Clear Sky Science · ru
Асимметрия структурных ошибок и анализ с учётом вреда: ChatGPT против врачей отделения интенсивной терапии в интерпретации кислотно‑щелочного статуса: проспективное наблюдательное исследование
Почему это исследование важно для широкой публики
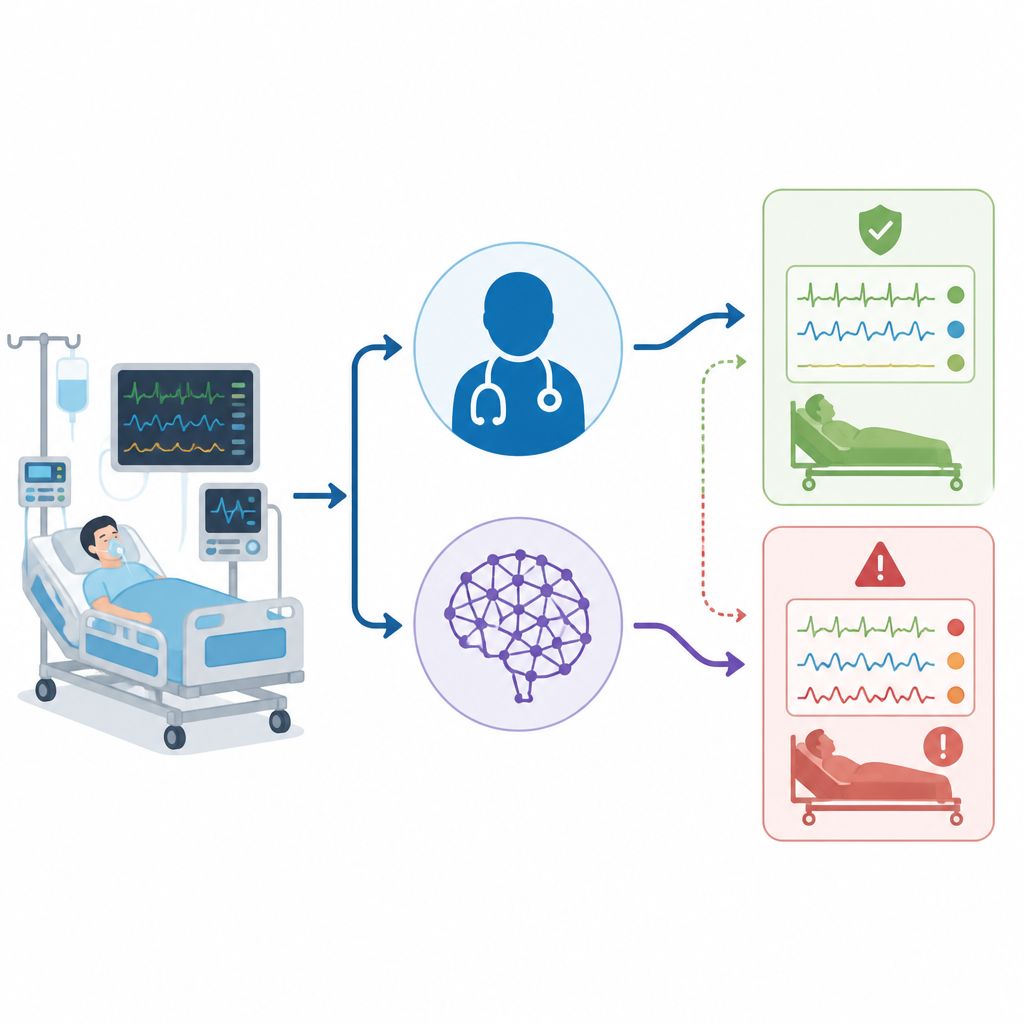
Больницы всё чаще испытывают искусственный интеллект, чтобы помогать врачам принимать решения, особенно в переполненных отделениях интенсивной терапии. Это исследование задаёт простой, но ключевой вопрос: когда компьютерная программа вроде ChatGPT помогает интерпретировать очень деликатный анализ крови, который направляет спасительную терапию, настолько ли безопасны её ошибки по сравнению с ошибками опытных реанимационных врачей, или они могут незаметно скрывать серьёзную опасность?
