Clear Sky Science · fr
Asymétrie des erreurs structurelles et analyse pondérée par le préjudice de ChatGPT versus médecins ICU dans l’interprétation acido‑basique : une étude observationnelle prospective
Pourquoi cette étude importe pour les lecteurs non spécialistes
Les hôpitaux expérimentent de plus en plus l’intelligence artificielle pour aider les médecins à prendre des décisions, notamment dans les unités de soins intensifs surchargées. Cette étude pose une question simple mais cruciale : lorsqu’un programme informatique comme ChatGPT aide à interpréter un test sanguin très délicat qui oriente des traitements salvateurs, ses erreurs sont‑elles aussi sûres que celles de médecins d’unité de soins intensifs expérimentés, ou peuvent‑elles dissimuler silencieusement des problèmes sérieux ?
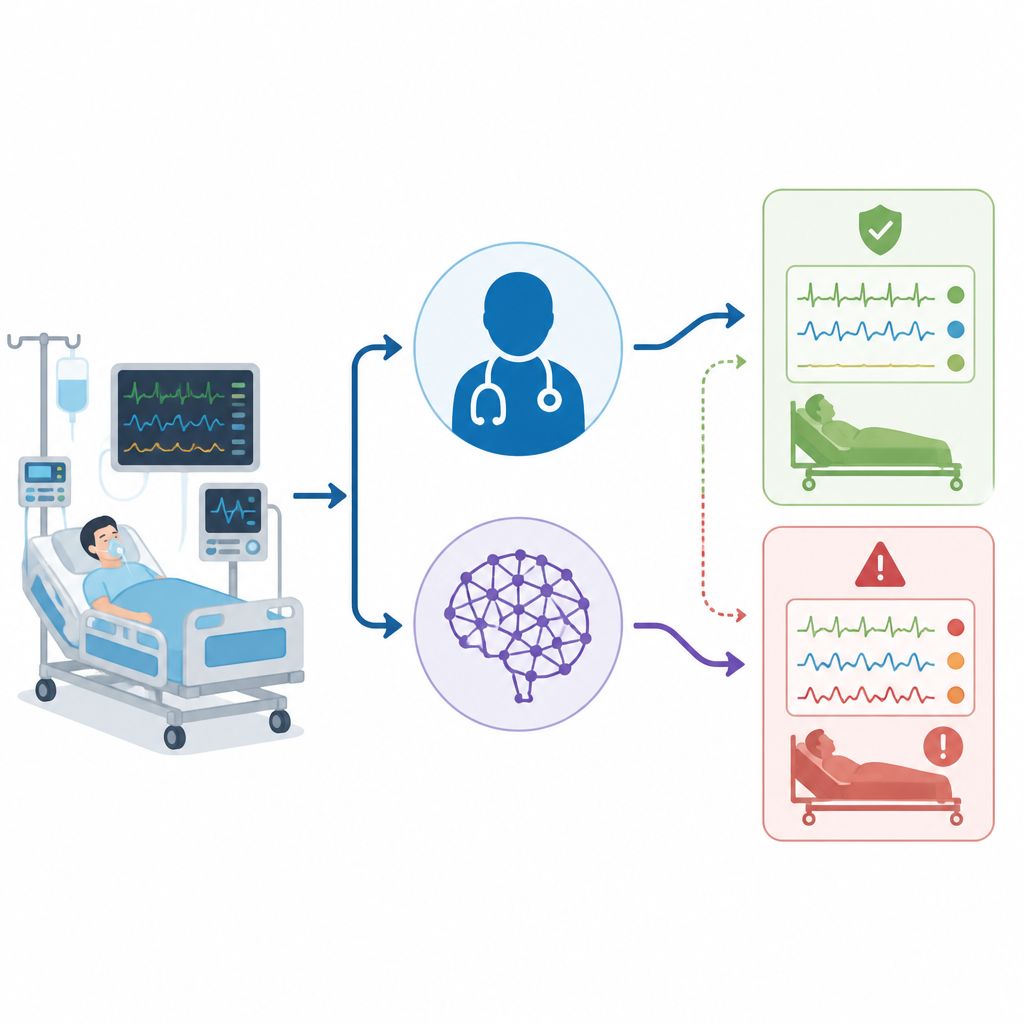
L’analyse sanguine au cœur de l’histoire
La recherche porte sur les gaz du sang artériel, qui mesurent l’acidité du sang et la qualité de la respiration et de l’oxygénation du patient. En réanimation, ces résultats aident les médecins à décider s’il faut ajuster un ventilateur, administrer des liquides ou modifier des médicaments. Les tableaux peuvent être simples, correspondant à un problème principal respiratoire ou métabolique, ou complexes, avec plusieurs anomalies simultanées. Ces profils « mixtes » sont fréquents chez les patients très gravement malades et peuvent indiquer que l’organisme lutte sur plusieurs fronts à la fois.
