Clear Sky Science · it
Asimmetria degli errori strutturali e analisi pesata per danno di ChatGPT rispetto ai medici di terapia intensiva nell’interpretazione degli equilibri acido–base: uno studio osservazionale prospettico
Perché questo studio interessa i lettori comuni
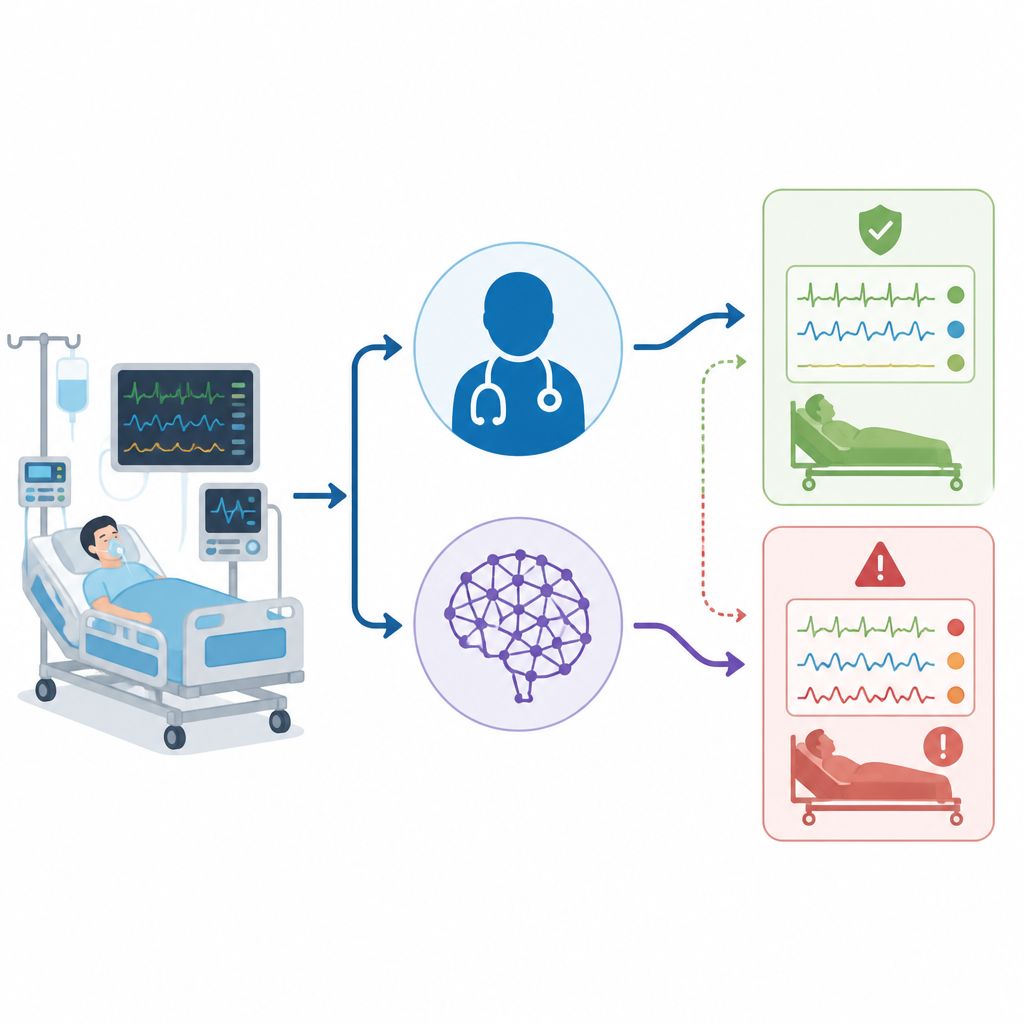
Gli ospedali stanno sperimentando sempre più l’intelligenza artificiale per aiutare i medici nelle decisioni, soprattutto nelle affollate unità di terapia intensiva. Questo studio pone una domanda semplice ma cruciale: quando un programma come ChatGPT aiuta a interpretare un esame del sangue molto delicato che guida trattamenti salvavita, i suoi errori sono altrettanto sicuri di quelli commessi da medici esperti della TI, o potrebbero celare seri problemi?
