Clear Sky Science · pl
Asymetria błędów strukturalnych i analiza ważona szkodą ChatGPT kontra lekarze z OIOM w interpretacji gospodarki kwasowo‑zasadowej: prospektywne badanie obserwacyjne
Dlaczego to badanie ma znaczenie dla czytelników
Szpitale coraz częściej eksperymentują ze sztuczną inteligencją, aby wspierać lekarzy w podejmowaniu decyzji, zwłaszcza na zatłoczonych oddziałach intensywnej terapii. To badanie stawia proste, lecz kluczowe pytanie: gdy program komputerowy taki jak ChatGPT pomaga interpretować bardzo wrażliwe badanie krwi, które kieruje leczeniem ratującym życie, czy jego błędy są równie nieszkodliwe jak błędy doświadczonych lekarzy OIOM, czy też mogą ukrywać poważne zagrożenie?
Badanie krwi będące w centrum opowieści
Badania koncentrują się na tętniczych gazometrach krwi, które mierzą, jak kwaśna jest krew oraz jak dobrze pacjent oddycha i otrzymuje tlen. Na oddziale intensywnej terapii wyniki te pomagają lekarzom zdecydować, czy zmienić ustawienia respiratora, podać płyny czy zmodyfikować leki. Wzorce mogą być proste — na przykład jeden dominujący problem oddechowy lub metaboliczny — albo złożone, gdy jednocześnie występuje kilka zaburzeń. Takie „mieszane” wzorce są częste u ciężko chorych pacjentów i mogą sygnalizować, że organizm boryka się na kilku frontach naraz.
Jak przeprowadzono bezpośrednie porównanie
Zespół zebrał dane od 50 dorosłych pacjentów OIOM w jednym szpitalu, wykorzystując jedynie pierwsze kwalifikujące się badanie gazometrii od każdej osoby. Dla każdego pacjenta przygotowano krótką historię kliniczną zawierającą wyniki gazometrii i inne kluczowe informacje, takie jak parametry życiowe, funkcja narządów i wsparcie oddechowe. Każdą sprawę niezależnie interpretowały trzy grupy: lekarze przy łóżku pacjenta, ChatGPT używający ustalonego angielskiego promptu oraz oddzielny panel ekspertów, który ustalał ostateczną „złotą” diagnozę. Wszystkie interpretacje sklasyfikowano później do sześciu prostych kategorii, w tym stanu prawidłowego, czterech podstawowych typów zaburzeń oraz kategorii mieszanej, gdy występowało więcej niż jedno zaburzenie.
Patrząc poza proste „dobrze” lub „źle”
Gdy badacze spojrzeli jedynie na ogólną poprawność, liczby wydawały się dość zbliżone: lekarze OIOM mieli 82 procent poprawnych rozpoznań, podczas gdy ChatGPT — 72 procent. Standardowe statystyki zgodności sugerowały, że obie strony osiągały wyniki w zakresie „znaczącym”. Zespół jednak zagłębił się dalej w to, jak każda ze stron się myliła, a nie tylko jak często. Rozdzielili przypadki proste od mieszanych, sprawdzili, jak dobrze każdy interpreter wyłapywał komponenty oddechowe versus metaboliczne, i stworzyli „scenariusz szkodliwości”, w którym pewne błędy oceniano jako bardziej niebezpieczne niż inne. W tym systemie zaklasyfikowanie naprawdę złożonego przypadku jako „prawidłowego” miało największą wagę, ponieważ mogłoby uśpić czujność personelu.
