Clear Sky Science · ja
デジタルメディアの映像ジャンル認識における深層特徴抽出と分類のためのビジョン・トランスフォーマーの探究
より賢いテレビ分類が重要な理由
ストリーミングサービスやテレビ局は今や、速いテンポのアクションから静かなロマンスまで、あらゆるスタイルの番組や映画、クリップの海を扱っています。舞台裏では、各コンテンツが何であるかを決めて検索、推薦、編成できるようにする必要があります。本論文は、画面に映るものとサウンドトラックで聞こえるものの両方を解析することで、テレビや映像コンテンツのジャンルを自動認識できる新しい人工知能ツールを検討します。これにより、現代のメディアをより速く、より正確に整理する手段が期待されます。 
単純な画面手がかりから豊かな映像理解へ
自動ジャンル認識の初期の試みは、全体の色合い、基本的なテクスチャ、単純な動きの推定など、かなり粗い視覚手がかりに頼っていました。これらの手法は、照明、テンポ、感情が瞬間ごとに変化する今日の複雑なテレビ番組には苦戦しました。著者らはまず、Pyramid Vision Transformer(PvT)と呼ばれる新しい種類の画像モデルを用いてこの課題に取り組みます。この手法は画像の小さなパッチだけを走査するのではなく、シーンの細部と広い構図の両方を捉える層状の視点を構築します。Action、Animation、Romance、Horror の4ジャンルに跨る約4,500枚のテレビ制作画像データセットに適用すると、PvT は照明、フレーミング、構図のどの組み合わせが各カテゴリを示す傾向にあるかを学習します。
見るだけでなく聴くことを教える
テレビのジャンルは視覚と同じくらい音によって定義されます。アクション予告の強烈な音楽、スリラーの緊張感あるドローン音、ロマンスのやさしい旋律などです。これを捉えるために、著者らは映像フレームと音声を一緒に処理するマルチモーダルモデル、MAiVAR-T を導入します。各トレーラーについて、重要な視覚的瞬間を表すキーフレームを選び、それらを音声の複数の表現と組み合わせます:生波形、時間に沿ったリズムと音量、ピッチと和音の凝縮された要約などです。MAiVAR-T は画像用と音声用の二つの並列経路を持ち、それらを統合します。専用の融合段階が画面上で起きていることとスピーカーから聞こえることを整合させることを学習するため、例えば暗い廊下の映像に鋭い不協和音が重なる場合と、似た映像にやさしい音楽が付く場合は異なる扱いをされます。 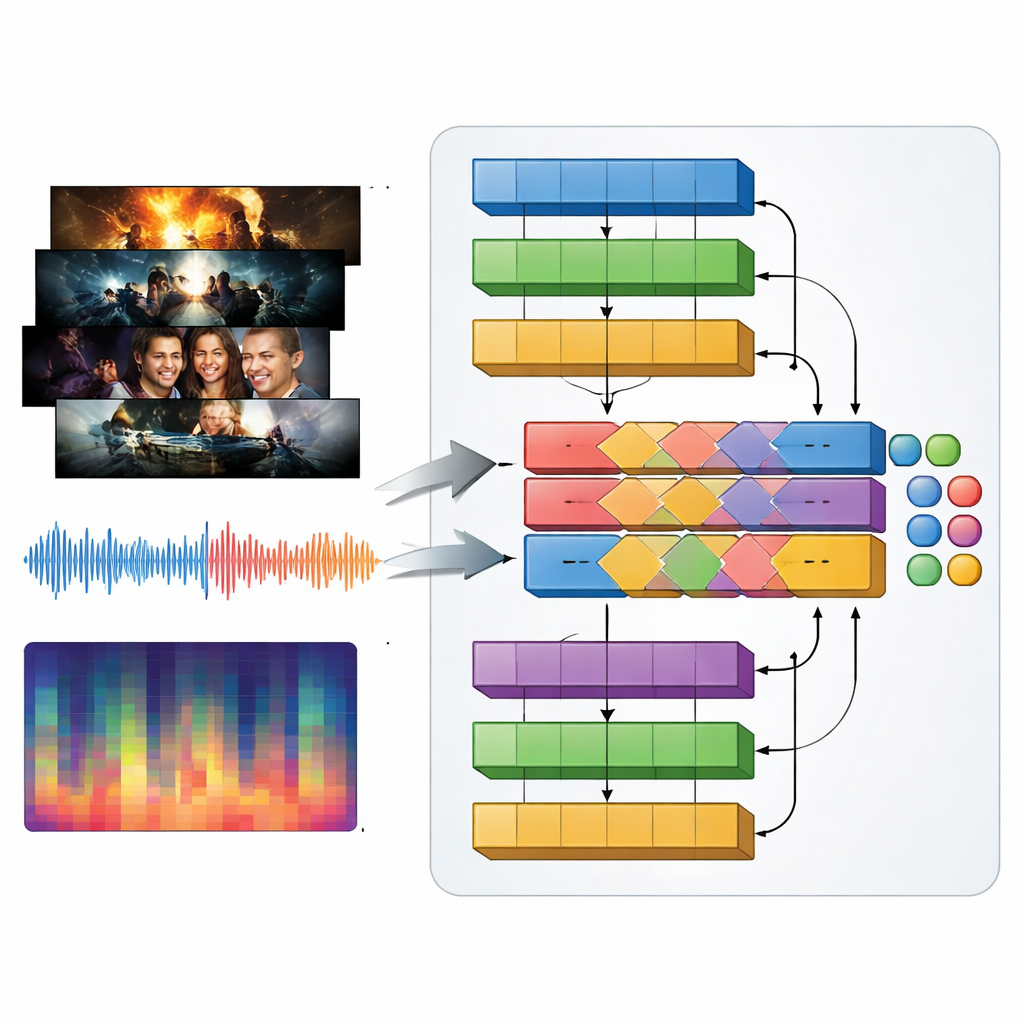
