Clear Sky Science · zh
结构性错误不对称性与基于危害权重的分析:ChatGPT 与重症监护科医生在酸碱解释上的比较——一项前瞻性观察研究
这项研究对普通读者的重要性
医院越来越多地尝试用人工智能辅助医生决策,尤其是在拥挤的重症监护病房。本研究提出了一个简单但关键的问题:当像 ChatGPT 这样的计算机程序用来解释指导救命治疗的敏感血液检测时,它所犯的错误是否与有经验的 ICU 医生所犯的错误一样安全,还是可能悄然掩盖严重问题?
研究核心的血液检测
研究聚焦动脉血气(ABG)检测,这种检测测量血液的酸碱度以及患者的通气和氧合情况。在 ICU 中,这些结果帮助医生决定是否调整呼吸机、输液或更改药物。结果模式可以很简单,比如单一的呼吸或代谢问题;也可以很复杂,即同时存在多种问题。这类“混合”模式在危重症患者中常见,常提示机体在多个方面同时受挫。
对比试验是如何进行的
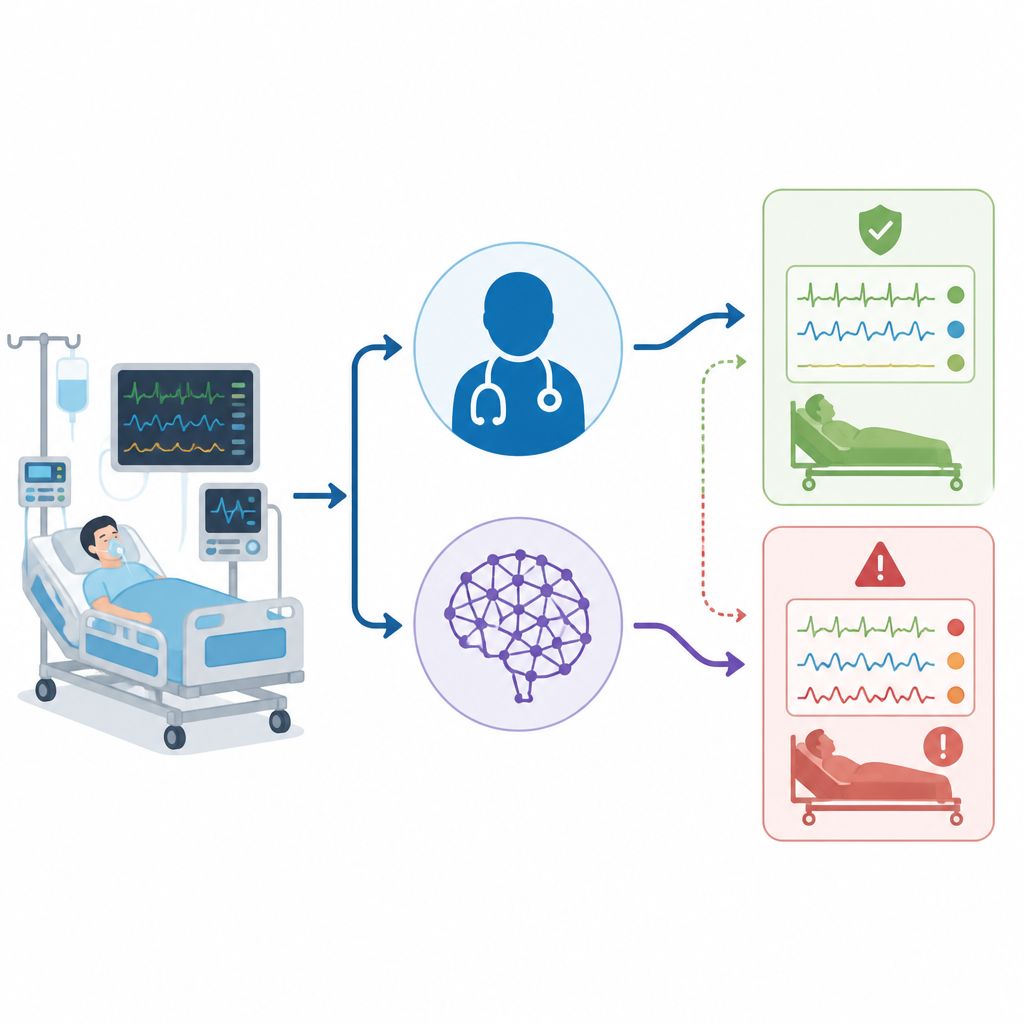
研究团队在单一医院从 50 名真实成年 ICU 患者处收集数据,仅使用每人首个符合条件的血气检查结果。对每名患者,编写了包含血气数值和其他关键细节(例如生命体征、器官功能与呼吸支持)的简短临床情况描述。随后三方独立解释每个病例:床旁的 ICU 医生、使用固定英文提示的 ChatGPT,以及作为最终“金标准”诊断的独立专家小组。所有解释后来被归入六个简单类别,包括正常、四类基本紊乱类型和一种表示存在多重问题的混合类别。
不仅仅看对错
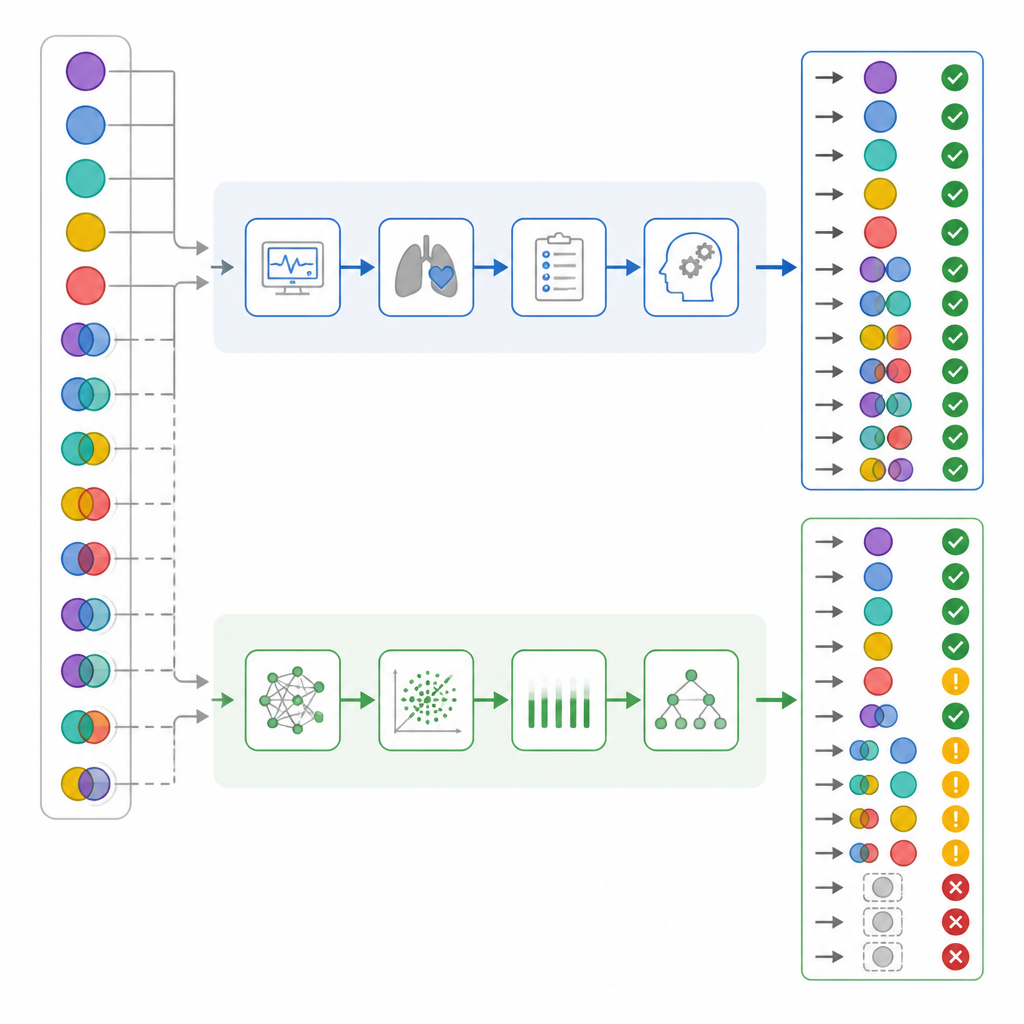
当研究者仅看总体正确率时,数字看起来相当接近:ICU 医生正确率为 82%,而 ChatGPT 为 72%。标准的一致性统计显示两者均处于“较高”范围。但团队进一步深入分析各方错误的性质,而非仅看错误频率。他们把简单病例与混合病例分开,检查每位解释者对呼吸性与代谢性成分的识别能力,并构建了一个“危害评分”,将某些错误计为比其他错误更危险。在该评分系统中,将真正复杂的病例判断为“正常”被赋予最高权重,因为这可能使医务人员产生虚假的安全感。
