Clear Sky Science · pt
Assimetria de erro estrutural e análise ponderada por dano do ChatGPT versus médicos de UTI na interpretação ácido–base: um estudo observacional prospectivo
Por que este estudo importa para leitores comuns
Hospitais têm experimentado cada vez mais com inteligência artificial para ajudar médicos a tomar decisões, especialmente em unidades de terapia intensiva lotadas. Este estudo faz uma pergunta simples, porém vital: quando um programa de computador como o ChatGPT ajuda a interpretar um exame sanguíneo muito delicado que orienta tratamentos que salvam vidas, seus erros são tão seguros quanto os cometidos por médicos experientes de UTI, ou poderiam ocultar silenciosamente problemas graves?
O exame de sangue no centro da história
A pesquisa foca em gasometrias arteriais, que medem quão ácido está o sangue e o quão bem o paciente está respirando e recebendo oxigênio. Na UTI, esses resultados ajudam os médicos a decidir se ajustam o ventilador, administram fluidos ou trocam medicamentos. Os padrões podem ser simples, como um problema predominante respiratório ou metabólico, ou complexos, com vários distúrbios ocorrendo ao mesmo tempo. Esses padrões “mistos” são comuns em pacientes muito doentes e podem indicar que o corpo está sob esforço em várias frentes simultaneamente.
Como foi feita a comparação direta
A equipe coletou dados de 50 pacientes adultos reais de UTI em um único hospital, usando apenas a primeira gasometria que atendia aos critérios de cada pessoa. Para cada paciente, criaram um breve relato clínico que incluía os números da gasometria e outros detalhes-chave, como sinais vitais, função de órgãos e suporte respiratório. Três grupos então interpretaram cada caso de forma independente: os médicos de UTI à beira do leito, o ChatGPT usando um prompt em inglês fixo, e um painel de especialistas separado que forneceu o diagnóstico “padrão-ouro” final. Todas as interpretações foram depois agrupadas em seis categorias simples, incluindo estado normal, quatro tipos básicos de distúrbio e uma categoria mista onde havia mais de um problema presente.
Olhar além do certo ou errado simples
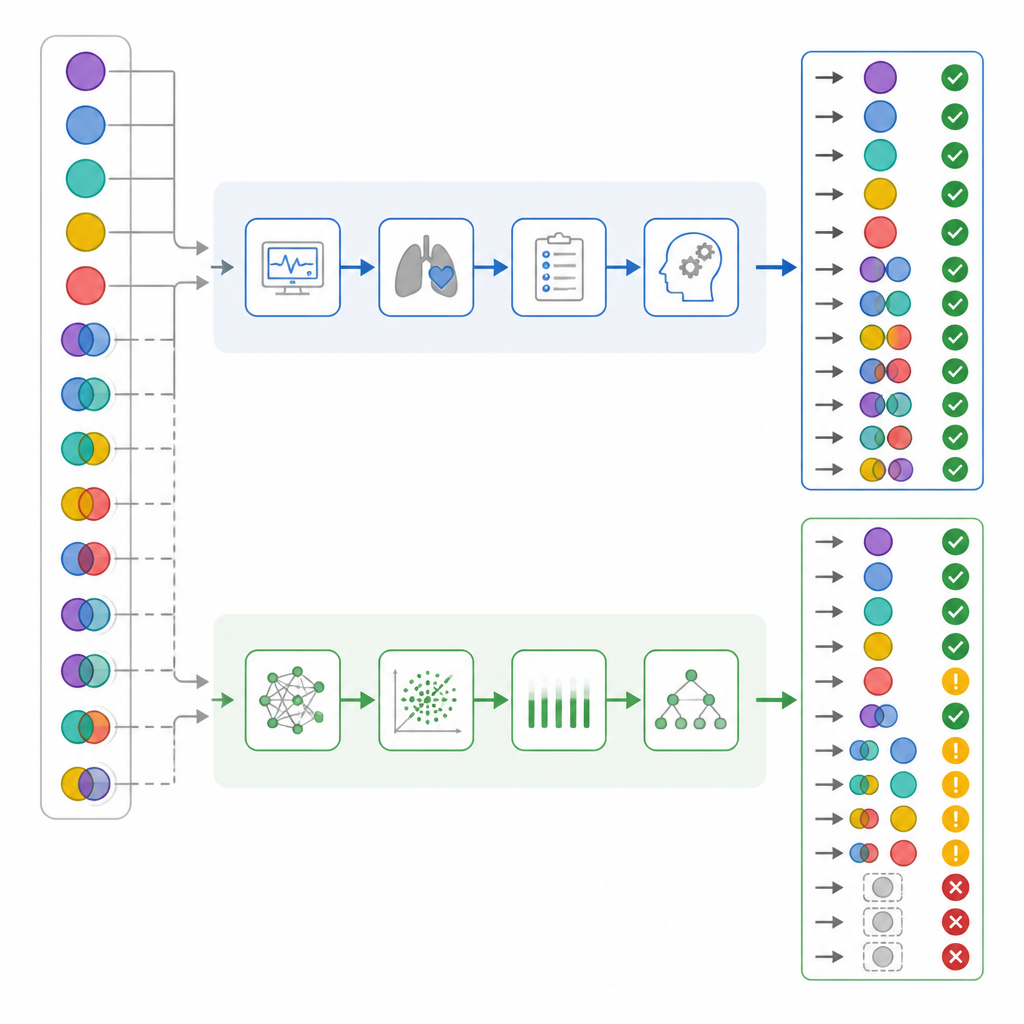
Quando os pesquisadores consideraram apenas a correção global, os números pareciam relativamente próximos: os médicos de UTI acertaram 82% dos casos, enquanto o ChatGPT acertou 72%. Estatísticas padrão de concordância sugeriram que ambos atuaram em uma faixa “substancial”. Mas a equipe foi além e analisou como cada um errou, não apenas com que frequência. Separaram casos simples dos mistos, verificaram quão bem cada intérprete detectou componentes respiratórios versus metabólicos, e criaram uma “pontuação de dano” que contou alguns erros como mais perigosos que outros. Nesse sistema, rotular um caso realmente complexo como “normal” teve o peso mais alto, porque poderia induzir a equipe a uma falsa sensação de segurança.