新手法の性能はどれほどか
研究者らは、自らのモデルを古典的な畳み込みニューラルネットワークや近年のトランスフォーマーベースの設計を含む幅広い既存システムと厳密に比較しました。画像のみのデータセットでは、PvT は約95%の総合精度に達し、NASNet や他のビジョン・トランスフォーマーといった一般的な代替手法を上回りました。より大規模で多様な11ジャンルを含む映画・テレビ予告編のコレクションでは、MAiVAR-T は約98%の精度を達成しました。この性能は、音と映像をより緩やかに結合した古いマルチモーダル設計や、フレームのみ、あるいは音声のみを扱う強力な単一モダリティモデルを凌駕しました。注意深い統計的検証により、これらの向上が偶然によるものではないことが示され、Grad-CAM や LIME といった解釈可能性ツールはモデルが登場人物の動き、照明、音楽の強弱変化など妥当な手がかりに着目していることを確認しました。
視聴者と制作者にとっての意味
高精度のジャンル認識は技術的な詳細に思えるかもしれませんが、ストリーミングのホーム画面に並ぶ推薦の列から放送局がアーカイブを検索してクリップやハイライトを見つける方法に至るまで、多くの日常的な体験を支えています。PvT や MAiVAR-T のように、視覚と音声の豊かなパターンを人間のジャンル概念に確実に結びつけるシステムは、プロデューサーが膨大なコンテンツライブラリを管理するのを助け、より賢い推薦エンジンを支え、編集やトレーラー作成の指針にもなり得ます。著者らは、より多様なデータと複数ジャンルを融合する番組への対応改善が今後の重要な課題であり、倫理的な利用にも注意を払う必要があると指摘しています。それでも、見ることと聞くことの両方を行うトランスフォーマーは、増え続けるデジタルメディアの宇宙を整理し理解する強力な支援者になりつつあることを示しています。
引用: Alarfaj, F.K., Naz, A. Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media. Sci Rep 16, 14543 (2026). https://doi.org/10.1038/s41598-026-45087-y
キーワード: 映像ジャンル認識, ビジョン・トランスフォーマー, マルチモーダルAI, テレビ解析, 音声・映像解析