kulissen muss jemand oder etwas bestimmen, zu welchem Inhaltstyp jedes Werk gehört, damit es gefunden, empfohlen und programmiert werden kann. Dieses Papier untersucht neue Werkzeuge der künstlichen Intelligenz, die automatisch das Genre von Fernseh- und Videoinhalten erkennen, indem sie sowohl das Bildgeschehen auf dem Bildschirm als auch den Ton der Tonspur analysieren. Das verspricht schnellere und genauere Möglichkeiten, die moderne Medienwelt zu organisieren. 
Von einfachen Bildhinweisen zu tiefgehendem Videoverständnis
Frühe Ansätze zur automatischen Genreserkennung stützten sich auf relativ grobe visuelle Hinweise: Gesamtfarbe, grundlegende Texturen oder einfache Bewegungsschätzungen. Diese Methoden hatten Schwierigkeiten mit dem heutigen komplexen Fernsehen, in dem Beleuchtung, Tempo und Stimmung sich von Moment zu Moment ändern. Die Autoren gehen dieses Problem zunächst mit einem neueren Bildmodell an, dem Pyramid Vision Transformer (PvT). Anstatt nur kleine Bildausschnitte zu betrachten, baut dieser Ansatz eine geschichtete Sicht auf, die sowohl feine Details als auch die großräumige Struktur einer Szene erfasst. Angewandt auf einen Datensatz von fast 4.500 Fernsehproduktion-Bildern aus vier Genres – Action, Animation, Romanze und Horror – lernt der PvT, welche Kombinationen aus Beleuchtung, Bildausschnitt und Komposition typischerweise auf jede Kategorie hindeuten.
Maschinen beibringen, genauso zuzuhören wie hinzuschauen
Fernsehgenres werden ebenso sehr durch Klang wie durch Bilder definiert: treibende Musik in einem Action-Trailer, spannungserzeugende Drones in einem Thriller, zarte Melodien in einer Romanze. Um dies zu erfassen, führen die Autoren ein multimodales Modell namens MAiVAR-T ein, das Video-Frames und Audio gemeinsam verarbeitet. Für jeden Trailer wählen sie Schlüsselframes aus, die wichtige visuelle Momente repräsentieren, und koppeln diese mit mehreren Ansichten der Tonspur: Rohwellenformen, Rhythmus und Lautstärkeverlauf über die Zeit sowie kompakte Zusammenfassungen von Tonhöhe und Harmonie. MAiVAR-T folgt zwei parallelen Pfaden – einem für Bilder, einem für Audio – bevor diese zusammengeführt werden. Eine spezialisierte Fusionsstufe lernt, das auf dem Bildschirm Geschehende mit dem in der Tonspur Erhörten in Einklang zu bringen, sodass zum Beispiel ein dunkler Korridor gepaart mit plötzlichen scharfen Geräuschen anders bewertet wird als ein ähnliches Bild, das von sanfter Musik untermalt wird. 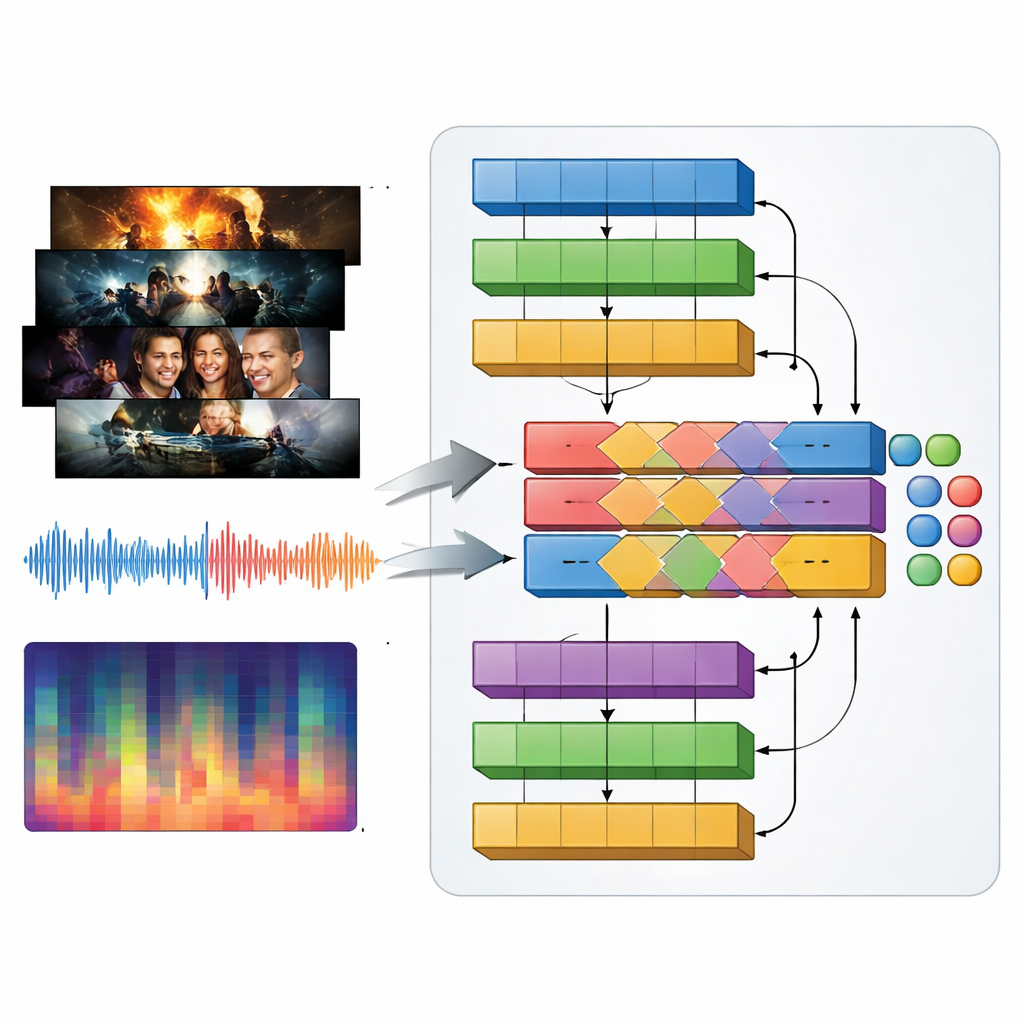
