Clear Sky Science · pl
Badanie vision transformerów do głębokiego wydobywania cech i klasyfikacji w rozpoznawaniu gatunków wideo dla mediów cyfrowych
Dlaczego mądrzejsze porządkowanie telewizji ma znaczenie
Serwisy streamingowe i kanały telewizyjne obsługują dziś ocean programów, filmów i klipów w stylach od dynamicznej akcji po kameralne romanse. Za kulisami ktoś — lub coś — musi zdecydować, czym jest każdy materiał, aby można go było znaleźć, polecać i zaplanować emisję. Niniejszy artykuł bada nowe narzędzia sztucznej inteligencji, które automatycznie rozpoznają gatunek treści telewizyjnych i wideo, analizując zarówno to, co widać na ekranie, jak i to, co słychać w ścieżce dźwiękowej, obiecując szybsze i dokładniejsze sposoby organizacji współczesnego świata mediów. 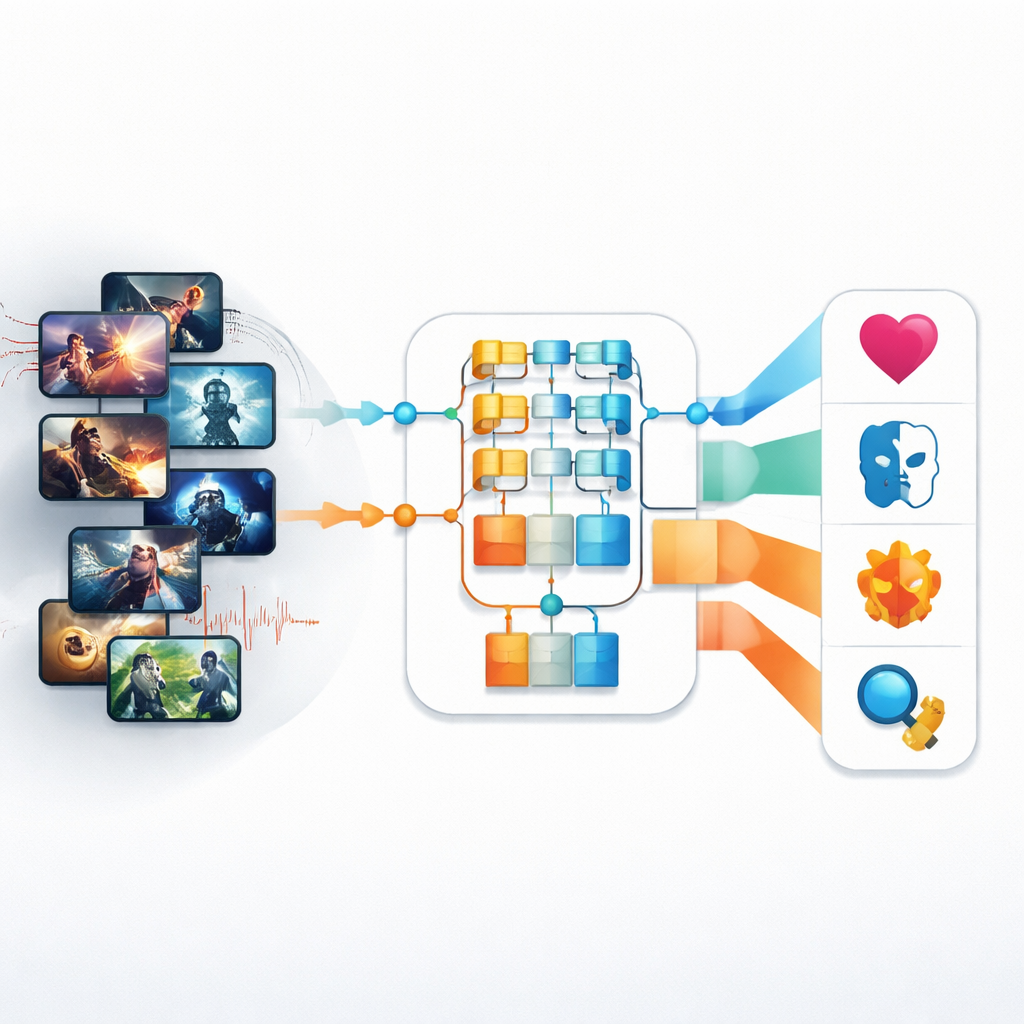
Od prostych wskazówek wizualnych do głębokiego rozumienia wideo
Pierwsze próby automatycznego rozpoznawania gatunków opierały się na dość prymitywnych wskazówkach wizualnych: ogólnej kolorystyce, podstawowych teksturach czy prostych oszacowaniach ruchu. Metody te miały problemy z dzisiejszą złożoną telewizją, w której oświetlenie, tempo i emocje zmieniają się z chwili na chwilę. Autorzy najpierw rozwiązują to wyzwanie, wykorzystując nowszy typ modelu obrazu zwanego Pyramid Vision Transformer (PvT). Zamiast skanować jedynie małe fragmenty obrazu, podejście to buduje wielowarstwowy obraz, który uchwyca zarówno drobne detale, jak i szerszą kompozycję sceny. Stosując je do zbioru danych prawie 4 500 zdjęć produkcji telewizyjnych obejmujących cztery gatunki — Akcja, Animacja, Romans i Horror — PvT uczy się, które kombinacje oświetlenia, kadrowania i kompozycji zazwyczaj sygnalizują daną kategorię.