Анализ крови в центре внимания
Исследование сосредоточено на анализах артериальных газов крови, которые измеряют кислотность крови и то, насколько хорошо пациент дышит и получает кислород. В отделении интенсивной терапии эти результаты помогают врачам решить, стоит ли настраивать аппарат ИВЛ, ввести жидкости или изменить лекарства. Ситуации могут быть простыми — с одной основной проблемой дыхания или метаболизма — или сложными, когда одновременно присутствует несколько нарушений. Такие «смешанные» паттерны часто встречаются у очень больных пациентов и могут указывать на то, что организм испытывает трудности по нескольким направлениям одновременно.
Как проводилось очное сравнение
Команда собрала данные у 50 реальных взрослых пациентов отделения интенсивной терапии в одной больнице, используя только первый подходящий анализ газов крови у каждого человека. Для каждого пациента составили краткую клиническую историю, включающую числа газов крови и другие ключевые детали, такие как жизненные показатели, функция органов и поддержка дыхания. Затем три группы независимо интерпретировали каждый случай: дежурные врачи реанимации у постели больного, ChatGPT, работавший по фиксированному английскому запросу, и отдельная экспертная панель, давшая окончательный «золотой стандарт» диагноза. Все интерпретации позже распределили по шести простым категориям: нормальное состояние, четыре базовых типа нарушений и категория «смешанное», где присутствовало более одной проблемы.
Смотрим дальше, чем просто правильно или неправильно
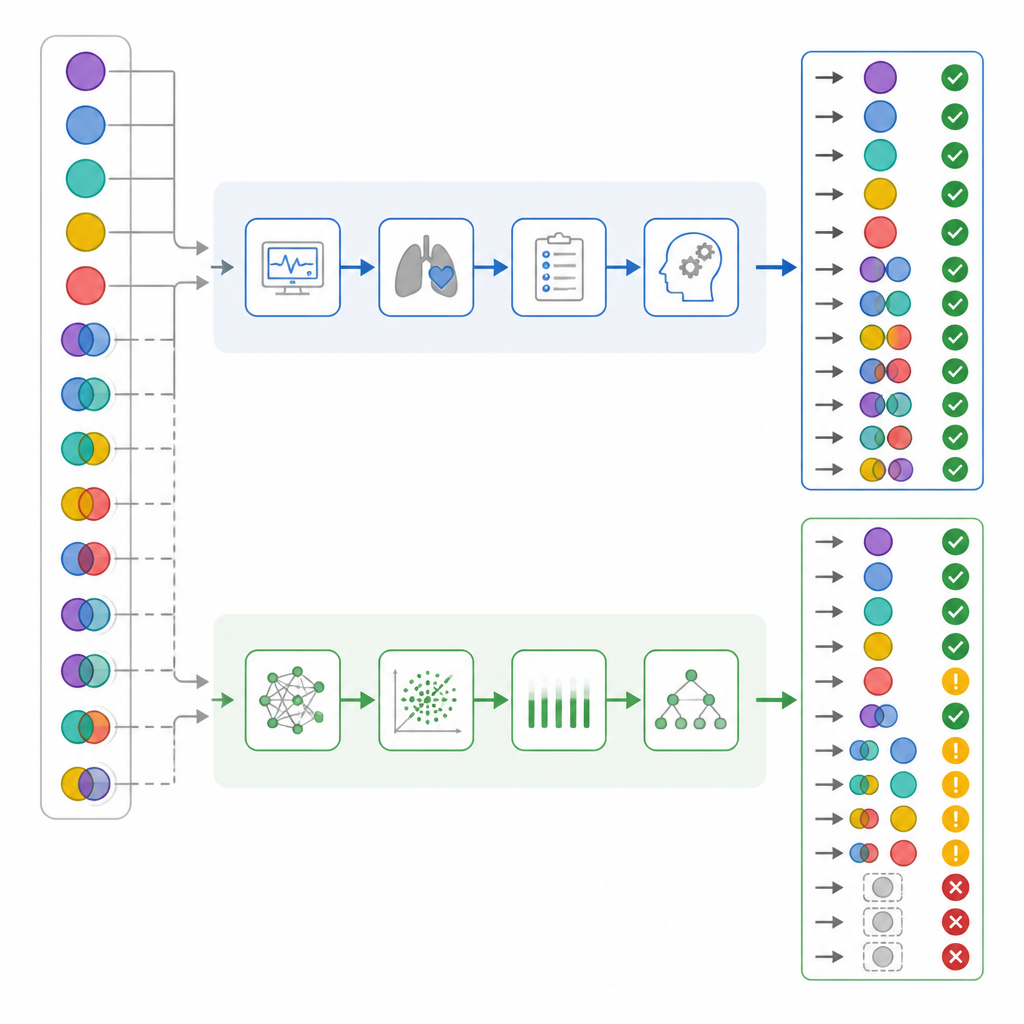
Когда исследователи учитывали только общую правильность, цифры казались довольно близкими: врачи ИТ были правы в 82 процентах случаев, а ChatGPT — в 72 процентах. Стандартные статистики согласия указывали, что оба участника работали в «существенном» диапазоне. Но команда затем углубилась в то, как именно каждая сторона ошибалась, а не только как часто. Они разделили простые и смешанные случаи, проверили, насколько хорошо каждая сторона выявляла дыхательную и метаболическую составляющие, и создали «оценку вреда», в которой некоторые ошибки считались более опасными, чем другие. В этой системе обозначение действительно сложного случая как «нормального» имело наивысший вес, потому что это могло ввести персонал в ложное чувство безопасности.
