Clear Sky Science · ru
Исследование визуальных трансформеров для извлечения глубоких признаков и классификации в задаче распознавания жанров видео для цифровых медиа
Почему умная сортировка ТВ важна
Сервисы потокового видео и телеканалы сейчас обрабатывают океан сериалов, фильмов и клипов во всевозможных стилях — от динамичного экшена до тихой романтики. За кулисами кто‑то — или что‑то — должен определить, к какому жанру относится каждый кусок контента, чтобы его можно было найти, порекомендовать и расписать показ. В этой работе исследуются новые инструменты искусственного интеллекта, которые автоматически распознают жанр теле‑ и видеоматериалов, учитывая как то, что вы видите на экране, так и то, что слышите в звуковой дорожке, обещая более быстрые и точные способы организации современного медиапространства. 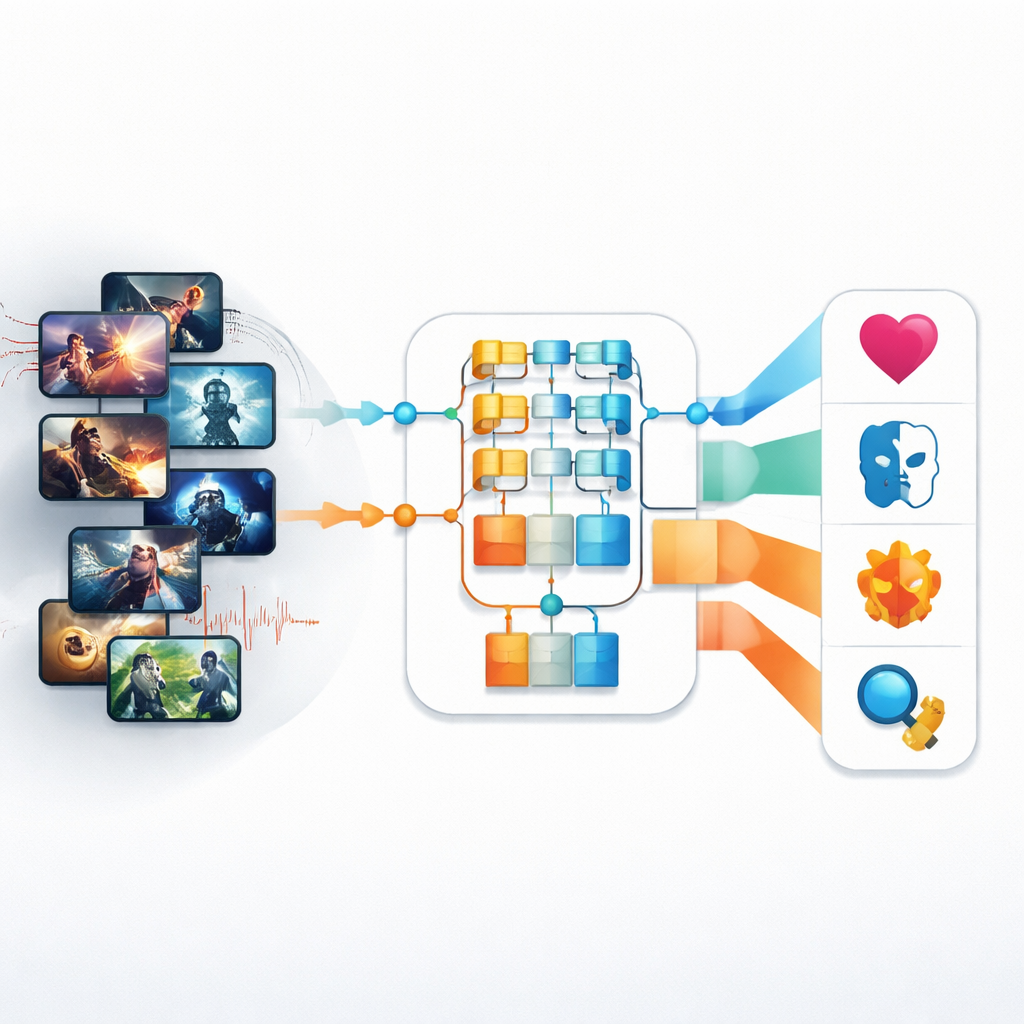
От простых визуальных подсказок к глубокому пониманию видео
Ранние попытки автоматического распознавания жанров опирались на довольно грубые визуальные признаки: общая цветовая палитра, базовые текстуры или простая оценка движения. Эти подходы испытывали трудности с современной сложной телевизионной картиной, где освещение, темп и эмоции меняются от кадра к кадру. Авторы сначала решают эту задачу с помощью более новой модели изображений — Pyramid Vision Transformer (PvT). Вместо того чтобы анализировать только небольшие патчи изображения, этот подход строит многоуровневое представление, которое улавливает как тонкие детали, так и общую композицию сцены. Применённый к датасету почти из 4500 кадров телевизионного производства, охватывающему четыре жанра — «Экшн», «Анимация», «Романтика» и «Ужасы» — PvT обучается распознавать комбинации освещения, кадрирования и композиции, которые обычно сигнализируют о каждом из жанров.