Nauczanie maszyn słuchania tak samo jak patrzenia
Gatunki telewizyjne definiuje się nie mniej dźwiękiem niż obrazem: dudniąca muzyka w zwiastunie akcji, napięte drony w thrillerze, delikatne melodie w romansie. Aby to uchwycić, autorzy wprowadzają model multimodalny nazwany MAiVAR-T, który przetwarza jednocześnie klatki wideo i dźwięk. Dla każdego zwiastuna wybierają kluczowe klatki reprezentujące ważne momenty wizualne, a następnie łączą je z wieloma reprezentacjami ścieżki dźwiękowej: surowymi przebiegami falowymi, rytmem i głośnością w czasie oraz skondensowanymi podsumowaniami wysokości dźwięku i harmonii. MAiVAR-T prowadzi dwie równoległe ścieżki — jedną dla obrazów, drugą dla audio — zanim je połączy. Specjalistyczny etap fuzji uczy się dopasowywać to, co dzieje się na ekranie, z tym, co dzieje się w głośnikach, tak że na przykład ciemny korytarz połączony z nagłymi ostrymi dźwiękami jest traktowany inaczej niż podobny obraz wsparty delikatną muzyką. 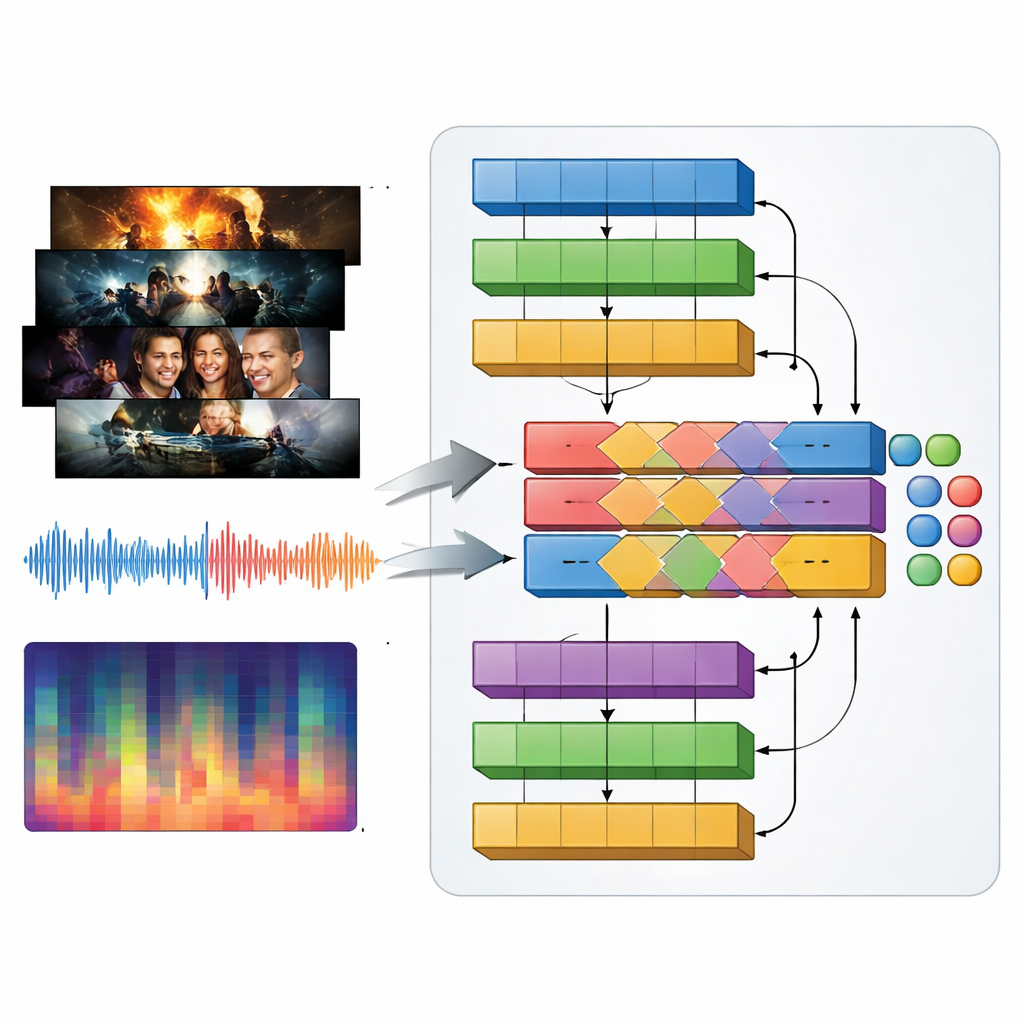
Jak dobrze działa nowe podejście
Naukowcy przetestowali swoje modele w rygorystycznych testach przeciwko szerokiej gamie ustalonych systemów, w tym klasycznym sieciom konwolucyjnym i nowszym projektom opartym na transformerach. Na zbiorze danych zawierającym tylko obrazy PvT osiągnął około 95% dokładności ogólnej, przewyższając popularne alternatywy, takie jak NASNet i inne vision transformery. Na znacznie większej i bardziej zróżnicowanej kolekcji zwiastunów filmowych i telewizyjnych obejmującej jedenaście gatunków MAiVAR-T osiągnął około 98% dokładności. Wynik ten przewyższał starsze projekty multimodalne, które łączyły dźwięk i obraz mniej