在复杂且高风险病例中的隐藏差异
一旦按复杂性分解结果,重要差异便显现出来。近一半的患者实际上存在混合酸碱紊乱。ICU 医生几乎在所有此类病例中都能正确识别,而 ChatGPT 漏判了超过三分之一。在约六分之一的混合病例中,ChatGPT 甚至将血气状态误判为正常——作者称之为“虚假安慰”,而医生则从未出现这种情况。对呼吸与代谢成分分别分析表明,ChatGPT 更可能忽视呼吸性成分。当应用危害评分体系后,ChatGPT 的错误平均带来的危害显著高于 ICU 医生,尽管两者的总体准确率有重叠。
这对在危重病场景中使用人工智能意味着什么
对普通读者而言,主要信息是:相近的总体准确率并不意味着 AI 工具在关键情境中的行为与医生相同。在这个真实世界的 ICU 样本中,ChatGPT 往往能够正确分类常见模式,但在那些提示严重疾病并需迅速处理的复杂混合问题上表现较差。因为工作人员无法事先总是判断哪些病例是简单还是复杂,而现有的 AI 工具也不能可靠地在不确定时发出警示,作者认为 ChatGPT 不应取代医生对这些血气判断的最终判断。相反,他们建议未来对医学 AI 的评估应更少关注总体得分,更多关注系统错过危险情况的频率、处理复杂性的能力以及其错误对患者可能造成的危害。
引用: Gulen, D., Gözden, H.E., Ekin, S. et al. Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study. Sci Rep 16, 15184 (2026). https://doi.org/10.1038/s41598-026-44576-4
关键词: 重症监护, 血气解释, 临床人工智能, 诊断安全, 医学中的 ChatGPT