Скрытые различия в сложных и рискованных случаях
Когда результаты разбили по сложности, выявились важные различия. Почти у половины пациентов действительно были смешанные кислотно‑щелочные нарушения. Врачи реанимации правильно распознали их почти во всех случаях, тогда как ChatGPT пропустил более одной трети таких случаев. Примерно в одной шестой смешанных случаев ChatGPT даже классифицировал статус крови как нормальный — паттерн, который авторы назвали «ложным успокоением», и который врачи не демонстрировали. При внимательном рассмотрении отдельных дыхательной и метаболической составляющих выяснилось, что ChatGPT чаще упускал дыхательную компоненту нарушения. После применения системы оценки вреда ошибки ChatGPT имели значительно более высокий средний уровень потенциального вреда по сравнению с ошибками врачей ИТ, несмотря на перекрывающуюся общую точность.
Что это значит для использования ИИ в критической помощи
Для неспециалиста главный вывод таков: схожая показательная точность не означает, что инструмент ИИ ведёт себя как врач там, где это важно. В этой выборке реального отделения интенсивной терапии ChatGPT часто корректно классифицировал распространённые паттерны, но хуже справлялся с запутанными смешанными нарушениями, которые сигнализируют о тяжёлой болезни и требуют быстрого вмешательства. Поскольку персонал не всегда может заранее отличить простые случаи от сложных, а текущие инструменты ИИ не дают надёжных предупреждений о своей неопределённости, авторы утверждают, что ChatGPT не должен заменять врачебное суждение при решениях на основе газов крови. Вместо этого они предлагают, чтобы будущие испытания медицинского ИИ уделяли меньше внимания общим табличным оценкам и больше — тому, как часто система пропускает опасные ситуации, как она справляется со сложностью и насколько вредны её ошибки для пациентов.
Цитирование: Gulen, D., Gözden, H.E., Ekin, S. et al. Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study. Sci Rep 16, 15184 (2026). https://doi.org/10.1038/s41598-026-44576-4
Ключевые слова: интенсивная терапия, интерпретация газов крови, клинический искусственный интеллект, диагностическая безопасность, ChatGPT в медицине