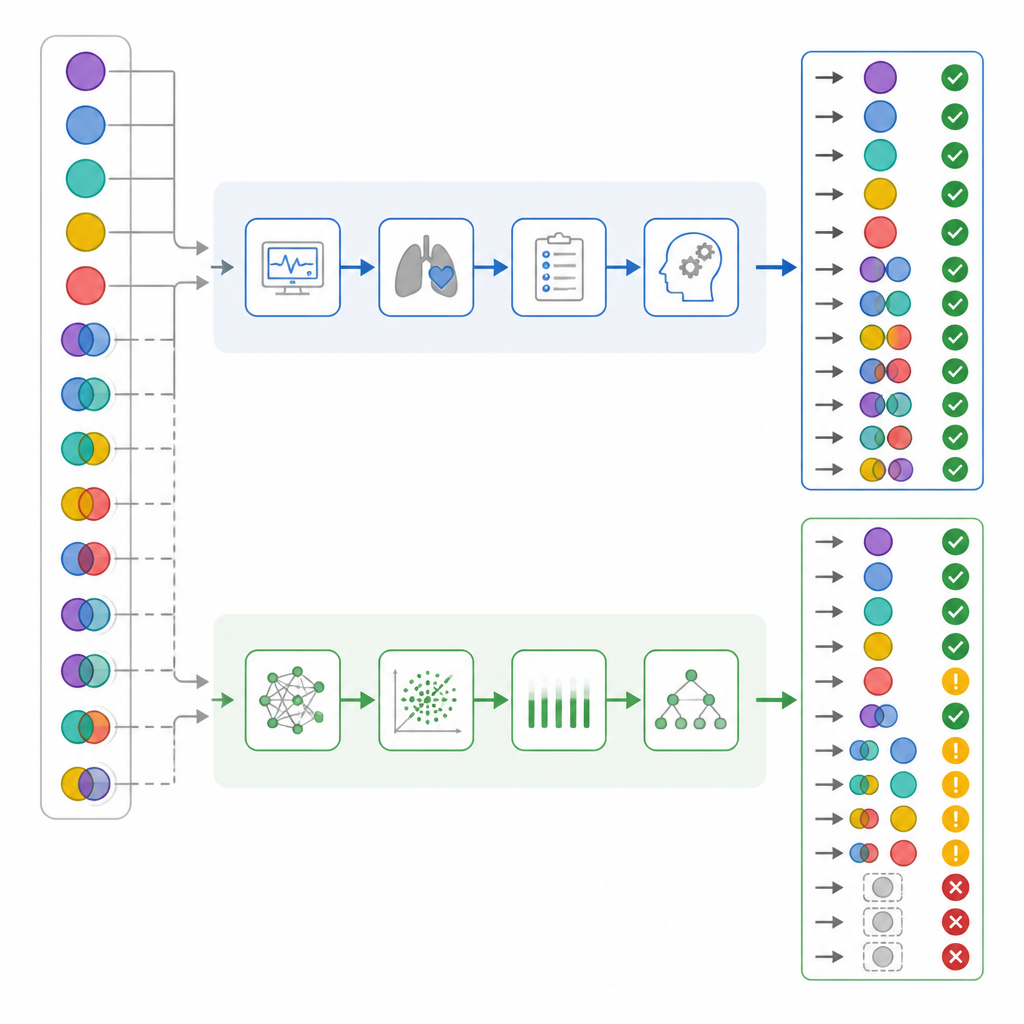
Ukryte różnice w złożonych i ryzykownych przypadkach
Po rozbiciu wyników według stopnia złożoności ujawniły się istotne kontrasty. Niemal połowa pacjentów miała rzeczywiście mieszane zaburzenia kwasowo‑zasadowe. Lekarze OIOM prawidłowo rozpoznali je niemal we wszystkich przypadkach, natomiast ChatGPT pominął ponad jedną trzecią z nich. W około jednej szóstej przypadków mieszanych ChatGPT nawet zaklasyfikował stan krwi jako prawidłowy — wzorzec, który autorzy nazwali „fałszywym uspokojeniem”, czego lekarze nigdy nie wykazali. Bliższa analiza oddzielnych składników oddechowych i metabolicznych sugerowała, że ChatGPT częściej przeoczał składową oddechową zaburzenia. Po zastosowaniu systemu punktacji szkodliwości błędy ChatGPT niosły ze sobą znacząco wyższą średnią szkodliwość niż błędy lekarzy OIOM, mimo że ich ogólna trafność nakładała się.
Co to znaczy dla użycia SI w opiece krytycznej
Dla czytelnika niebędącego specjalistą główne przesłanie jest takie: podobna ogólna trafność nie oznacza, że narzędzie SI zachowuje się jak lekarz tam, gdzie to naprawdę ma znaczenie. W tej rzeczywistej próbie OIOM ChatGPT często potrafił poprawnie sklasyfikować powszechne wzorce, ale miał większe trudności ze splecionymi, mieszanymi problemami, które wskazują na ciężką chorobę i wymagają szybkiej reakcji. Ponieważ personel nie zawsze może wcześniej odróżnić przypadki proste od złożonych, a obecne narzędzia SI nie ostrzegają niezawodnie, gdy są niepewne, autorzy argumentują, że ChatGPT nie powinien zastępować oceny lekarza przy decyzjach dotyczących gazometrii. Zamiast tego proponują, by przyszłe testy medycznej SI koncentrowały się mniej na ogólnych wynikach, a bardziej na tym, jak często system przeocza niebezpieczne sytuacje, jak radzi sobie z złożonością i jak szkodliwe mogą być jego błędy dla pacjentów.
Cytowanie: Gulen, D., Gözden, H.E., Ekin, S. et al. Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study. Sci Rep 16, 15184 (2026). https://doi.org/10.1038/s41598-026-44576-4
Słowa kluczowe: intensywna terapia, interpretacja gazometrii, kliniczna sztuczna inteligencja, bezpieczeństwo diagnostyczne, ChatGPT w medycynie