Clear Sky Science · en
Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study
Why this study matters to everyday readers
Hospitals increasingly experiment with artificial intelligence to help doctors make decisions, especially in crowded intensive care units. This study asks a simple but vital question: when a computer program like ChatGPT helps interpret a very delicate blood test that guides life-saving treatment, are its mistakes as safe as those made by experienced ICU doctors, or could they quietly hide serious trouble?
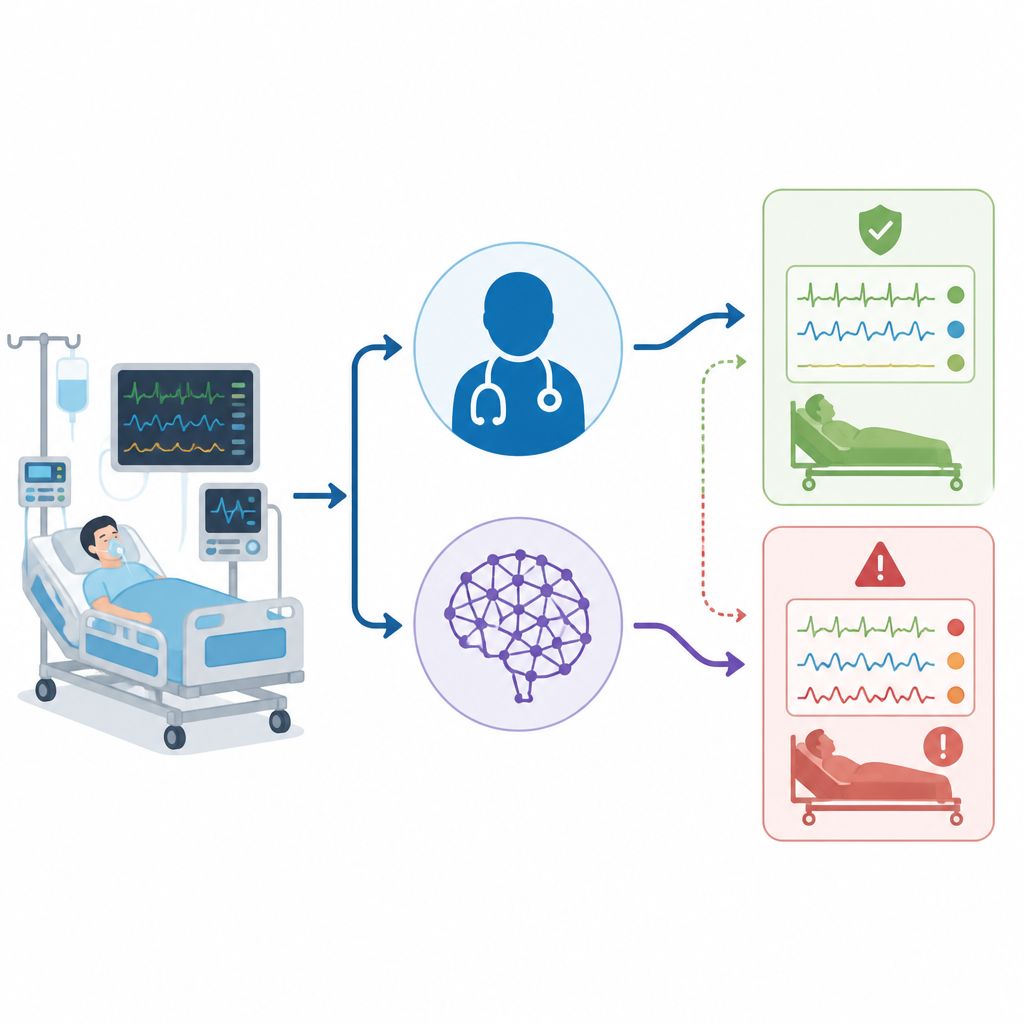
The blood test at the heart of the story
The research focuses on arterial blood gas tests, which measure how acidic the blood is and how well a patient is breathing and getting oxygen. In the ICU, these results help doctors decide whether to adjust a ventilator, give fluids, or change medicines. The patterns can be simple, such as one main problem with breathing or metabolism, or complex, with several problems occurring at once. These “mixed” patterns are common in very sick patients and can signal that the body is struggling on several fronts at the same time.
How the head to head comparison was done
The team collected data from 50 real adult ICU patients in a single hospital, using only the first qualifying blood gas test from each person. For every patient, they created a short clinical story that included the blood gas numbers and other key details such as vital signs, organ function, and breathing support. Three groups then interpreted each case independently: the bedside ICU physicians, ChatGPT using a fixed English prompt, and a separate expert panel that provided the final “gold standard” diagnosis. All interpretations were later sorted into six simple groups, including normal status, four basic disturbance types, and a mixed category where more than one problem was present.
Looking beyond simple right or wrong
When the researchers looked only at overall correctness, the numbers seemed fairly close: ICU doctors were right in 82 percent of cases, while ChatGPT was right in 72 percent. Standard agreement statistics suggested that both performed in a “substantial” range. But the team then dug deeper into how each side was wrong, not just how often. They separated simple from mixed cases, checked how well each interpreter spotted breathing versus metabolic components, and created a “harm score” that counted some mistakes as more dangerous than others. In this system, calling a truly complex case “normal” carried the highest weight, because it might lull staff into a false sense of security.