L’esame ematico al centro della storia
La ricerca si concentra sui gas arteriosi, che misurano quanto il sangue è acido e quanto bene il paziente respira e ossigena. In terapia intensiva, questi risultati aiutano i medici a decidere se regolare un ventilatore, somministrare liquidi o cambiare farmaci. I quadri possono essere semplici, come un unico problema respiratorio o metabolico, oppure complessi, con più alterazioni presenti contemporaneamente. Questi schemi “misti” sono comuni nei pazienti molto gravi e possono indicare che l’organismo è in difficoltà su più fronti.
Come è stato condotto il confronto diretto
Il gruppo ha raccolto dati da 50 pazienti adulti reali in terapia intensiva di un singolo ospedale, usando solo il primo gas arterioso idoneo di ciascuno. Per ogni paziente è stata creata una breve storia clinica che includeva i valori del gas e altri elementi chiave come segni vitali, funzione d’organo e supporto ventilatorio. Tre entità hanno quindi interpretato ogni caso in modo indipendente: i medici di terapia intensiva al letto del paziente, ChatGPT usando un prompt fisso in inglese, e un pannello di esperti separato che ha fornito la diagnosi “gold standard”. Tutte le interpretazioni sono state poi ricondotte a sei categorie semplici, compreso lo stato normale, quattro tipi di alterazione di base e una categoria mista con più problemi contemporanei.
Guardare oltre il semplice giusto o sbagliato
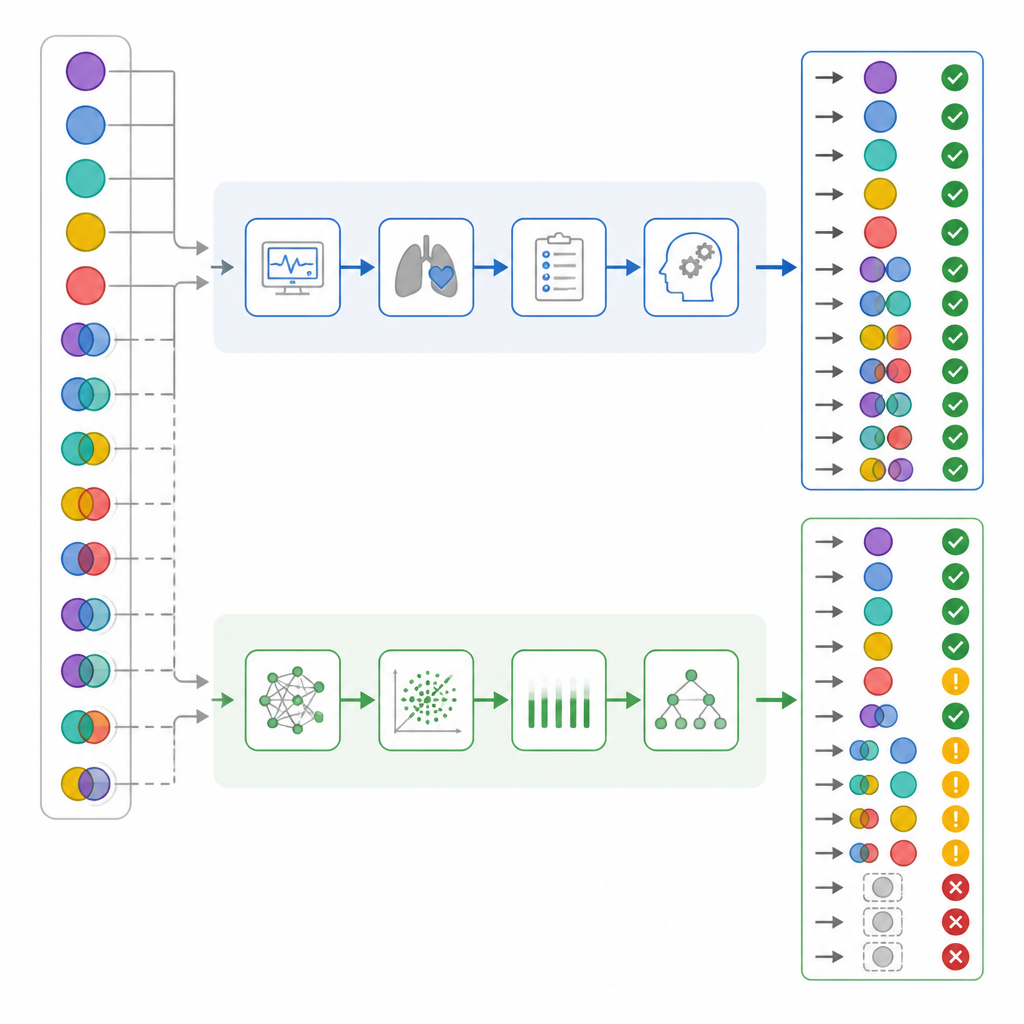
Quando i ricercatori hanno considerato solo la correttezza complessiva, i numeri sembravano abbastanza vicini: i medici della TI avevano ragione nell’82% dei casi, mentre ChatGPT nel 72%. Le statistiche standard di concordanza suggerivano che entrambi avevano performance in un range “sostanziale”. Ma il team ha poi approfondito il modo in cui ciascuno sbagliava, non solo la frequenza. Hanno separato i casi semplici da quelli misti, verificato quanto bene ogni interprete individuava le componenti respiratorie rispetto a quelle metaboliche, e creato un “punteggio di danno” che attribuiva ad alcuni errori un peso maggiore. In questo sistema, classificare come “normale” un caso realmente complesso aveva il peso più alto, perché potrebbe indurre il personale in una falsa sensazione di sicurezza.