Учим машины слушать так же, как смотреть
Телевизионные жанры определяются не только визуально, но и звукорежиссёрскими приёмами: бьющая музыка в трейлере экшена, напряжённые дроны в триллере, нежные мелодии в романтике. Чтобы захватить эти аспекты, авторы предлагают мультимодальную модель MAiVAR-T, которая обрабатывает кадры видео и аудио совместно. Для каждого трейлера выбираются ключевые кадры, представляющие важные визуальные моменты, затем они сопоставляются с несколькими представлениями звуковой дорожки: сырые волновые формы, ритм и громкость во времени, а также компактные сводки по высоте тона и гармонии. MAiVAR-T следует по двум параллельным путям — для изображений и для аудио — а затем объединяет их. Специальная стадия слияния учится выравнивать происходящее на экране с тем, что слышно в динамиках, так что, например, тёмный коридор в паре с внезапными резкими звуками обрабатывается иначе, чем похожий кадр с мягкой фоново́й музыкой. 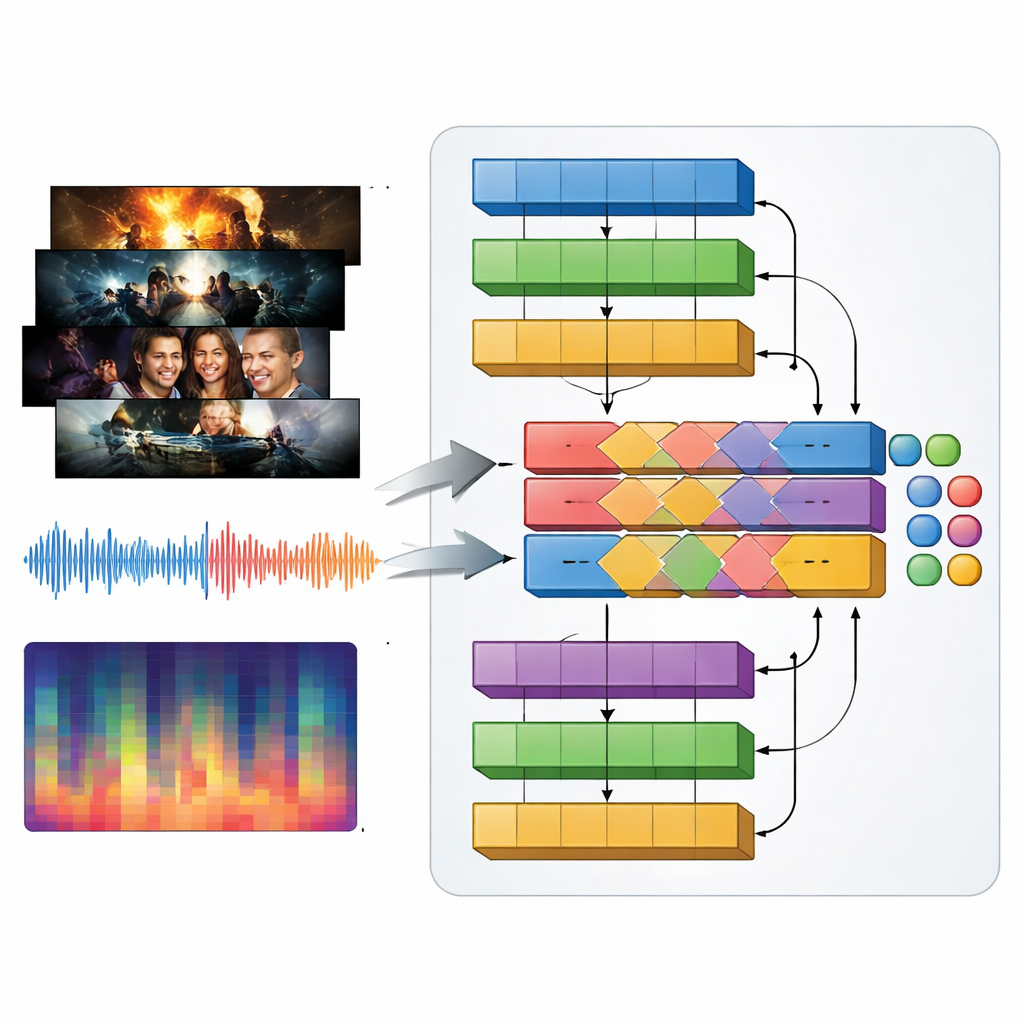
Насколько хорошо работает новый подход
Исследователи подвергли свои модели строгой проверке в сравнении с широким кругом устоявшихся систем, включая классические сверточные нейросети и более новые трансформерные архитектуры. На наборе данных только с изображениями PvT достиг примерно 95% общей точности, превосходя популярные альтернативы, такие как NASNet и другие визуальные трансформеры. На гораздо большей и более разнообразной коллекции кино- и телевизионных трейлеров, охватывающей одиннадцать жанров, MAiVAR-T продемонстрировала около 98% точности. Такое качество превзошло старые мультимодальные подходы, которые связывали звук и изображение менее плотно, а также сильные модели одиночной