Diferenças ocultas em casos complexos e de risco
Quando os resultados foram estratificados por complexidade, apareceram contrastes importantes. Quase metade dos pacientes tinha, de fato, problemas ácido–base mistos. Os médicos de UTI reconheceram corretamente esses casos em quase todos os exemplos, enquanto o ChatGPT deixou passar mais de um terço deles. Em cerca de um sexto dos casos mistos, o ChatGPT rotulou o estado sanguíneo como normal — um padrão que os autores chamaram de “falsa tranquilidade”, que os médicos nunca demonstraram. Uma análise mais detalhada dos componentes respiratórios e metabólicos separadamente sugeriu que o ChatGPT tinha maior probabilidade de não detectar a componente respiratória da perturbação. Quando o sistema de pontuação de dano foi aplicado, os erros do ChatGPT apresentaram, em média, um dano significativamente maior que os dos médicos de UTI, mesmo que a precisão global se sobrepusesse.
O que isso significa para o uso de IA em cuidados críticos
Para um leitor leigo, a mensagem principal é que precisão semelhante em manchetes não significa que uma ferramenta de IA se comporte como um médico onde isso mais importa. Nesta amostra de UTI do mundo real, o ChatGPT classificou bem padrões comuns com frequência, mas teve mais dificuldade com os problemas mistos e intrincados que sinalizam doença grave e exigem ação rápida. Como a equipe nem sempre pode saber de antemão quais casos são simples e quais são complexos, e ferramentas de IA atuais não avisam de forma confiável quando estão incertas, os autores argumentam que o ChatGPT não deve substituir o julgamento médico nessas decisões sobre gasometrias. Em vez disso, sugerem que futuros testes de IA médica deem menos ênfase a placares gerais e mais atenção a com que frequência o sistema perde situações perigosas, como lida com complexidade e quão prejudiciais seus erros podem ser para os pacientes.
Citação: Gulen, D., Gözden, H.E., Ekin, S. et al. Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study. Sci Rep 16, 15184 (2026). https://doi.org/10.1038/s41598-026-44576-4
Palavras-chave: terapia intensiva, interpretação de gasometria, inteligência artificial clínica, segurança diagnóstica, ChatGPT na medicina