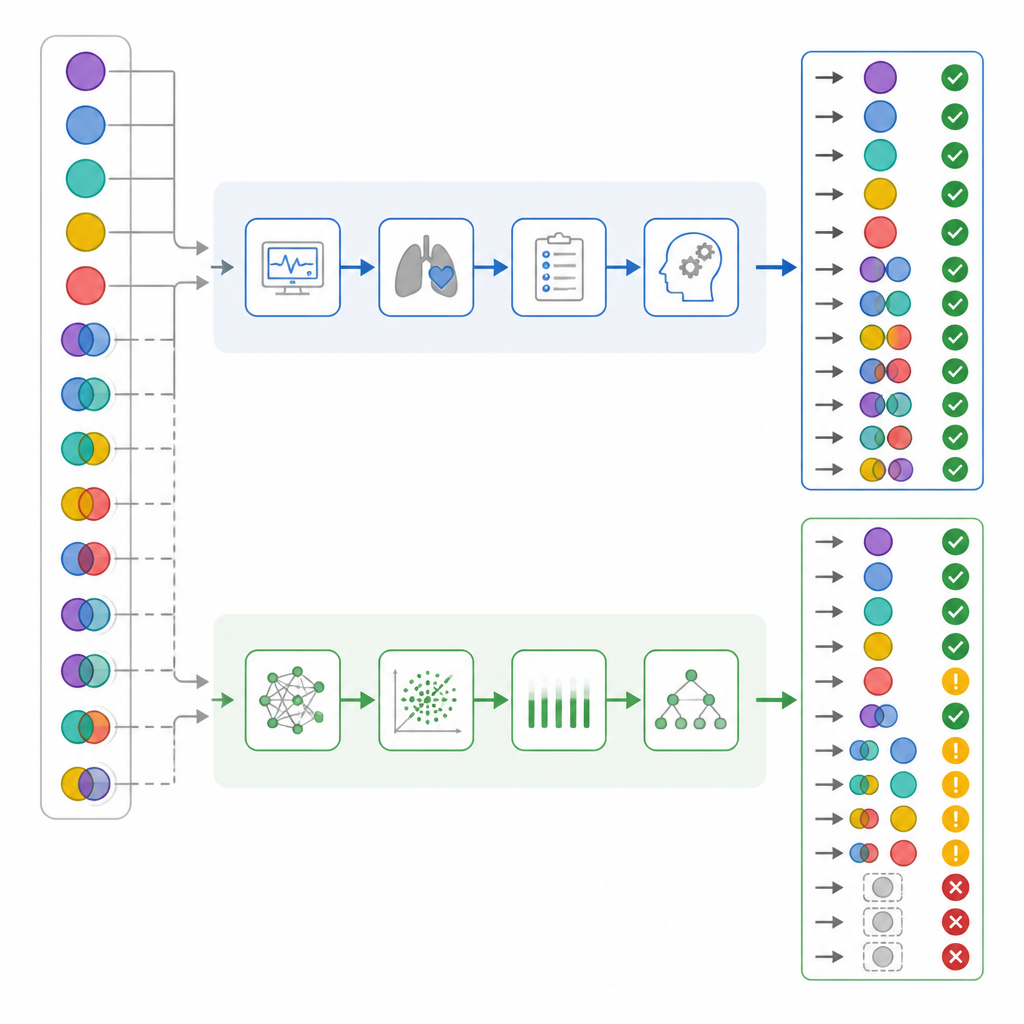
Hidden differences in complex and risky cases
Once results were broken down by complexity, important contrasts appeared. Nearly half of the patients actually had mixed acid base problems. ICU physicians correctly recognized these in almost all cases, while ChatGPT missed more than one third of them. In about one sixth of the mixed cases, ChatGPT even labeled the blood status as normal, a pattern the authors called “false reassurance,” which the doctors never showed. A closer look at separate breathing and metabolic components suggested that ChatGPT was more likely to overlook the breathing part of the disturbance. When the harm scoring system was applied, ChatGPT’s errors carried a significantly higher average harm than those of the ICU doctors, even though their overall accuracy overlapped.
What this means for using AI in critical care
For a lay reader, the main message is that similar headline accuracy does not mean an AI tool behaves like a doctor where it matters most. In this real world ICU sample, ChatGPT could often classify common patterns well, but it struggled more with the tangled, mixed problems that signal severe illness and require rapid action. Because staff cannot always tell in advance which cases are simple and which are complex, and current AI tools do not reliably warn when they are uncertain, the authors argue that ChatGPT should not replace physician judgment for these blood gas decisions. Instead, they suggest that future tests of medical AI should focus less on overall scorecards and more on how often the system misses dangerous situations, how it handles complexity, and how harmful its mistakes could be for patients.
Citation: Gulen, D., Gözden, H.E., Ekin, S. et al. Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study. Sci Rep 16, 15184 (2026). https://doi.org/10.1038/s41598-026-44576-4
Keywords: intensive care, blood gas interpretation, clinical artificial intelligence, diagnostic safety, ChatGPT in medicine