Comment la comparaison directe a été réalisée
L’équipe a recueilli des données de 50 patients adultes réels d’une seule unité hospitalière, en n’utilisant que le premier gaz du sang répondant aux critères pour chaque personne. Pour chaque patient, ils ont rédigé un bref récit clinique incluant les valeurs des gaz du sang et d’autres éléments clés tels que les constantes, la fonction des organes et le support ventilatoire. Trois groupes ont alors interprété chaque cas indépendamment : les médecins au chevet en réanimation, ChatGPT avec une invite en anglais fixe, et un panel d’experts distinct qui a fourni le diagnostic final dit « de référence ». Toutes les interprétations ont ensuite été classées en six catégories simples, incluant l’état normal, quatre types de perturbations de base et une catégorie mixte quand plusieurs anomalies étaient présentes.
Aller au‑delà du simple juste ou faux
Lorsque les chercheurs n’ont considéré que la justesse globale, les chiffres paraissaient assez proches : les médecins de réanimation étaient corrects dans 82 % des cas, tandis que ChatGPT l’était dans 72 % des cas. Les statistiques d’accord standard suggéraient que les deux performances se situaient dans une fourchette « substantielle ». Mais l’équipe a creusé davantage la nature des erreurs, pas seulement leur fréquence. Ils ont séparé les cas simples des cas mixtes, vérifié la capacité de chaque interprète à détecter les composantes respiratoires versus métaboliques, et créé un « score de préjudice » qui pondérait certaines erreurs comme plus dangereuses que d’autres. Dans ce système, qualifier à tort un cas réellement complexe de « normal » recevait le poids le plus élevé, car cela pouvait endormir la vigilance du personnel.
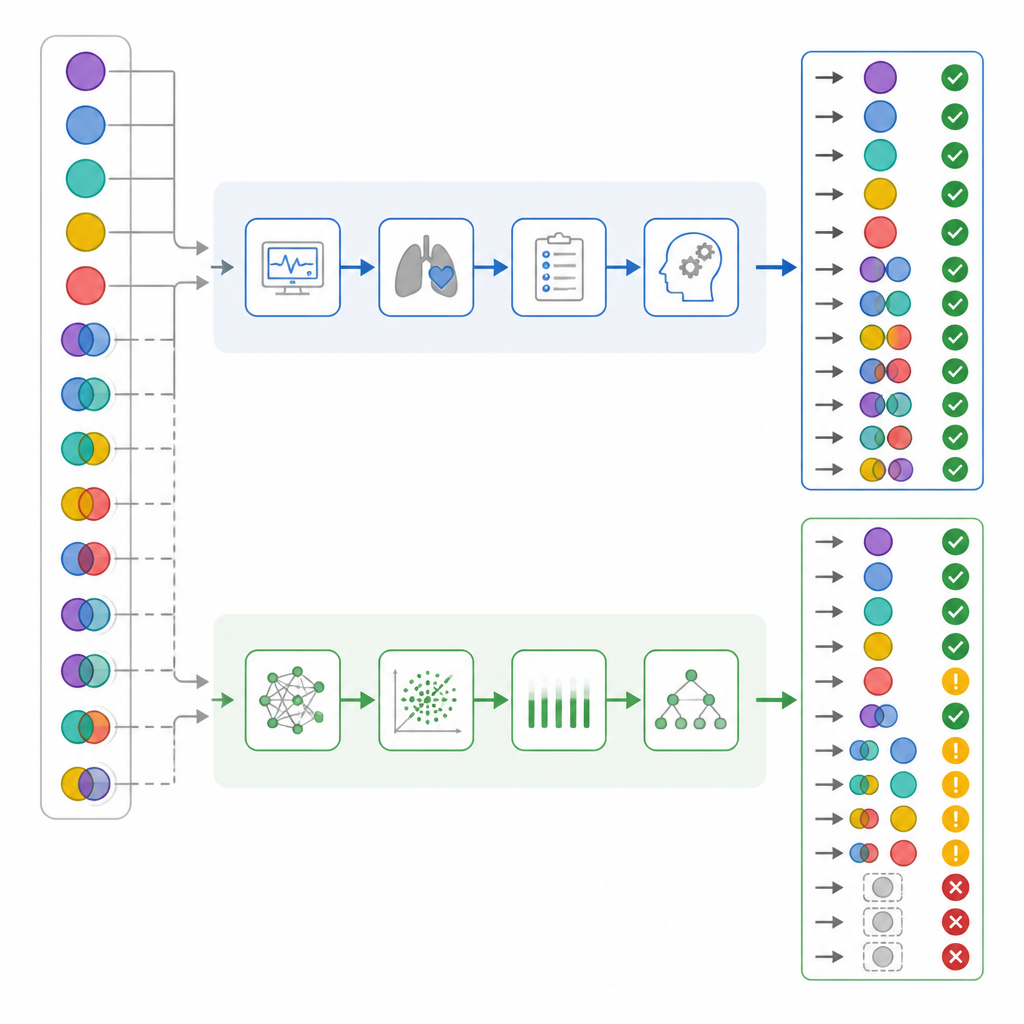
Différences cachées dans les cas complexes et à risque
