Clear Sky Science · tr
Yapısal hata asimetrisi ve zarar-ağırlıklı analiz: ChatGPT ile YBÜ Hekimleri arasında asit–baz yorumlaması karşılaştırması — prospektif gözlemsel çalışma
Bu çalışmanın sıradan okuyucular için önemi
Hastaneler, özellikle kalabalık yoğun bakım ünitelerinde, hekimlere karar desteği sağlamak için giderek daha fazla yapay zekâyı deniyor. Bu çalışma basit fakat hayati bir soruyu soruyor: ChatGPT gibi bir bilgisayar programı hayat kurtaran tedavileri yönlendiren çok hassas bir kan testini yorumlarken yaptığı hatalar, deneyimli YBÜ hekimlerinin yaptığı hatalar kadar güvenli mi, yoksa ciddi sorunları sessizce saklayabilecek kadar riskli mi?
Hikâyenin merkezindeki kan testi
Araştırma, kanın asiditesini ve hastanın ne kadar iyi soluduğunu ve oksijen aldığı ölçen arteriyel kan gazı testlerine odaklanıyor. YBÜ’de bu sonuçlar hekimlere ventilatörü ayarlayıp ayarlamama, sıvı verip vermeme veya ilaçları değiştirme kararlarında yol gösterir. Desenler tek bir solunum veya metabolik soruna işaret eden basit olabilir ya da aynı anda birkaç sorunun bulunduğu karmaşık olabilir. Bu “karışık” desenler çok hasta hastalarda yaygındır ve vücudun aynı anda birkaç cephede mücadele ettiğinin işareti olabilir.
Karşılaştırma nasıl yapıldı
Araştırma ekibi, tek bir hastanede yatan 50 gerçek yetişkin YBÜ hastasından veri topladı ve her kişiden yalnızca ilk uygun kan gazı testini kullandı. Her hasta için kan gazı değerlerini ve hayati bulgular, organ fonksiyonları ve solunum desteği gibi diğer önemli ayrıntıları içeren kısa bir klinik öykü oluşturuldu. Üç grup daha sonra her vakayı bağımsız olarak yorumladı: yatak başı YBÜ hekimleri, sabit bir İngilizce istemle ChatGPT ve nihai “altın standart” tanıyı sağlayan ayrı bir uzman panel. Tüm yorumlar daha sonra normal durum, dört temel bozukluk tipi ve birden fazla sorunun bulunduğu karışık kategori dahil olmak üzere altı basit gruba ayrıldı.
Basit doğru/yanlışın ötesine bakmak
Araştırmacılar yalnızca genel doğruluğa baktıklarında rakamlar birbirine oldukça yakın görünüyordu: YBÜ hekimleri vakaların yüzde 82’sinde doğruyken, ChatGPT yüzde 72’de doğruydu. Standart uyum istatistikleri her ikisinin de “önemli” bir aralıkta performans gösterdiğini düşündürdü. Ancak ekip, ne sıklıkla yanlış olduklarına değil nasıl yanlış olduklarına daha derinlemesine baktı. Basit vakaları karışık olanlardan ayırdılar, her yorumcunun solunum ve metabolik bileşenleri ne kadar iyi gördüğünü kontrol ettiler ve bazı hataları diğerlerinden daha tehlikeli sayan bir “zarar skoru” oluşturdular. Bu sistemde gerçekten karmaşık bir vakayı “normal” olarak nitelendirmek en yüksek ağırlığa sahipti; çünkü bu, personeli yanlış bir güven duygusuna sokabilirdi.