ścisło, jak również silne modele jednomodalne analizujące tylko klatki lub tylko audio. Staranna weryfikacja statystyczna wykazała, że te zyski nie były dziełem przypadku, a narzędzia interpretowalności, takie jak Grad-CAM i LIME, potwierdziły, że modele skupiają się na sensownych wskazówkach, takich jak ruch postaci, oświetlenie i zmiany intensywności muzycznej.
Co to może oznaczać dla widzów i twórców
Wysokodokładne rozpoznawanie gatunków może brzmieć jak szczegół techniczny, ale leży u podstaw wielu codziennych doświadczeń, od szeregu rekomendacji na ekranie startowym serwisu streamingowego po sposób, w jaki nadawcy przeszukują archiwa w poszukiwaniu klipów i skrótów. Poprzez wiarygodne łączenie bogatych wzorców obrazu i dźwięku z ludzkimi kategoriami gatunkowymi, systemy takie jak PvT i MAiVAR-T mogą pomóc producentom zarządzać rozległymi bibliotekami treści, wspierać inteligentniejsze silniki rekomendacyjne, a nawet wspomagać montaż i projektowanie zwiastunów. Autorzy zauważają, że ważne będą dalsze kroki — bardziej zróżnicowane dane i lepsze radzenie sobie z programami łączącymi wiele gatunków — a także dbałość o etyczne wykorzystanie. Mimo to ich wyniki pokazują, że transformatory, które zarówno widzą, jak i słyszą, są gotowe, by stać się potężnymi asystentami w organizowaniu i zrozumieniu coraz większego uniwersum mediów cyfrowych.
Cytowanie: Alarfaj, F.K., Naz, A. Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media. Sci Rep 16, 14543 (2026). https://doi.org/10.1038/s41598-026-45087-y
Słowa kluczowe: rozpoznawanie gatunku wideo, vision transformery, sztuczna inteligencja multimodalna, analiza telewizyjna, analiza audio-wizualna