Une fois les résultats ventilés par complexité, des contrastes importants sont apparus. Près de la moitié des patients présentaient en réalité des troubles acido‑basiques mixtes. Les médecins de réanimation les ont correctement reconnus dans presque tous les cas, tandis que ChatGPT en a manqué plus d’un tiers. Dans environ un cas sur six des situations mixtes, ChatGPT a même qualifié le statut sanguin de normal, un phénomène que les auteurs ont appelé « fausse assurance », qui n’est jamais survenu chez les médecins. Un examen plus fin des composantes respiratoires et métaboliques a suggéré que ChatGPT avait tendance à négliger davantage la composante respiratoire du trouble. Lorsque le système de score de préjudice a été appliqué, les erreurs de ChatGPT présentaient en moyenne un préjudice significativement plus élevé que celles des médecins en réanimation, malgré des taux de précision globale qui se chevauchaient.
Ce que cela signifie pour l’usage de l’IA en soins critiques
Pour un lecteur profane, le message principal est que des taux de précision similaires en surface ne signifient pas que l’outil d’IA se comporte comme un médecin là où cela compte le plus. Dans cet échantillon réel de réanimation, ChatGPT a souvent bien classé les profils courants, mais il a eu plus de difficultés avec les problèmes mêlés et embrouillés qui signalent une maladie grave et nécessitent une action rapide. Parce que le personnel ne peut pas toujours savoir à l’avance quels cas seront simples ou complexes, et que les outils d’IA actuels n’alertent pas de manière fiable lorsqu’ils sont incertains, les auteurs soutiennent que ChatGPT ne devrait pas remplacer le jugement médical pour ces décisions sur les gaz du sang. Ils proposent plutôt que les futurs tests de l’IA médicale se concentrent moins sur les scores globaux et davantage sur la fréquence des omissions de situations dangereuses, la gestion de la complexité et le degré de préjudice que peuvent entraîner les erreurs pour les patients.
Citation: Gulen, D., Gözden, H.E., Ekin, S. et al. Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study. Sci Rep 16, 15184 (2026). https://doi.org/10.1038/s41598-026-44576-4
Mots-clés: soins intensifs, interprétation des gaz du sang, intelligence artificielle clinique, sûreté diagnostique, ChatGPT en médecine