Wie gut der neue Ansatz abschneidet
Die Forscher unterzogen ihre Modelle strengen Tests gegen eine breite Palette etablierter Systeme, darunter klassische Convolutional Neural Networks und neuere transformerbasierte Designs. Auf dem reinen Bilddatensatz erreichte der PvT eine Gesamtgenauigkeit von etwa 95 % und übertraf damit beliebte Alternativen wie NASNet und andere Vision Transformers. Auf einer deutlich größeren und vielfältigeren Sammlung von Film- und TV-Trailern, die elf Genres abdeckte, erzielte MAiVAR-T rund 98 % Genauigkeit. Diese Leistung übertraf ältere multimodale Ansätze, die Ton und Bild weniger eng kombinierten, sowie starke Einzelformatsmodelle, die nur Frames oder nur Audio betrachteten. Sorgfältige statistische Prüfungen zeigten, dass diese Verbesserungen nicht zufällig waren, und Interpretierbarkeitswerkzeuge wie Grad-CAM und LIME bestätigten, dass die Modelle auf sinnvolle Hinweise wie Bewegungen der Charaktere, Beleuchtung und Veränderungen in der musikalischen Intensität achten.
Was das für Zuschauer und Produzenten bedeuten könnte
Hohe Genauigkeit bei der Genreserkennung mag wie ein technisches Detail wirken, bildet aber die Grundlage vieler alltäglicher Erfahrungen – von den Reihen an Empfehlungen auf Ihrer Startseite beim Streaming bis zur Art, wie Sender in ihren Archiven nach Clips und Highlights suchen. Indem sie reichhaltige Muster von Bild und Ton zuverlässig mit menschlichen Genrevorstellungen verbinden, könnten Systeme wie PvT und MAiVAR-T Produzenten helfen, riesige Inhaltebibliotheken zu verwalten, intelligentere Empfehlungssysteme zu unterstützen und sogar Schnitt- und Trailer-Design zu leiten. Die Autoren merken an, dass vielfältigere Daten und eine bessere Behandlung von Sendungen, die mehrere Genres mischen, wichtige nächste Schritte sein werden, ebenso wie die Beachtung ethischer Fragestellungen. Dennoch zeigen ihre Ergebnisse, dass Transformer, die sowohl sehen als auch hören, dazu bereit sind, leistungsfähige Assistenten bei der Organisation und dem Verständnis des ständig wachsenden Universums digitaler Medien zu werden.
Zitation: Alarfaj, F.K., Naz, A. Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media. Sci Rep 16, 14543 (2026). https://doi.org/10.1038/s41598-026-45087-y
Schlüsselwörter: Genreserkennung von Videos, Vision Transformers, multimodale KI, Fernseh-Analytics, audio-visuelle Analyse