модальности, работающие только с кадрами или только с аудио. Тщательные статистические проверки показали, что эти преимущества не являются случайными, а интерпретируемые инструменты, такие как Grad-CAM и LIME, подтвердили, что модели фокусируются на осмысленных признаках — движении персонажей, освещении и изменениях музыкальной интенсивности.
Что это может означать для зрителей и создателей
Высокоточное распознавание жанров может звучать как техническая деталь, но оно лежит в основе многих повседневных опытов — от рядов рекомендаций на главной странице вашего стриминга до способов, которыми телерадиокомпании ищут по архивам клипы и подборки. Надёжно связывая богатые паттерны зрения и звука с человеческими представлениями о жанре, системы вроде PvT и MAiVAR-T могут помочь продюсерам управлять огромными библиотеками контента, поддерживать более интеллектуальные рекомендательные движки и даже помогать в монтаже и создании трейлеров. Авторы отмечают, что важными следующими шагами станут пополнение данных большей разноплановостью и лучшее обращение с шоу, смешивающими сразу несколько жанров, а также внимательное отношение к этическому использованию. Тем не менее их результаты показывают, что трансформеры, которые и видят, и слышат, готовы стать мощными помощниками в организации и понимании постоянно растущей вселенной цифровых медиа.
Цитирование: Alarfaj, F.K., Naz, A. Exploring vision transformers for deep feature extraction and classification in video genre recognition for digital media. Sci Rep 16, 14543 (2026). https://doi.org/10.1038/s41598-026-45087-y
Ключевые слова: распознавание жанров видео, визуальные трансформеры, мультимодальный ИИ, телевизионная аналитика, аудиовизуальный анализ