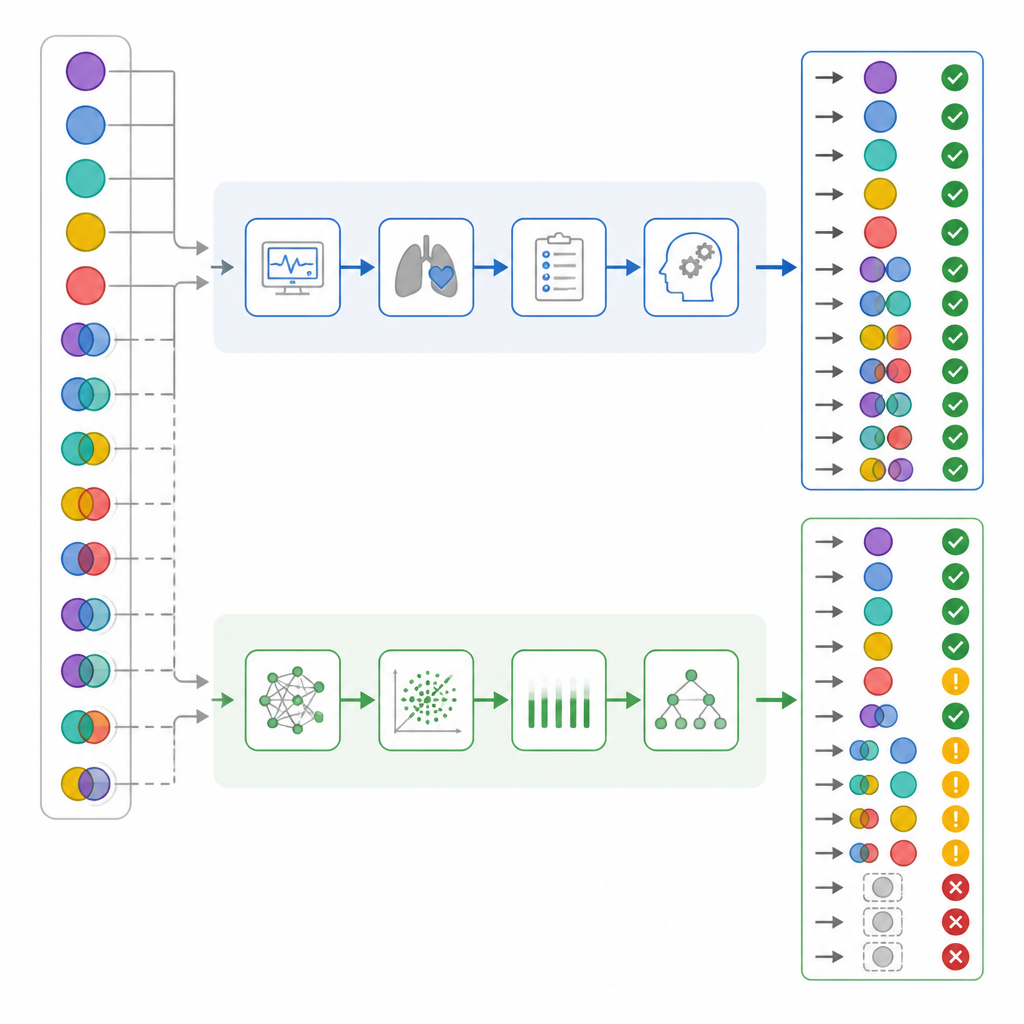
Karmaşık ve riskli vakalardaki gizli farklar
Sonuçlar karmaşıklığa göre ayrıldığında önemli farklılıklar ortaya çıktı. Hastaların neredeyse yarısında gerçekte karışık asit–baz sorunları vardı. YBÜ hekimleri bunları neredeyse tüm vakalarda doğru şekilde tanırken, ChatGPT bunların üçte birinden fazlasını kaçırdı. Karışık vakaların yaklaşık altıda birinde ChatGPT kan durumunu normal olarak etiketledi; yazarların “yanlış yatıştırma” dediği bu desen, hekimlerde hiç görülmedi. Ayrı solunum ve metabolik bileşenlere daha yakından bakıldığında ChatGPT’nin bozukluğun solunum bölümünü göz ardı etme olasılığının daha yüksek olduğu görüldü. Zarar puanlama sistemi uygulandığında, ChatGPT’nin hatalarının ortalama zararı, genel doğrulukları örtüşse bile YBÜ hekimlerinin hatalarından anlamlı olarak daha yüksekti.
Yoğun bakımda yapay zekâ kullanımı için ne anlama geliyor
Bir genel okuyucu için ana mesaj şudur: benzer başlık doğruluğu, bir yapay zekâ aracının en çok önemli olan yerlerde bir doktor gibi davrandığı anlamına gelmez. Bu gerçek dünya YBÜ örnekleminde ChatGPT sık görülen desenleri çoğunlukla sınıflandırabilse de, ağır hastalığı işaret eden ve hızlı müdahale gerektiren iç içe geçmiş karışık sorunlarda daha çok güçlük çekti. Personel hangi vakaların basit, hangilerinin karmaşık olduğunu her zaman önceden söyleyemeyeceği ve mevcut yapay zekâ araçları ne zaman şüpheli olduklarını güvenilir şekilde uyarmadığı için yazarlar ChatGPT’nin bu kan gazı kararlarında hekim yargısının yerini almaması gerektiğini savunuyor. Bunun yerine, tıbbi yapay zekânın gelecekteki testlerinin genel puan tablolarından ziyade sistemin ne sıklıkla tehlikeli durumları gözden kaçırdığı, karmaşıklığı nasıl ele aldığı ve hatalarının hastalar için ne kadar zararlı olabileceği üzerinde daha fazla yoğunlaşması gerektiğini öneriyorlar.
Atıf: Gulen, D., Gözden, H.E., Ekin, S. et al. Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study. Sci Rep 16, 15184 (2026). https://doi.org/10.1038/s41598-026-44576-4
Anahtar kelimeler: yoğun bakım, kan gazı yorumlaması, klinik yapay zekâ, tanısal güvenlik, Tıpta ChatGPT