Differenze nascoste nei casi complessi e rischiosi
Una volta analizzati i risultati per complessità, sono emersi contrasti importanti. Quasi la metà dei pazienti presentava effettivamente problemi acido–base misti. I medici della TI li hanno riconosciuti correttamente in quasi tutti i casi, mentre ChatGPT ne ha mancati più di un terzo. In circa un sesto dei casi misti, ChatGPT ha addirittura etichettato lo stato ematico come normale, un comportamento che gli autori hanno definito “falsa rassicurazione”, che i medici non hanno mai mostrato. Uno sguardo più attento alle componenti respiratorie e metaboliche separate suggerisce che ChatGPT era più propenso a trascurare la componente respiratoria della alterazione. Applicando il sistema di punteggio per il danno, gli errori di ChatGPT avevano un danno medio significativamente più elevato rispetto a quelli dei medici della TI, nonostante la sovrapposizione nella precisione complessiva.
Cosa significa per l’uso dell’IA nelle cure critiche
Per un lettore non specialista, il messaggio principale è che una precisione simile a livello globale non implica che uno strumento di IA si comporti come un medico nei punti che contano di più. In questo campione reale di terapia intensiva, ChatGPT ha spesso classificato bene i quadri comuni, ma ha avuto più difficoltà con i problemi misti e intrecciati che segnalano malattie gravi e richiedono azioni rapide. Poiché il personale non può sempre sapere in anticipo quali casi sono semplici e quali complessi, e gli strumenti di IA attuali non avvertono in modo affidabile quando sono incerti, gli autori sostengono che ChatGPT non dovrebbe sostituire il giudizio del medico per queste decisioni sui gas ematici. Suggeriscono invece che i futuri test delle IA mediche dovrebbero concentrarsi meno sui risultati complessivi e più su quanto spesso il sistema manca situazioni pericolose, su come gestisce la complessità e su quanto dannose potrebbero essere le sue errori per i pazienti.
Citazione: Gulen, D., Gözden, H.E., Ekin, S. et al. Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study. Sci Rep 16, 15184 (2026). https://doi.org/10.1038/s41598-026-44576-4
Parole chiave: terapia intensiva, interpretazione dei gas ematici, intelligenza artificiale clinica, sicurezza diagnostica, ChatGPT in medicina